為多模態LLM引入ControlNet理念,開源插件解決災難性遺忘 | AAAI
冷大煒 投稿
量子位 | 公眾號 QbitAI
多模態大模型內嵌語言模型總是出現災難性遺忘怎麼辦?
像文生圖那樣有ControlNet即可解決。
這就是由360人工智能研究院提出的IAA的核心思路。該研究成果已被AAAI接收,並且開源。

IAA工作的思路,就是希望能把多模態理解能力像文生圖領域中的ControlNet一樣,作為插件添加到基座的語言模型之上,從而實現在完全不影響語言模型原有能力的前提下,實現多模態能力的插件化,並進一步形成一種全新的語言模型生態體系。
針對語言模型研究全新插件控制機制
當前的多模態大模型(LMM:Large Multimodal Model)主流採取的是以LLaVA系列為代表的橋接式結構:視覺編碼器與LLM之間通過模態橋接器projector進行連接實現多模態理解能力。
橋接式結構的優點是結構簡單,訓練成本低(幾十萬微調數據即可實現基本的圖像理解能力),目前主流的LMM模型包括QwenVL、DeepSeekVL、internVL以及研究院自研的360VL(https://github.com/360CVGroup/360VL)等都是採用這種結構。
但橋接式結構一直存在一個難以克服的缺點:模型多模態能力的提升不可避免地帶來原有文本能力的下降。
這背後的深層原因是,為了儘可能提升LMM在多模態理解任務上的性能表現,主流模型中內嵌的LLM語言模型參數都要在多模態訓練中打開參與學習,這樣雖然可以比較容易刷高多模態任務上的指標,但語言模型原有的文本理解能力會因為參與多模態訓練而發生災難性遺忘的問題。
這也是為什麼當前主流的多模態模型都獨立於語言模型之外存在,並冠以-VL進行區分的原因。
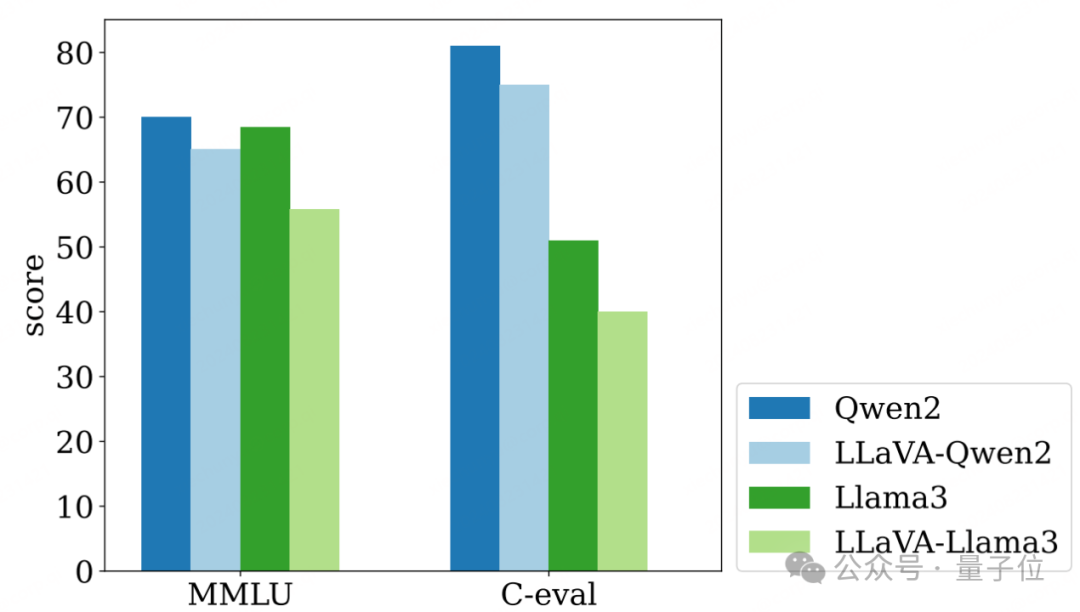
上圖清晰地比較了多模態訓練前後,內嵌語言模型在文本任務(MMLU和C-eval)上因為災難性遺忘的發生而出現的能力下滑情況。
另外從實用的角度來說,當前的多模態模型需要獨立於語言模型之外單獨部署,意味著應用時需要翻倍的部署成本,從經濟的角度來說也亟待新技術的突破。
「IAA工作的靈感來自於我們同時負責的多模態生成方向的研究。」冷大煒博士表示。
「文生圖領域有著與語言模型領域完全不同的繁榮生態。在文生圖領域中,大家是圍繞著一個基座模型,通過接入不同的插件來完成不同的任務,而不是像語言模型領域這樣要求一個模型完成所有任務。IAA工作借用了這一思路。」
在IAA的研究中作者發現,簡單地將文生圖領域的ControlNet結構複製到語言模型上的表現並不好,背後的原因是當前語言模型主流是Transformer堆疊的結構,這與文生圖模型中的UNet結構有著很大的差異,為此針對語言模型需要研究全新的插件控制機制。
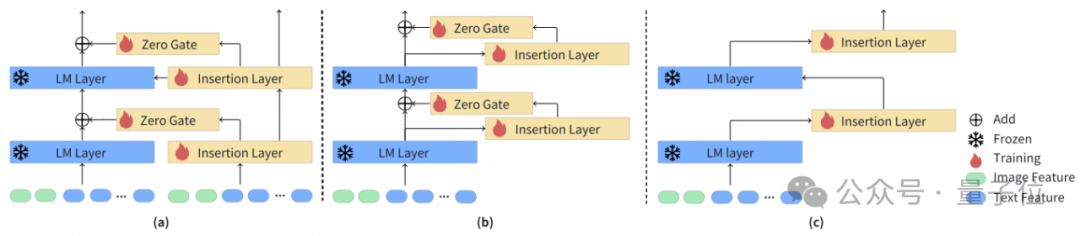
在實驗比較了一系列不同的結構後,最終形成了v1版的IAA插件網絡結構如下:
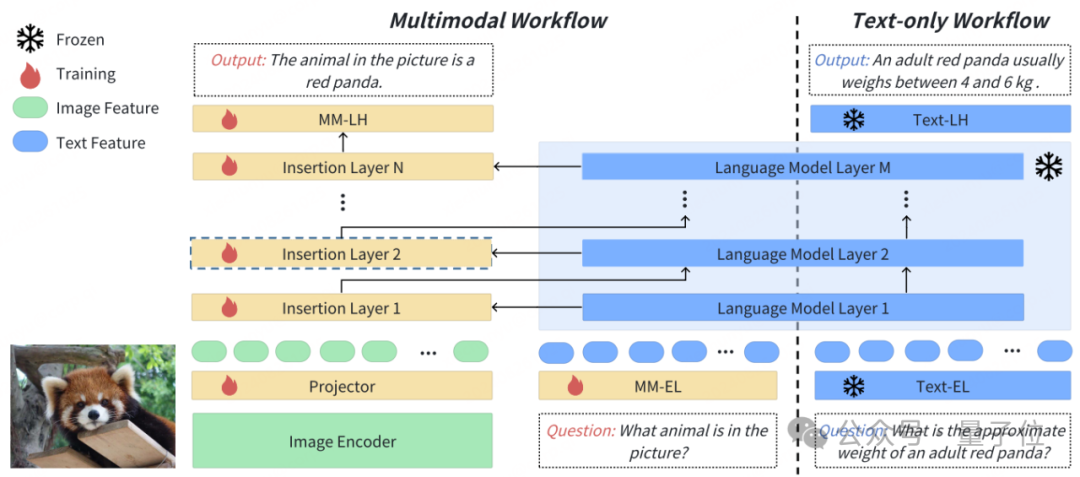
與主流的LLaVA結構相比,IAA在網絡設計上保持基座語言模型參數不變,從而避免了災難性遺忘問題的發生;對於多模態知識的學習,則是通過多個新增的插入層進行專門處理。
推理時,IAA網絡只需要部署一套模型權重,text-only任務走text-only workflow,而多模態任務則走multimodal workflow,從而避免了既要部署一套語言模型還要另外部署一套多模態模型的成本難題。
此外,IAA插件結構不僅適用於多模態任務,對於需要在基座模型能力上特別加強的任務,如code、math等任務,一樣可以通過插件的方式進行專門增強,實現「基座模型+專業插件」處理專業任務的全新用法和生態。
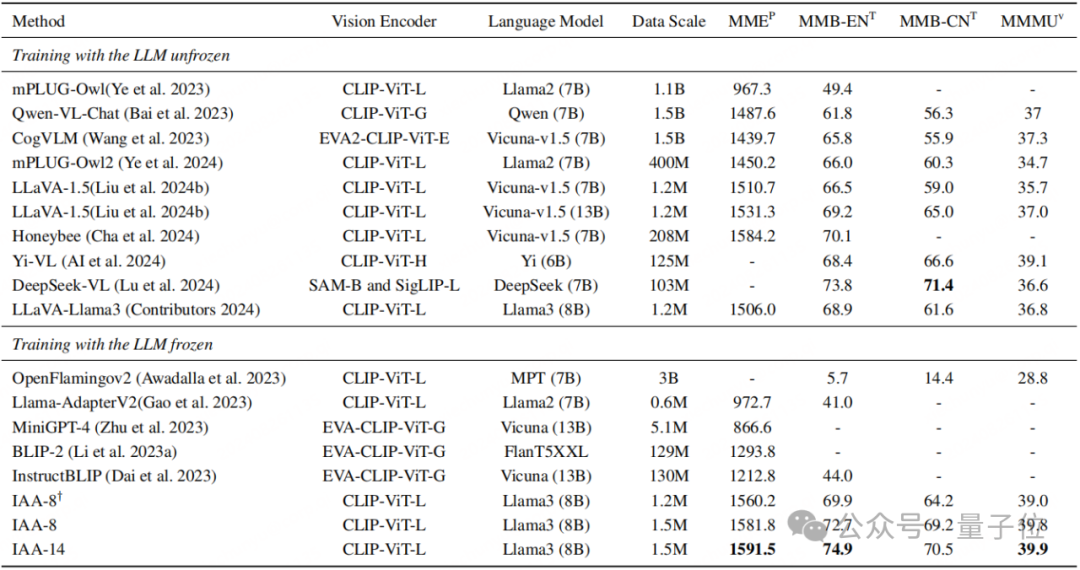
在通用多模態benchmark上比較了IAA與其它相關工作的表現,驗證了IAA在保持模型原有能力的同時,能有效提升其在多模態任務上的表現。
關於360人工智能研究院
在360集團All in AI的大背景下,360人工智能研究院發揮自身的智力優勢,承擔多模態理解和多模態生成大模型(俗稱圖生文和文生圖)的戰略研發任務,並在兩個方向上持續發力,陸續研發了360VL多模態大模型,BDM文生圖模型,可控佈局HiCo模型,以及新一代DiT架構Qihoo-T2X等一系列工作。
近日,研究院在多模態理解方向的工作IAA和在多模態生成方向的工作BDM分別被AI領域的top會議AAAI接收,這兩項工作的研發負責人為冷大煒博士。
據悉本屆AAAI 2025會議收到近1.3萬份投稿,接收3032份工作,接收率僅為23.4%。
Arxiv: https://www.arxiv.org/abs/2408.12902
Github: https://github.com/360CVGroup/Inner-Adaptor-Architecture