南洋理工團隊提出眼球運動計算模型,能夠近似模擬人類的覓食行為和偏見
在開車的同時掃瞄交通燈、停車位和餐館,在一堆硬幣中尋找特定數量的零錢,在雜貨店購買一系列物品……
在計算機視覺領域,這些廣泛地存在於人類日常生活中的行為,被稱為混合視覺覓食。
必須指出的是,這些目標的價值和普遍性可能會有所不同,並且,目標實例的確切數量通常也是未知的。
接下來,一個關鍵問題浮出水面,即在搜索過程中如何優先選擇目標?
如果能夠掌握內在規律,將為優化複雜環境中的搜索效率和決策帶來極大助力。
對於上述問題,眼球運動可以提供一個獨特的視角,洞察決策中涉及的感知、認知和評估過程。
 圖丨混合視覺覓食任務中眼球運動和決策的示例圖(來源:arXiv)
圖丨混合視覺覓食任務中眼球運動和決策的示例圖(來源:arXiv)基於此,新加坡南洋理工大學 Mengmi Zhang 助理教授和團隊,提出一種名為視覺覓食器(VF,Visual Forager)的計算模型。
這是一個基於 Transformer 的架構,通過強化學習訓練,能夠高效地執行混合視覺覓食,以適應目標普遍性和價值的不同組合。
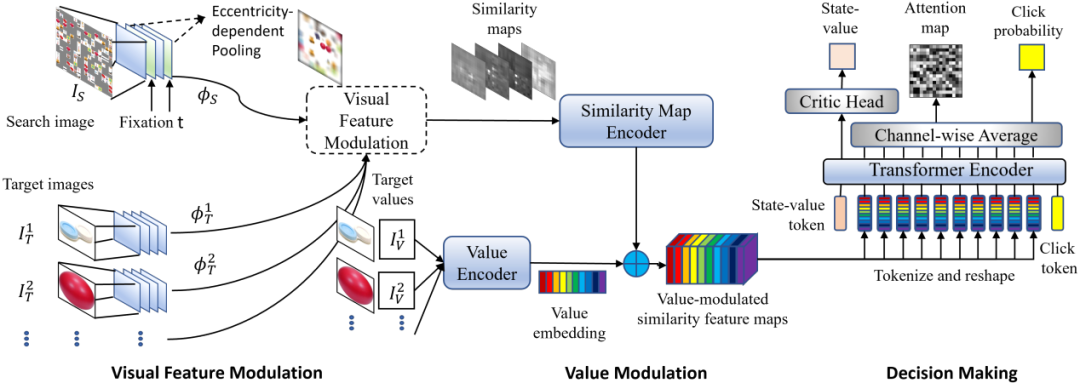 圖丨 VF 的架構概覽(來源:arXiv)
圖丨 VF 的架構概覽(來源:arXiv)不同於以往依賴人類數據進行監督訓練的視覺搜索模型,VF 沒有在人類數據上進行訓練,卻能夠近似模擬人類的覓食行為和偏見。
近日,相關論文以《凝視獎勵:眼動作為混合視覺覓食中人類和人工智能決策的透鏡》(Gazing at Rewards: Eye Movements as a Lens into Human and AI Decision-Making in Hybrid Visual Foraging)為題在預印本平台 arXiv 上發佈 [1]。
南洋理工大學 Bo Wang 是第一作者,Mengmi Zhang 擔任通訊作者。
 圖丨相關論文(來源:arXiv)
圖丨相關論文(來源:arXiv)顯然,VF 這一關於眼球運動的計算模型,能給眾多領域帶來相應的變革潛力。
例如:
在人機交互領域,可以通過預測用戶的注意力,並根據個人需求定製界面,以增強自適應系統。
在醫學診斷和培訓領域,可以複製專家的凝視模式,指導新手從業者並改進自動化診斷工具。
在機器人領域,能夠使自主系統採用類似人類的策略來導航複雜的環境。
Mengmi Zhang 表示:「該模型模擬類人決策的能力,使其有別於傳統的計算機視覺系統。」
也就是說,VF 不僅涉及識別對象,還涉及理解這些對象如何影響後續的行動和決策。
通過整合上下文信息和任務優先級,VF 模仿了人類的偏見和策略,為如何分配注意力和做出決策提供了良好的見解。
可以看出,這種範式轉變,彌合了感知與認知之間的差距,為思考和行為更像人類的人工智能系統鋪平了道路,徹底改變了需要視覺識別以外的領域。
在該研究的基礎上,下一步研究人員計劃將混合視覺覓食的研究,擴展至受控實驗環境中的簡單刺激之外。
參考資料:
1.Wang B, Tan D, Kuo Y L, et al. Gazing at Rewards: Eye Movements as a Lens into Human and AI Decision-Making in Hybrid Visual Foraging.arXiv:2411.09176, 2024.https://doi.org/10.48550/arXiv.2411.09176
支持:Ren
運營/排版:何晨龍



















