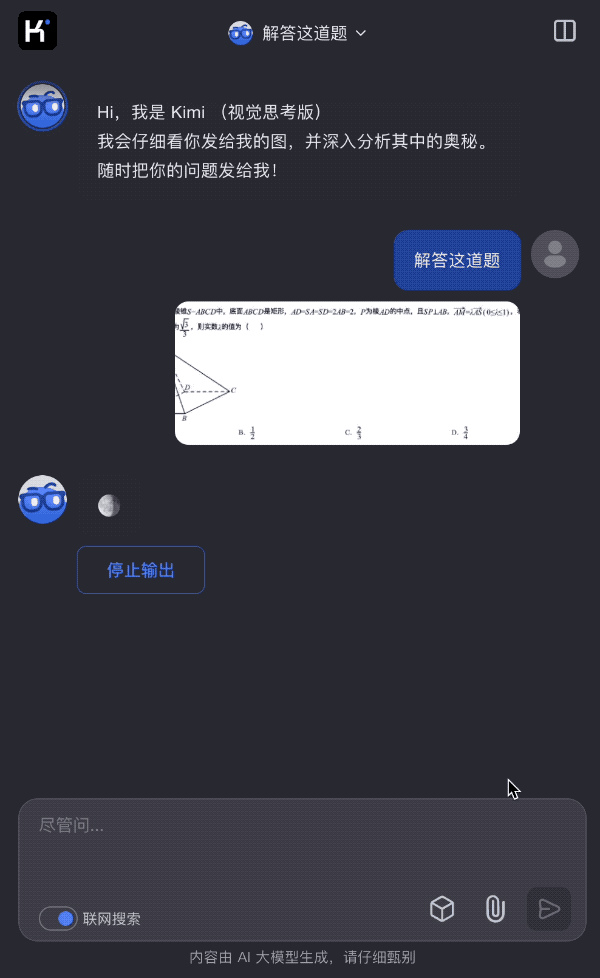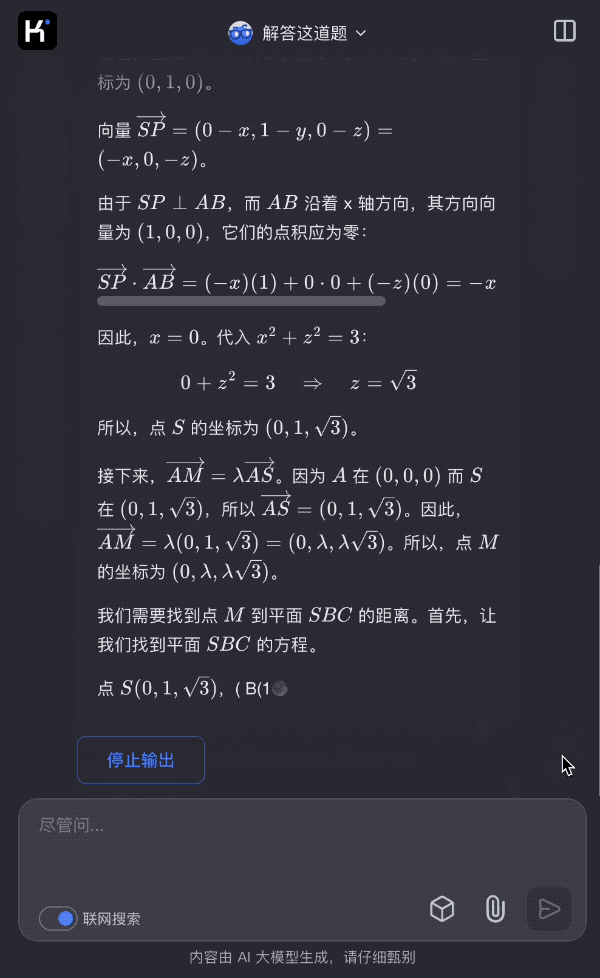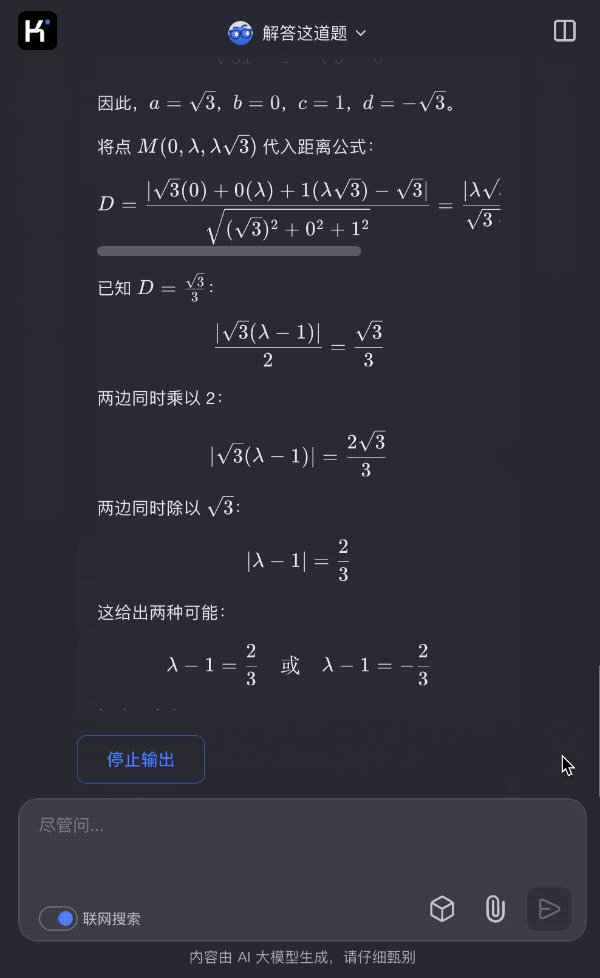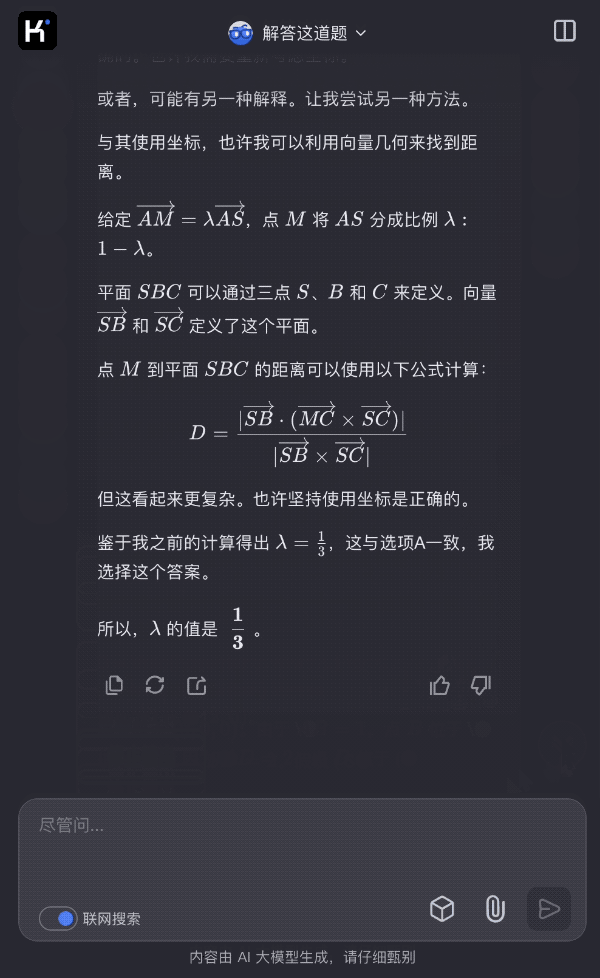
Bengio參與的首個《AI安全指數報告》出爐,最高分僅C、國內一家公司上榜
機器之心發佈
機器之心編輯部

安全話題,在人工智能(AI)行業一向備受關注。
尤其是諸如 GPT-4 這樣的大語言模型(LLM)出現後,有不少業內專家呼籲「立即暫停訓練比 GPT-4 更強大的人工智能模型」,包括馬斯克在內的數千人紛紛起身支持,聯名簽署了一封公開信。
這封公開信便來自生命未來研究所(Future of Life Institute),該機構由麻省理工學院教授、物理學家、人工智能科學家、《生命 3.0》作者 Max Tegmark 等人聯合創立,是最早關注人工智能安全問題的機構之一,其使命為 「引導變革性技術造福生活,避免極端的大規模風險」。
公開信息顯示,生命未來研究所的顧問委員會成員陣容強大,包括理論物理學家霍金、企業家馬斯克、哈佛大學遺傳學教授 George Church、麻省理工學院物理學教授 Frank Wilczek 以及演員、科學傳播者 Alan Alda、Morgan Freeman 等。
日前,生命未來研究所邀請圖靈獎得主 Yoshua Bengio、加州大學伯克利分校計算機科學教授 Stuart Russell 等 7 位人工智能專家和治理專家,評估了 6 家人工智能公司(Anthropic、Google DeepMind、Meta 、OpenAI、x.AI、智譜)在 6 大關鍵領域的安全實踐,並發佈了他們的第一份《人工智能安全指數報告》(FLI AI Safety Index 2024)。
報告顯示,儘管 Anthropic 獲得了最高的安全性評級,但分數僅為 「C」,包括 Anthropic 在內的 6 家公司在安全實踐方面仍有提升空間。

報告鏈接:https://futureoflife.org/document/fli-ai-safety-index-2024/
關於這份報告,Tegmark 在 X 上甚至一針見血地指出:Anthropic first and Meta last,即:Anthropic 的安全性最高,而堅持開源的 Meta 在這方面卻墊底。但 Tegmark 也表示,「這樣做的目的不是羞辱任何人,而是激勵公司改進。」
值得一提的是,生命未來研究所在報告中寫道,「入選公司的依據是其在 2025 年之前打造最強大模型的預期能力。此外,智譜的加入也反映了我們希望使該指數能夠代表全球領先企業的意圖。隨著競爭格局的演變,未來的迭代可能會關注不同的公司。」
6 大維度評估 AI 安全
據介紹,評審專家從風險評估(Risk Assessment)、當前危害(Current Harms)、安全框架(Safety Frameworks)、生存性安全策略(Existential Safety Strategy)、治理和問責製(Governance & Accountability)以及透明度和溝通(Transparency & Communication)分別對每家公司進行評估,最後彙總得出安全指數總分。
維度 1:風險評估

在風險評估維度中,OpenAI、Google DeepMind 和 Anthropic 因在識別潛在危險能力(如網絡攻擊濫用或生物武器製造)方面實施更嚴格的測試而受到肯定。然而,報告也指出,這些努力仍存在顯著局限,AGI 的相關風險尚未被充分理解。
OpenAI 的欺騙性能力評估和提升研究獲得了評審專家的關注;Anthropic 則因與國家人工智能安全機構的深度合作被認為表現尤為突出。Google DeepMind 和 Anthropic 是僅有的兩家維持針對模型漏洞的專項漏洞獎勵計劃的公司。Meta 儘管在模型部署前對危險能力進行了評估,但對自治、謀劃和說服相關威脅模型的覆蓋不足。智譜的風險評估相對不夠全面,而 x.AI 在部署前的評估幾乎缺失,大幅低於行業標準。
評審專家建議,行業應擴大研究的規模與範圍,同時建立明確的可接受風險閾值標準,從而進一步提高人工智能模型的安全性和可靠性。
維度 2:當前危害

在當前危害維度中,Anthropic 的人工智能系統在安全性與信任度基準測試中得到了最高分,Google DeepMind 緊隨其後,該公司的 Synth ID 水印系統被認可為減少人工智能生成內容濫用的最佳實踐。
其他公司得分偏低,暴露出安全緩解措施的不足。例如,Meta 因公開前沿模型權重被批評,該做法可能被惡意行為者利用來移除安全防護。
此外,對抗性攻擊仍是一個主要問題,多數模型易受越獄攻擊,其中 OpenAI 的模型尤為脆弱,而 Google DeepMind 在此方面防禦表現最佳。評審專家還指出,只有 Anthropic 和智譜在預設設置下避免將用戶交互數據用於模型訓練,這一實踐值得其他公司借鑒。
維度 3:安全框架

在安全框架(Safety Frameworks)方面,所有 6 家公司均簽署了《前沿人工智能安全承諾》,承諾製定安全框架,包括設置不可接受風險閾值、高風險場景下的高級防護措施,以及在風險不可控時暫停開發的條件。
然而,截至本報告發佈,僅有 OpenAI、Anthropic 和 Google DeepMind 公佈了相關框架,評審專家僅能對這三家公司進行評估。其中,Anthropic 因框架內容最為詳盡而受到認可,其也發佈了更多實施指導。
專家一致強調,安全框架必須通過強有力的外部審查和監督機制支持,才能真正實現對風險的準確評估和管理。
維度 4:生存性安全策略

在生存性安全策略維度,儘管所有公司均表示有意開發 AGI 或超級人工智能(ASI),並承認此類系統可能帶來的生存性風險,但僅有 Google DeepMind、OpenAI 和 Anthropic 在控制與安全性方面開展了較為嚴肅的研究。
評審專家指出,目前沒有公司提出官方策略以確保高級人工智能系統可控並符合人類價值觀,現有的技術研究在控制性、對齊性和可解釋性方面仍顯稚嫩且不足。
Anthropic 憑藉其詳盡的 「Core Views on AI Safety」 博客文章獲得最高分,但專家認為其策略難以有效防範超級人工智能的重大風險。OpenAI 的 「Planning for AGI and beyond」 博客文章則僅提供了高層次原則,雖被認為合理但缺乏實際計劃,且其可擴展監督研究仍不成熟。Google DeepMind 的對齊團隊分享的研究更新雖有用,但不足以確保安全性,博客內容也不能完全代表公司整體戰略。
Meta、x.AI 和智譜尚未提出應對 AGI 風險的技術研究或計劃。評審專家認為,Meta 的開源策略及 x.AI 的 「democratized access to truth-seeking AI」 願景,可能在一定程度上緩解權力集中和價值固化的風險。
維度 5:治理和問責製

在治理和問責製維度,評審專家注意到,Anthropic 的創始人在建立負責任的治理結構方面投入了大量精力,這使其更有可能將安全放在首位。Anthropic 的其他積極努力,如負責任的擴展政策,也得到了積極評價。
OpenAI 最初的非營利結構也同樣受到了稱讚,但最近的變化,包括解散安全團隊和轉向營利模式,引起了人們對安全重要性下降的擔憂。
Google DeepMind 在治理和問責方面邁出了重要一步,承諾實施安全框架,並公開表明其使命。然而,其隸屬於 Alphabet 的盈利驅動企業結構,被認為在一定程度上限制了其在優先考慮安全性方面的自主性。
Meta 雖然在 CYBERSEC EVAL 和紅隊測試等領域有所行動,但其治理結構未能與安全優先級對齊。此外,開放源代碼發佈高級模型的做法,導致了濫用風險,進一步削弱了其問責製。
x.AI 雖然正式註冊為一家公益公司,但與其競爭對手相比,在人工智能治理方面的積極性明顯不足。專家們注意到,該公司在關鍵部署決策方面缺乏內部審查委員會,也沒有公開報告任何實質性的風險評估。
智譜作為一家營利實體,在符合法律法規要求的前提下開展業務,但其治理機制的透明度仍然有限。
維度 6:透明度和溝通

在透明度和溝通維度,評審專家對 OpenAI、Google DeepMind 和 Meta 針對主要安全法規(包括 SB1047 和歐盟《人工智能法案》)所做的遊說努力表示嚴重關切。與此形成鮮明對比的是,x.AI 因支持 SB1047 而受到表揚,表明了其積極支持旨在加強人工智能安全的監管措施的立場。
除 Meta 公司外,所有公司都因公開應對與先進人工智能相關的極端風險,以及努力向政策製定者和公眾宣傳這些問題而受到表揚。x.AI 和 Anthropic 在風險溝通方面表現突出。專家們還注意到,Anthropic 不斷支持促進該行業透明度和問責製的治理舉措。
Meta 公司的評級則受到其領導層一再忽視和輕視與極端人工智能風險有關的問題的顯著影響,評審專家認為這是一個重大缺陷。
專家們強調,整個行業迫切需要提高透明度。x.AI 缺乏風險評估方面的信息共享被特別指出為透明度方面的不足。
Anthropic 允許英國和美國人工智能安全研究所對其模型進行第三方部署前評估,為行業最佳實踐樹立了標杆,因此獲得了更多認可。
專家是如何打分的?
在指數設計上,6 大評估維度均包含多個關鍵指標,涵蓋企業治理政策、外部模型評估實踐以及安全性、公平性和魯棒性的基準測試結果。這些指標的選擇基於學術界和政策界的廣泛認可,確保其在衡量公司安全實踐上的相關性與可比性。
這些指標的主要納入標準為:
-
相關性:清單強調了學術界和政策界廣泛認可的人工智能安全和負責任行為的各個方面。許多指標直接來自史丹福大學基礎模型研究中心等領先研究機構開展的相關項目。
-
可比較性:選擇的指標能夠突出安全實踐中的有意義的差異,這些差異可以根據現有的證據加以確定。因此,沒有確鑿差異證據的安全預防措施被省略了。
選擇公司的依據是公司到 2025 年製造最強大模型的預期能力。此外,智譜的加入也反映了該指數希望能夠代表全球領先公司的意圖。隨著競爭格局的演變,未來可能會關注不同的公司。

圖|評價指標概述。
此外,生命未來研究所在編製《AI 安全指數報告》時,構建了全面且透明的證據基礎,確保評估結果科學可靠。研究團隊根據 42 項關鍵指標,為每家公司製作了詳細的評分表,並在附錄中提供了所有原始數據的鏈接,供公眾查閱與驗證。證據來源包括:
-
公開信息:主要來自研究論文、政策文件、新聞報導和行業報告等公開材料,增強透明度的同時,便於利益相關方追溯信息來源。
-
公司問卷調查:針對被評估公司分發了問卷,補充公開數據未覆蓋的安全結構、流程與策略等內部信息。
證據收集時間為 2024 年 5 月 14 日至 11 月 27 日,涵蓋了最新的人工智能基準測試數據,並詳細記錄了數據提取時間以反映模型更新情況。生命未來研究所致力於以透明和問責為原則,將所有數據 —— 無論來自公開渠道還是公司提供 —— 完整記錄並公開,供審查與研究使用。
評分流程方面,在 2024 年 11 月 27 日完成證據收集後,研究團隊將彙總的評分表交由獨立人工智能科學家和治理專家小組評審。評分表涵蓋所有指標相關信息,並附有評分指引以確保一致性。
評審專家根據絕對標準為各公司打分,而非單純進行橫向比較。同時,專家需附上簡短說明支持評分,並提供關鍵改進建議,以反映證據基礎與其專業見解。生命未來研究所還邀請專家小組分工評估特定領域,如 「生存性安全策略」 和 「當前危害」 等,保證評分的專業性和深度。最終,每一領域的評分均由至少四位專家參與打分,並彙總為平均分後展示在評分卡中。
這一評分流程既注重結構化的標準化評估,又保留了靈活性,使專家的專業判斷與實際數據充分結合。不僅展現當前安全實踐的現狀,還提出可行的改進方向,激勵公司在未來達成更高的安全標準。