Scaling Law不總是適用!尤其在文本分類任務中,vivo AI Lab提出數據質量提升解決方法
vivo AI Lab 投稿
量子位 | 公眾號 QbitAI
Scaling Law不僅在放緩,而且不一定總是適用!
尤其在文本分類任務中,擴大訓練集的數據量可能會帶來更嚴重的數據衝突和數據冗餘。
要是類別界限不夠清晰,數據衝突現象就更明顯了。
而文本分類又在情感分析、識別用戶意圖等任務中極為重要,繼而對AI Agent的性能也有很大影響。
最近,vivo AI Lab研究團隊提出了一種數據質量提升(DQE)的方法,成功提升了LLM在文本分類任務中的準確性和效率。

實驗中,DQE方法以更少的數據獲得更高的準確率,並且只用了近一半的數據量,就能有效提升訓練集的訓練效率。
作者還對全量數據微調的模型和DQE選擇的數據微調的模型在測試集上的結果進行了顯著性分析。
結果發現DQE選擇的數據在大多數測試集上都比全量數據表現出顯著的性能提升。
目前,此項成果已被自然語言處理頂會COLING 2025主會接收。
數據質量提升方法長什麼樣?
在自然語言處理中,文本分類是一項十分重要的任務,比如情感分析、意圖識別等,尤其現在企業都在推出各自的AI Agent,其中最重要的環節之一,就是識別用戶的意圖。
不同於傳統的BERT模型,基於自回歸的大語言模型的輸出往往是不可控的,而分類任務對輸出的格式要求較高。
通過在提示詞中加入few-shot可以有效地改善這一現象,但是基於提示詞的方法帶來的提升往往有限。指令微調可以有效地改善模型的性能。
在文本分類任務中,缺乏一種有效的手段來獲取高質量的數據集。OpenAI提出了縮放定律(Scaling Law),認為大語言模型的最終性能主要取決於三個因素的縮放:計算能力、模型參數和訓練數據量。
然而這一定律並不總是適用,尤其在文本分類任務中,擴大訓練集的數據量會可能會帶來更加嚴重的數據衝突現象和數據冗餘問題。尤其類別的界限不夠清晰的時候,數據衝突的現象更加明顯。
下面是vivo AI Lab團隊提出的數據質量提升(DQE)方法的具體方法設計。
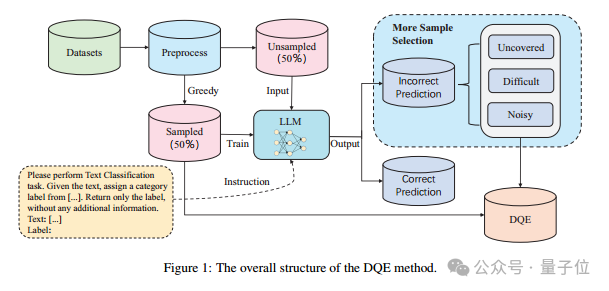
首先,作者對訓練集進行了初步的數據清洗工作,包含處理具有缺失值的數據、query和標籤重覆的數據以及標籤不一致數據(同一條query對應多個不同的標籤)。
然後,使用文本嵌入模型,將文本轉換為語義向量。再通過貪婪采樣的方法,隨機初始化一條數據作為初始向量,然後每次選擇距離向量中心最遠的數據加入到新的集合中,以提升數據的多樣性。
接著,更新這個集合的向量中心,不斷的重覆這個過程,直到收集了50%的數據作為sampled,剩下未被選中的50%的數據集作為unsampled,然後使用sampled數據集微調大語言模型預測unsampled。
通過結合向量檢索的方式,將unsampled中預測結果錯誤的數據分為Uncovered、Difficult和Noisy三種類型。
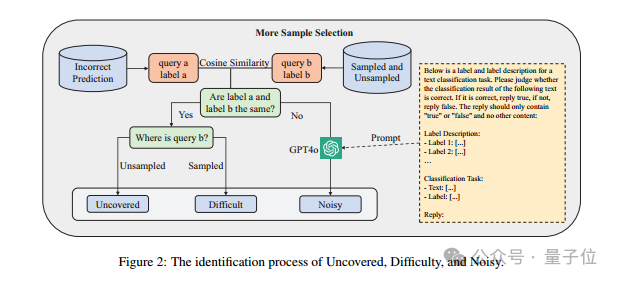
下面是三種類型的數據的識別原理:
Uncovered:主要指sampled中未覆蓋的數據,如果預測錯誤的數據與最相似的數據具有相同的標籤,並且最相似的數據位於unsampled中,則認為該數據相關的特徵可能沒有參與sampled模型的微調,從而導致unsampled中的該條預測結果錯誤。
Difficult:主要指sampled中難以學會的困難樣本,如果預測錯誤的數據與最相似的數據具有相同的標籤,並且最相似的數據位於sampled,則認為該數據相關的特徵已經在sampled中參與過模型的微調,預測錯誤可能是因為這條數據很難學會。
Noisy:主要是標籤不一致導致的噪聲數據,如果預測錯誤的數據與最相似的數據具有不同的標籤。則懷疑這兩條數據是噪聲數據。大多數文本分類任務的數據集都是共同手工標註或者模型標註獲得,都可能存在一定的主觀性,尤其在類別界限不清晰的時候,標註錯誤的現象無法避免。這種情況下,作者通過提示詞,使用GPT-4o進一步輔助判斷。
效果如何?
作者基於多機多卡的L40s服務器上通過swift框架進行了全參數微調,選擇開源的Qwen2.5-7B-Instruct模型作為本次實驗的基礎模型。
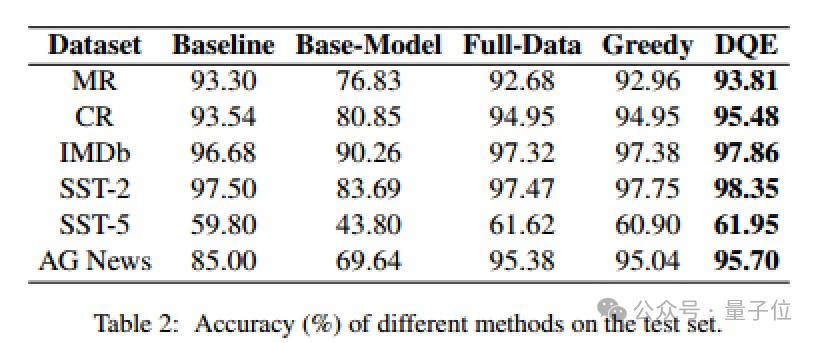
作者與PaperWithCode中收錄的最好的結果以及全量數據微調的方法進行了對比,作者分別在MR、CR、IMDb、SST-2、SST-5、AG News數據集中進行了對比實驗。
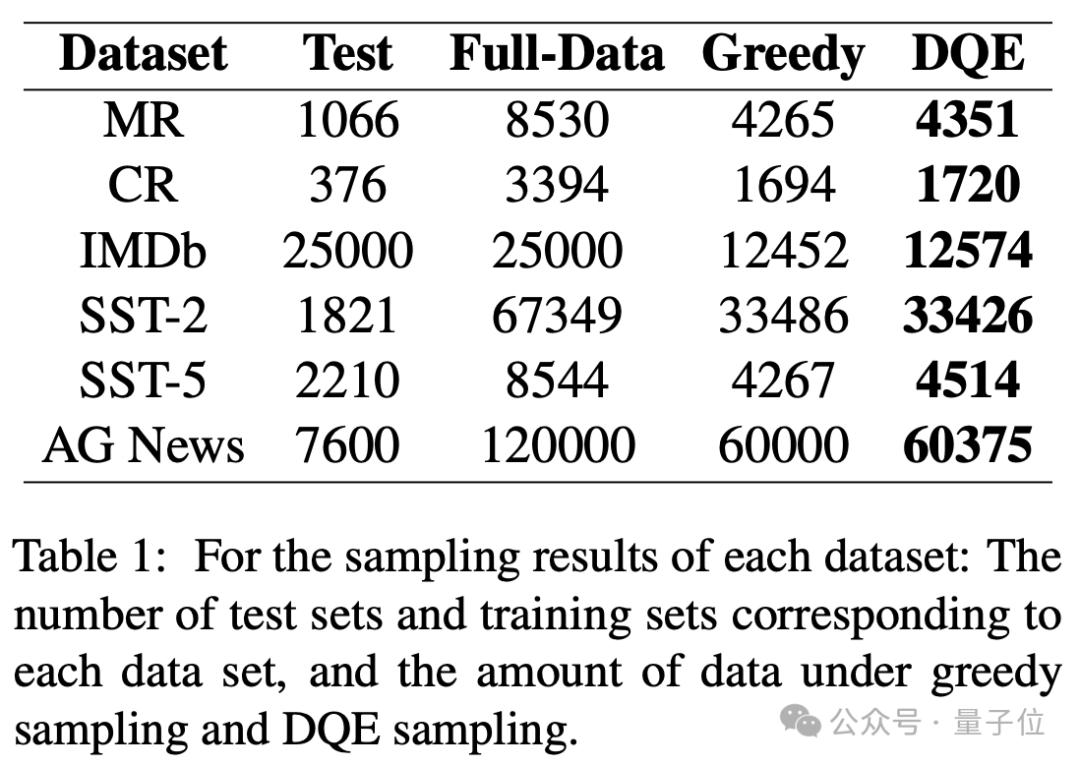
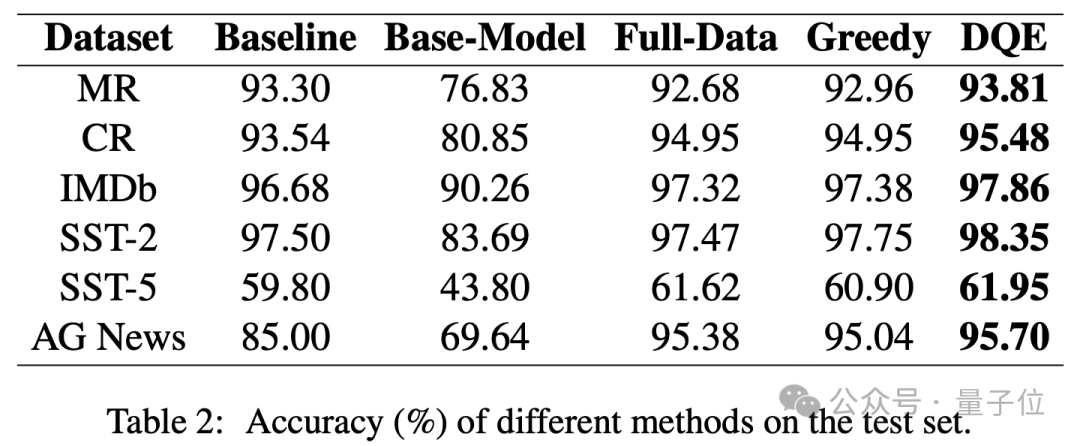
從實驗結果可以看出,DQE方法以更少的數據獲得更高的準確率,並且只用了近乎一半的數據量,可以有效地提升訓練集的訓練效率。
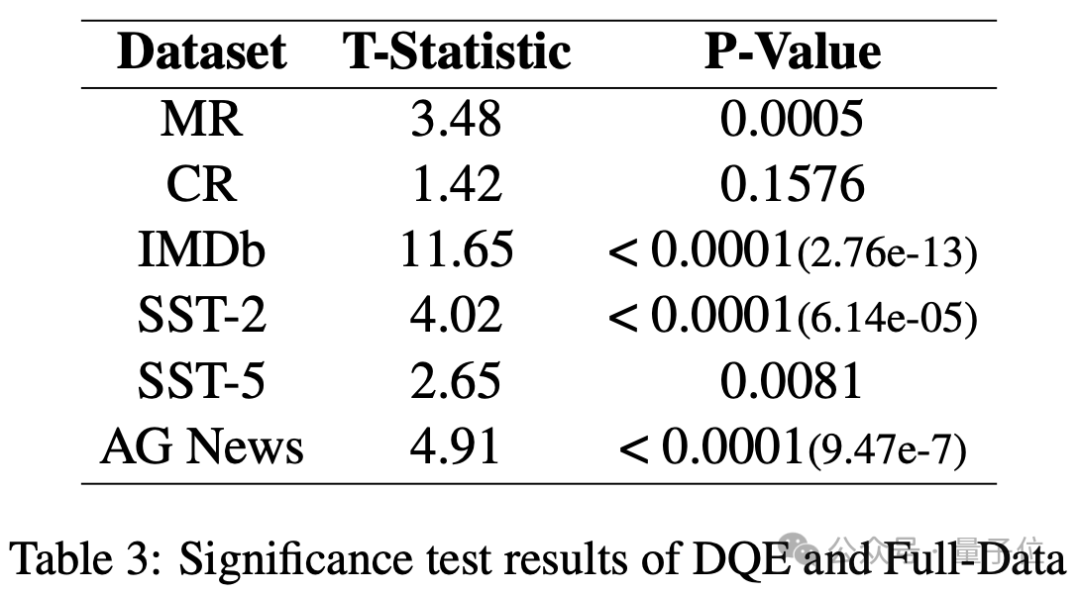
同時,作者頁進一步對全量數據微調的模型和DQE選擇的數據微調的模型在測試集上的結果進行了顯著性分析。將預測結果正確的數據賦值為1,將預測結果錯誤的數據賦值為0,通過t檢驗來評估模型之間性能差異的統計顯著性。
從表中可以發現DQE選擇的數據在大多數測試集上都比全量數據表現出顯著的性能提升。
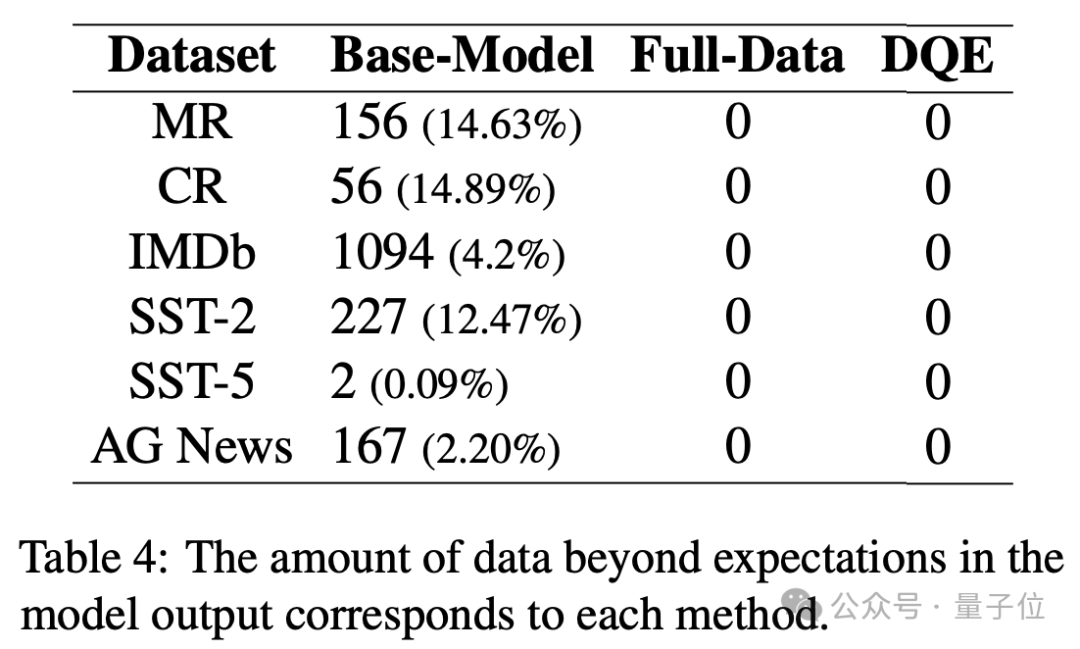
與傳統的BERT模型不同的是,生成式的模型往往是不可控的,作者進一步分析了指令跟隨結果。
結果表明,不管是全量數據微調還是DQE方法微調,都可以有效地提升大語言模型的指令跟隨能力,按照預期的結果和格式輸出。
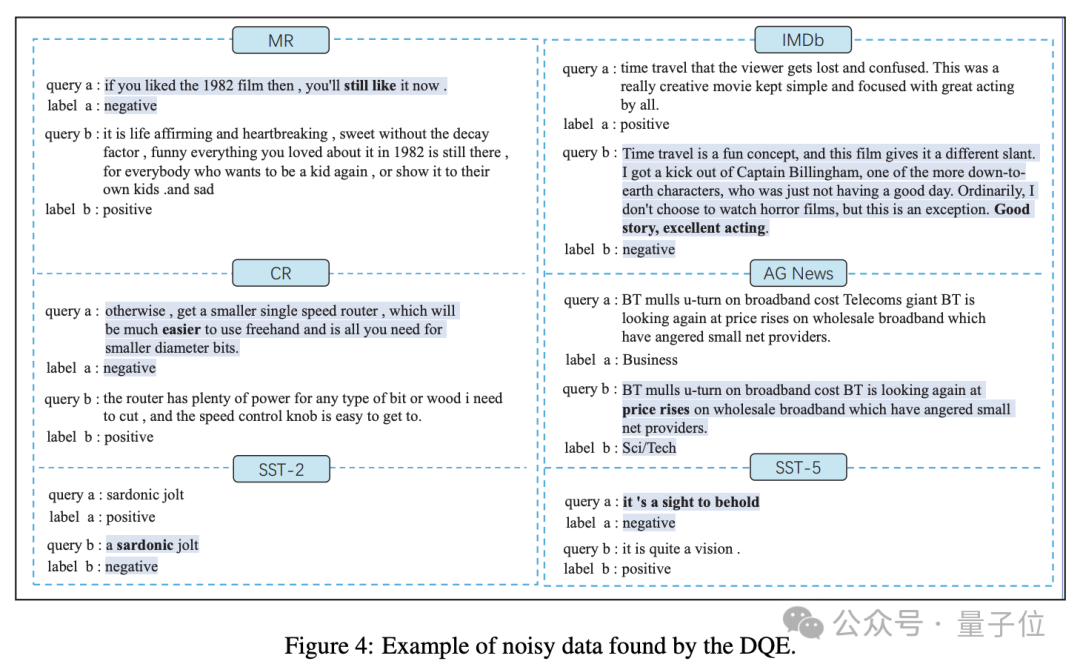
對於分類任務來講,當數據量足夠大時,很難避免標籤噪聲現象。即便是被各大頂級學術期刊和會議廣泛使用的數據集,也無法避免標籤噪聲現象。
作者分析了一部分通過實驗找出的噪聲數據,並且給出了開源數據集中的標籤噪聲的示例。
值得注意的是,在數據采樣過程中,本研究使用貪心算法將數據集劃分為sampled和unsampled。此外,作者根據文本相似度將unsampled分類為uncovered、difficult和noisy數據。
接下來,分析sampled中的這三種類型:
由於該數據將用於最終的訓練集,因此它不包含uncovered。
關於difficult,將來自unsampled中識別為difficult的樣本會加入到最終的訓練集,這uncovered中的difficult和sampled是成對存在的,從而部分減輕了采樣數據中的difficult問題。
對於noisy數據,使用DQE可以在sampled和unsampled之間識別出大多數成對的噪聲實例。
由於使用sampled貪婪采樣策略,在sampled內遇到成對的相似噪聲數據的概率會相對較低。從理論上解釋了本方案的有效性。
論文地址:https://arxiv.org/abs/2412.06575



















