圖像領域再次與LLM一拍即合!idea撞車OpenAI強化微調,西湖大學發佈圖像鏈CoT

新智元報導
編輯:LRST
【新智元導讀】MAPLE實驗室提出通過強化學習優化圖像生成模型的去噪過程,使其能以更少的步驟生成高質量圖像,在多個圖像生成模型上實現了減少推理步驟,還能提高圖像質量。
OpenAI最近推出了在大語言模型LLM上的強化微調(Reinforcement Finetuning,ReFT),能夠讓模型利用CoT進行多步推理之後,通過強化學習讓最終輸出符合人類偏好。
無獨有偶,齊國君教授領導的MAPLE實驗室在OpenAI發佈會一週前公佈的工作中也發現了圖像生成領域的主打方法擴散模型和流模型中也存在類似的過程:模型從高斯噪聲開始的多步去噪過程也類似一個思維鏈,逐步「思考」怎樣生成一張高質量圖像,是一種圖像生成領域的「圖像鏈CoT」。
與OpenAI不謀而和的是,機器學習與感知(MAPLE)實驗室認為強化學習微調方法同樣可以用於優化多步去噪的圖像生成過程,論文指出利用與人類獎勵對齊的強化學習監督訓練,能夠讓擴散模型和流匹配模型自適應地調整推理過程中噪聲強度,用更少的步數生成高質量圖像內容。
 論文地址:https://arxiv.org/abs/2412.01243
論文地址:https://arxiv.org/abs/2412.01243研究背景
擴散和流匹配模型是當前主流的圖像生成模型,從標準高斯分佈中采樣的噪聲逐步變換為一張高質量圖像。在訓練時,這些模型會單獨監督每一個去噪步驟,使其具備能恢復原始圖像的能力;而在實際推理時,模型則會事先指定若幹個不同的擴散時間,然後在這些時間上依次執行多步去噪過程。
這一過程存在兩個問題:
1. 經典的擴散模型訓練方法只能保證每一步去噪能儘可能恢復出原始圖像,不能保證整個去噪過程得到的圖像符合人類的偏好;
2. 經典的擴散模型所有的圖片都採用了同樣的去噪策略和步數;而顯然不同複雜度的圖像對於人類來說生成難度是不一樣的。
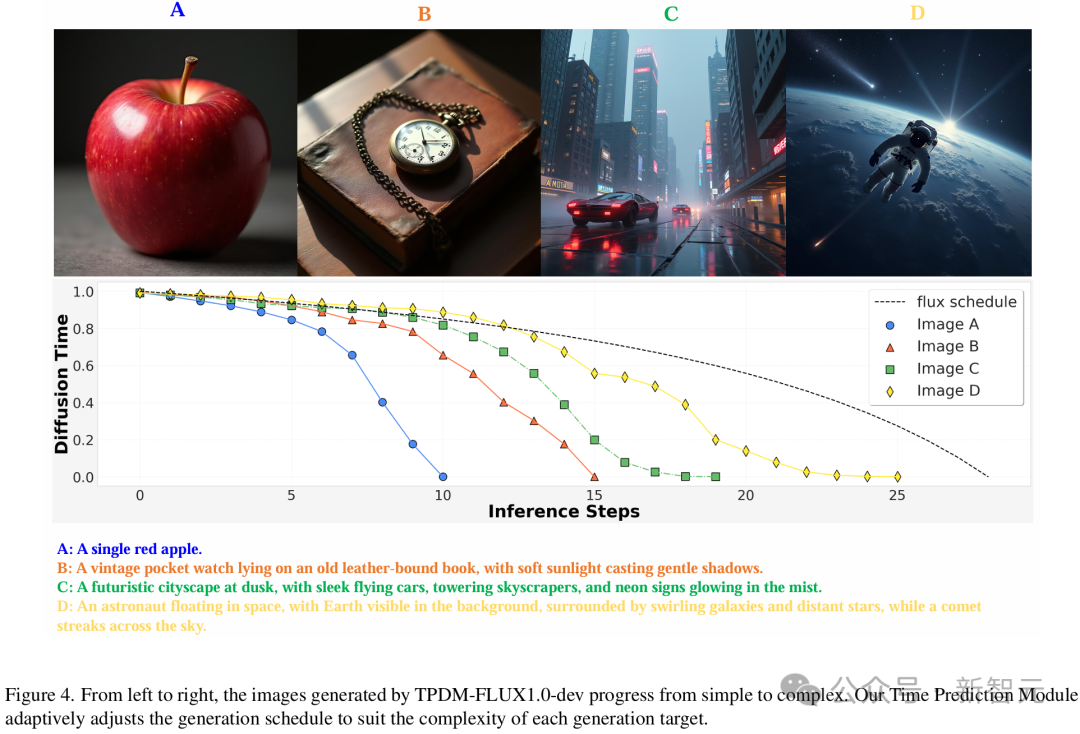
如下圖所示,當輸入不同長度的prompt的時候,對應的生成任務難度自然有所區別。那些僅包含簡單的單個主體前景的圖像較為簡單,只需要少量幾步就能生成不錯的效果,而帶有精細細節的圖像則需要更多步數,即經過強化微調訓練後的圖像生成模型就能自適應地推理模型去噪過程,用儘可能少的步數生成更高質量的圖像。
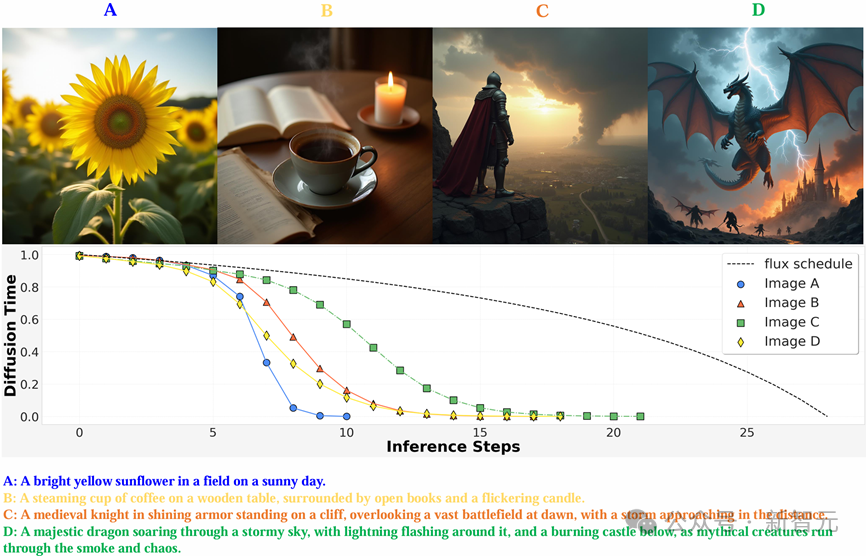
值得注意的是,類似於LLM對思維鏈進行的動態優化,對擴散模型時間進行優化的時候也需要動態地進行,而非僅僅依據輸入的prompt;換言之,優化過程需要根據推理過程生成的「圖像鏈」來動態一步步預測圖像鏈下一步的最優去噪時間,從而保證圖像的生成質量滿足reward指標。
方法
MAPLE實驗室認為,要想讓模型在推理時用更少的步數生成更高質量的圖像結果,需要用強化微調技術對多步去噪過程進行整體監督訓練。既然圖像生成過程同樣也類似於LLM中的CoT:模型通過中間的去噪步驟「思考」生成圖像的內容,並在最後一個去噪步驟給出高質量的結果,也可以通過利用獎勵模型評價整個過程生成的圖像質量,通過強化微調使模型的輸出更符合人類偏好。
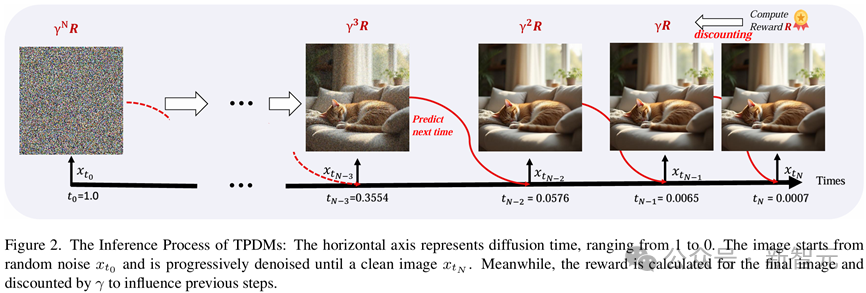
OpenAI的O1通過在輸出最終結果之前生成額外的token讓LLM能進行額外的思考和推理,模型所需要做的最基本的決策是生成下一個token;而擴散和流匹配模型的「思考」過程則是在生成最終圖像前,在不同噪聲強度對應的擴散時間(diffusion time)執行多個額外的去噪步驟。為此,模型需要知道額外的「思考」步驟應該在反向擴散過程推進到哪一個diffusion time的時候進行。
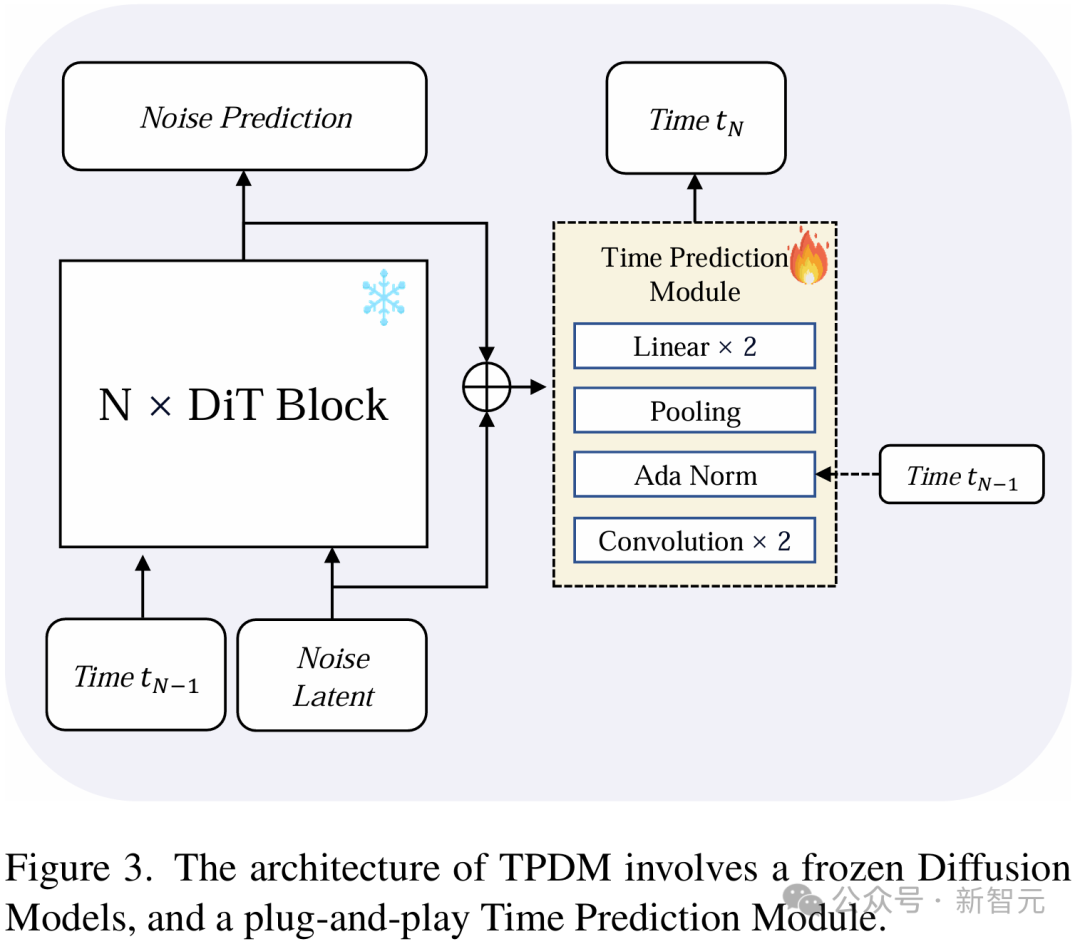
為了實現這一目的,在網絡中引入了一個即插即用的時間預測模塊(Time Prediction Module, TPM)。這一模塊會預測在當前這一個去噪步驟執行完畢之後,模型應當在哪一個diffusion time下進行下一步去噪。
具體而言,該模塊會同時取出去噪網絡第一層和最後一層的圖像特徵,預測下一個去噪步驟時的噪聲強度會下降多少。模型的輸出策略是一個參數化的beta分佈。
由於單峰的Beta分佈要求α>1且β>1,研究人員對輸出進行了重參數化,使其預測兩個實數a和b,並通過如下公式確定對應的Beta分佈,並采樣下一步的擴散時間。
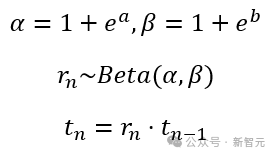
在強化微調的訓練過程中,模型會在每一步按輸出的Beta分佈隨機采樣下一個擴散時間,並在對應時間執行下一個去噪步驟。直到擴散時間非常接近0時,可以認為此時模型已經可以近乎得到了乾淨圖像,便終止去噪過程並輸出最終圖像結果。
通過上述過程,即可采樣到用於強化微調訓練的一個決策軌跡樣本。而在推理過程中,模型會在每一個去噪步驟輸出的Beta分佈中直接采樣眾數作為下一步對應的擴散時間,以確保一個確定性的推理策略。
設計獎勵函數時,為了鼓勵模型用更少的步數生成高質量圖像,在獎勵中綜合考慮了生成圖像質量和去噪步數這兩個因素,研究人員選用了與人類偏好對齊的圖像評分模型ImageReward(IR)用以評價圖像質量,並將這一獎勵隨步數衰減至之前的去噪結果,並取平均作為整個去噪過程的獎勵。這樣,生成所用的步數越多,最終獎勵就越低。模型會在保持圖像質量的前提下,儘可能地減少生成步數。
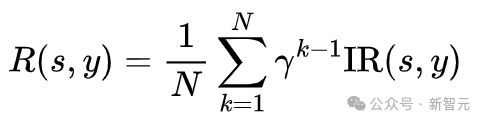
將整個多步去噪過程當作一個動作進行整體優化,並採用了無需值模型的強化學習優化算法RLOO [1]更新TPM模塊參數,訓練損失如下所示:
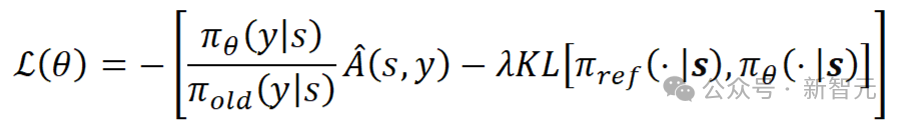
在這一公式中,s代表強化學習中的狀態,在擴散模型的強化微調中是輸入的文本提詞和初始噪聲;y代表決策動作,也即模型采樣的擴散時間;
代表決策器,即網絡中A是由獎勵歸一化之後的優勢函數,採用LEAVE-One-Out策略,基於一個Batch內的樣本間獎勵的差值計算優勢函數。
通過強化微調訓練,模型能根據輸入圖像自適應地調節擴散時間的衰減速度,在面對不同的生成任務時推理不同數量的去噪步數。對於簡單的生成任務(較短的文本提詞、生成圖像物體少),推理過程能夠很快生成高質量的圖像,噪聲強度衰減較快,模型只需要思考較少的額外步數,就能得到滿意的結果;對於複雜的生成任務(長文本提詞,圖像結構複雜)則需要在擴散時間上密集地進行多步思考,用一個較長的圖像鏈COT來生成符合用戶要求的圖片。
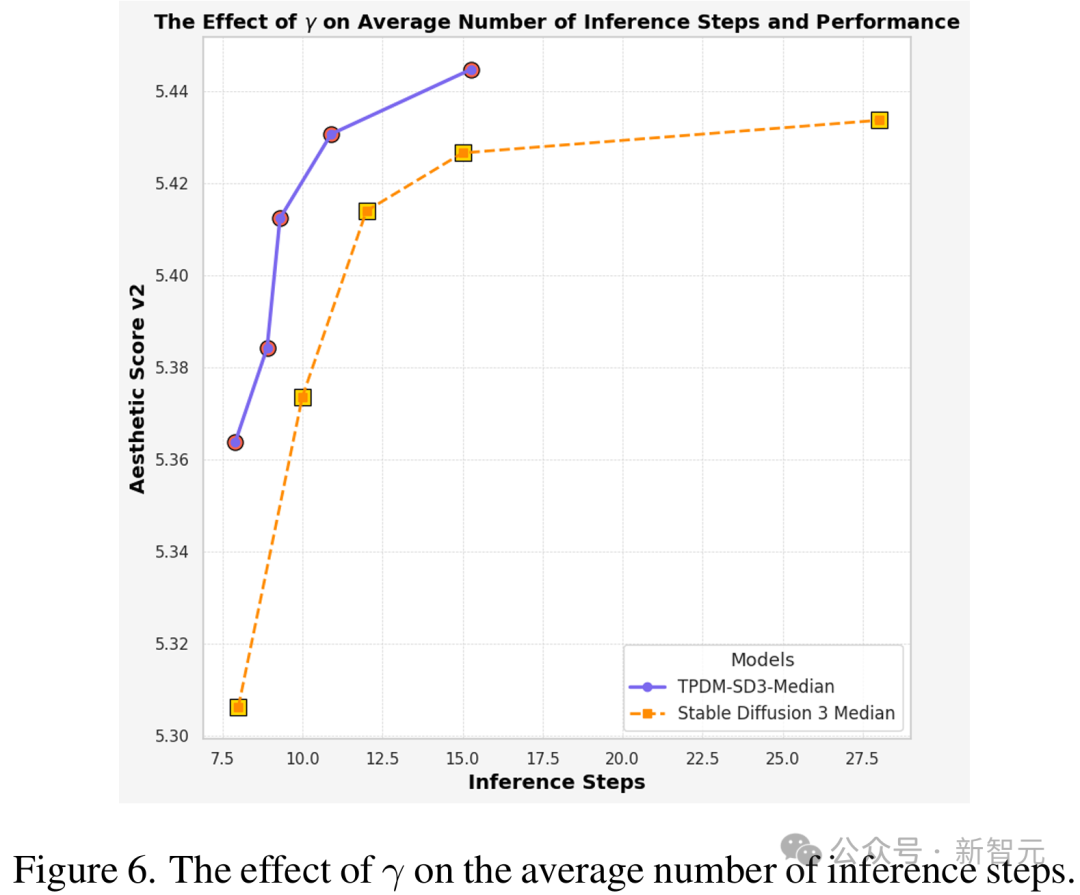
通過調節不同的γ值,模型能在圖像生成質量和去噪推理的步數之間取得更好的平衡,僅需要更少的平均步數就能達到與原模型相同的性能。
同時,強化微調的訓練效率也十分驚人。正如OpenAI最少僅僅用幾十個例子就能讓LLM學會在自定義領域中推理一樣,強化微調圖像生成模型對數據的需求也很少。不需要真實圖像,只需要文本提詞就可以訓練,利用不到10,000條文本提詞就能取得不錯的明顯的模型提升。
經強化微調後,模型的圖像生成質量也比原模型提高了很多。可以看出,在僅僅用了原模型一半生成步數的情況下,無論是圖C中的筆記本鍵盤,圖D中的球棒還是圖F中的遙控器,該模型生成的結果都比原模型更加自然。

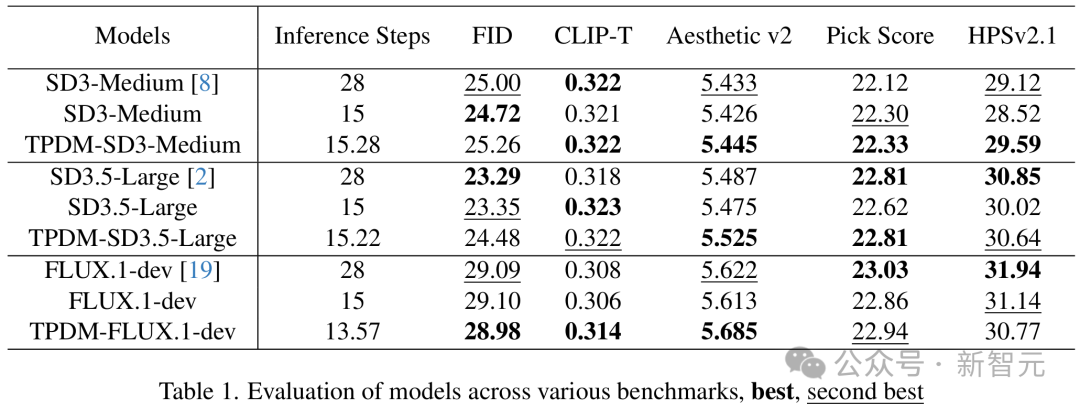
針對Stable Diffusion 3、Flux-dev等一系列最先進的開源圖像生成模型進行了強化微調訓練,發現訓練後的模型普遍能減少平均約50%的模型推理步數,而圖像質量評價指標總體保持不變,這說明對於圖像生成模型而言,強化微調訓練是一種通用的後訓練(Post Training)方法。
結論
這篇報告介紹了由MAPLE實驗室提出的,一種擴散和流匹配模型的強化微調方法。該方法將多步去噪的圖像生成過程看作圖像生成領域的COT過程,通過將整個去噪過程的最終輸出與人類偏好對齊,實現了用更少的推理步數生成更高質量圖像。
在多個開源圖像生成模型上的實驗結果表明,這種強化微調方法能在保持圖像質量的同時顯著減少約50%推理步數,微調後模型生成的圖像在視覺效果上也更加自然。可以看出,強化微調技術在圖像生成模型中仍有進一步應用和提升的潛力,值得進一步挖掘。
參考資料:
https://arxiv.org/abs/2412.01243



















