語言遊戲讓AI自我進化,GoogleDeepMind推出蘇格拉底式學習

新智元報導
編輯:alan
【新智元導讀】近日,GoogleDeepMind的研究人員推出了蘇格拉底式學習,在沒有外部數據的情況下,讓AI通過語言遊戲不斷變強。
沒有外部數據,AI自己也能進化?
聽起來有點嚇人,於是GoogleDeepMind的這項研究很快引起了廣泛關注。
 論文地址:https://arxiv.org/pdf/2411.16905
論文地址:https://arxiv.org/pdf/2411.16905新的方法被命名為「蘇格拉底式學習」(Socratic Learning),能夠使AI系統自主遞歸增強,超越初始訓練數據的限制。

研究人員表示,只要滿足三個條件,在封閉系統中訓練的智能體可以掌握任何所需的能力:
a)收到足夠信息量和一致的反饋;
b)經驗/數據覆蓋範圍足夠廣泛;
c)有足夠的能力和資源。
本文考慮了假設 c)不是瓶頸的情況下,在封閉系統中 a)和 b)會產生哪些限制。
蘇格拉底式學習的核心是語言遊戲(即結構化的交互),智能體在其中交流、解決問題並以分數的形式接收反饋。
整個過程中,AI在封閉的系統中自己玩遊戲、生成數據、然後改進自身的能力,無需人工輸入。
如果遊戲玩膩了,AI還可以自己創建新遊戲,解鎖更多抽像技能。
Socratic Learning消除了固定架構的局限,使AI的表現能夠遠超其初始數據和知識,且僅受時間的限制。
邁向真正自主的AI
考慮一個隨時間演變的封閉系統(無輸入、無輸出),如下圖所示。
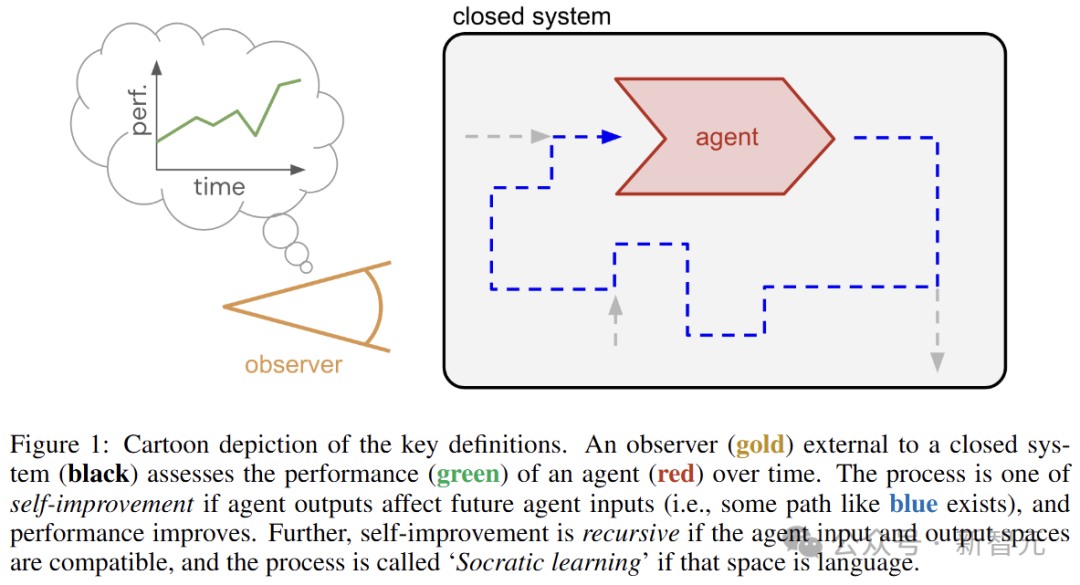
在系統中,有一個具有輸入和輸出的實體(智能體,agent),它也會隨著時間的推移而變化。系統外部有一個觀察者,負責評估智能體的性能。
由於系統是封閉的,觀察者的評估無法反饋到系統中。因此,智能體的學習反饋必須來自系統內部,例如損失、獎勵函數、偏好數據或批評者。
考慮藍色虛線的路徑,讓智能體輸出影響未來的智能體輸入,並且性能得到提高(自我改進過程),如果輸入和輸出空間兼容,則這種自我提升是遞歸的。
自我提升過程的一個典型例子是自我博弈,系統讓智能體作為遊戲的雙方,從生成一個無限的體驗流,並帶有獲勝反饋,來指導學習的方向。
反饋是其中的關鍵一環,AI的真正意義是相對於外部觀察者的,但在封閉的系統中,反饋只能來自內部的智能體。
這對於系統來說是一個挑戰:讓反饋與觀察者保持一致,並在整個過程中保持一致。
RL的自我糾正能力在這裏並不適用,可以自我糾正的是給定反饋的行為,而不是反饋本身。
蘇格拉底式學習
與輸出僅影響輸入分佈的一般情況相比,遞歸的自我提升更具限制性,但中介作用更少,最常見的是將智能體輸出映射到輸入的環境實例化。
這種類型的遞歸是許多開放式流程的一個屬性,而開放式改進正是ASI的一個核心特徵。
輸入和輸出空間兼容的一個例子是語言。人類的廣泛行為都是由語言介導的,特別是在認知領域。
語言的一個相關特徵是它的可擴展性,即可以在現有語言中開發新的語言,比如在自然語言中開發的形式數學或編程語言。

綜上,本文選擇研究智能體在語言空間中遞歸自我提升的過程。蘇格拉底式學習,模仿了蘇格拉底通過提問、對話和重覆的語言互動,來尋找或提煉知識的方法。
蘇格拉底並沒有去外界收集現實世界中的觀察結果,這也符合本文強調的封閉系統。

局限性
在自我提升的三個必要條件中,覆蓋率和反饋原則上適用於蘇格拉底式學習,並且是不可簡化的。
從長遠角度來看,如果計算和內存保持指數級增長,那麼規模限制只是一個暫時的障礙。另一方面,即使是資源受限的場景,蘇格拉底式學習可能仍會產生有效的高級見解。
覆蓋率意味著蘇格拉底式學習系統必須不斷生成數據(語言),同時隨著時間的推移保持或擴大多樣性。
生成對於LLM來說是小菜一碟,難的是在遞歸過程中防止漂移、崩潰或者生成分佈不夠廣泛。
反饋要求系統繼續產生關於智能體輸出的反饋,這在結構上需要一個能夠評估語言的批評者,且應與觀察者的評估指標保持充分一致。
然而,語言空間中定義明確的指標通常僅限於特定的任務,而AI反饋則需要更通用的機制,尤其是在允許輸入分佈發生變化的情況下。
目前的LLM訓練範式都沒有足以用於蘇格拉底式學習的反饋機制。比如下一個標記預測損失,與下遊使用情況不一致,並且無法推斷訓練數據之外的情況。
根據定義,人類的偏好是一致的,但無法在封閉系統的學習中使用。將人類偏好緩存到學習的獎勵模型中或許可行,但從長遠來看,可能會產生錯位,並且在分佈外的數據上效果也很弱。
換句話說,純粹的蘇格拉底式學習是可能的,但需要通過強大且一致的批評者生成廣泛的數據。當這些條件成立時,這種方法的上限就只取決於能夠提供的計算資源。
LANGUAGE GAMES ARE ALL YOU NEED
語言、學習和基礎是經過充分研究的話題。其中一個特別有用的概念是哲學家Wittgenstein提出的「語言遊戲」。

對他來說,捕捉意義的不是文字,而需要語言的互動性質才能做到這一點。
具體來說,將語言遊戲定義為交互協議(一組規則,可以用代碼表達),指定一個或多個智能體(玩家)的交互,這些智能體具有語言輸入和輸出,以及在遊戲結束時每個玩家的標量評分函數。
這樣定義的語言遊戲解決了蘇格拉底式學習的兩個主要需求:為無限的交互式數據生成提供了一種可擴展的機制,同時自動提供反饋信號(分數)。
從實用的角度來看,遊戲也是一個很好的入門方式,因為人類在創造和磨練大量遊戲和玩家技能方面有著相當多的記錄。
實際上,許多常見的LLM交互範式也能被很好地表示為語言遊戲,例如辯論、角色扮演、心智理論、談判、越獄防禦,或者是在封閉系統之外,來自人類反饋的強化學習。
Wittgenstein曾表示,他堅決反對語言具有單一的本質或功能。
相比於單一的通用語言遊戲,使用許多狹義但定義明確的語言遊戲的優勢在於:對於每個狹義的遊戲,都可以設計一個可靠的分數函數(或評論家),這對於通用遊戲來說非常困難。
從這個角度來看,蘇格拉底式學習的整個過程就是一個元遊戲,一個安排了智能體玩和學習的語言遊戲(一個「無限」的遊戲)。
蘇格拉底因「腐蝕青年」而被判處死刑並被處決。這也意味著,蘇格拉底過程並不能保證與外部觀察者的意圖保持一致。
語言遊戲作為一種機制也沒有迴避這一點,但它所需要的不是在單個輸入和輸出的細粒度上對齊的批評家,而是一個可以判斷應該玩哪些遊戲的「元批評家」:根據是否對整體性能有貢獻來過濾遊戲。
此外,遊戲的有用性不需要先驗評估,可以在玩了一段時間後事後判斷,畢竟事後檢測異常可能比設計時阻止要容易得多。
那麼問題來了,如果從蘇格拉底和他的弟子開始,數千年來一直不受干擾地思考和改進,到現在會產生什麼樣的文化產物、什麼樣的知識、什麼樣的智慧?
參考資料:
https://x.com/kimmonismus/status/1862993274727793047