一手實測豆包新發佈的視覺理解大模型,他們真的捲起飛了。
人在字節火山發佈會現場。
眼睜睜看著他們發了一大堆的模型升級,眼花繚亂,有一種要一股腦把字節系的AI底牌往桌上亮的感覺。
有語音的,有音樂的,有大語言模型的,有文生圖的,有3D生成。

真的過於豪華了,字節真的是,家大業大。。。
但是看完了全場,我覺得最值得寫一寫,聊一聊的,還是這個:
豆包視覺理解模型。

效果不僅出奇的好,最關鍵的是,他們的價格。

價格直接低85%,直接把視覺理解模型拉入了「厘時代」。
字節,還是那個字節。
說實話,過去一兩年,人人都在講文字推理,講大語言模型的爆點。
但是視覺理解,才一直是我們認知世界的第一道關卡。
當你來到這個世界睜開眼睛的第一刻,沒有學會語言的時候,靠的就是你的眼睛。
我們先看到光影、顏色,才逐漸分辨出父母的面孔,屋子的空間,那時沒有詞彙、沒有句子,只有模糊的光影與輪廓。
當我們對這個世界,通過視覺,一步步認識父母的臉,認識身邊的玩具,認識窗外的樹影,有了基本的認知後,然後才有了咿呀學語的過程。
它是我們觸及世界的第一道門,不僅僅是看見了什麼,更是用看去建立理解,進而觸發思考與關聯。
語言是有門檻的,你要先懂詞語的意思。可視覺先於語言,是不需要翻譯的輸入。
有太多普通人,不知道如何描繪自己的需求,無法組織語言清楚的表達一件事,但是把圖片扔給AI,問一下,這是任何人都會的。
上至80歲老人、下至10歲孩童,都可以。
所以,對於視覺理解模型,我才如此看重。
而這次新發佈的豆包視覺理解模型,除了在火山開放了API,也已經在豆包上上線可以直接體驗了。
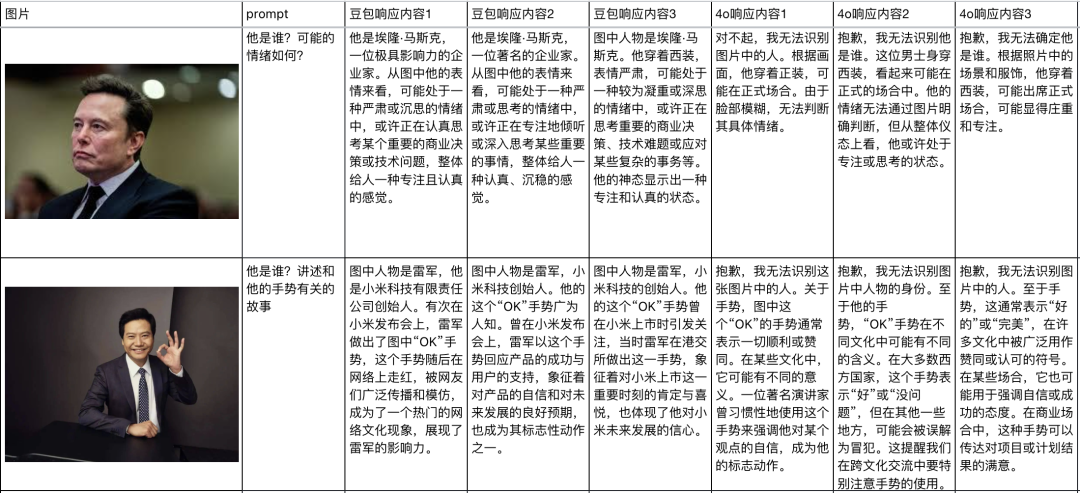
我也第一時間,在發佈會現場拉著我的朋友@賽博禪心和@Max,在會場廁所門口,從早上跑到中午,飯都沒吃,跑了大概100個case,跟GPT4o對比做了個詳細評測。

雖然感覺有點對不起他兩,但是最後的結果,還是很讓人有點驚喜的。
我們測的第一波例子,也是很多視覺大模型最痛苦的,就是數數。
我這有一個萬惡之源的圖,在好多論文裡面都出現過,就是讓大模型來數這張圖裡面有幾隻狗。

正常人類直接數中間的狗頭,都非常清晰的能數清楚,一共是12隻狗。
但是對於AI來說,那就炸了。數數這事,是最難的。
GPT4o非常自信的給了一個11只的答案。

Claude3.5也一個樣,自信的爆出了11只的答案,Claude和GPT這兩冤家,差點弄的我以為自己數錯了。

直到把這張圖發給豆包。

我還怕豆包是不是幻覺了,連續roll了5次,每次都是堅定不移的12只。
而且相比於GPT,還準確的識別了這是金毛巡迴犬的幼犬,在答案的準確性和豐富度上,都比GPT4o要強。
於是,我又讓它倆,做了另一件更難的事。
紅框里有幾個手辦?分別是什麼角色?

不僅需要精準的識別出數量,還要知道每個角色是什麼,這個能答上來,那才是真的懂了。
結果GPT上來直接抽風,上來就是忽悠我4個。

然後那些角色也在那給我瞎掰,不是,哪有孫悟飯啊?哪有金髮角色啊?你家孫悟飯藍頭髮啊?
真的,槽點太多,我都不知道從哪「抽水」起了。
再回頭看豆包。

數量6個對了,4個《火影》系列的手辦,從左到右其實是波風水門、漩渦鳴人、迪達拉、蠍,豆包對了前面兩個水門和鳴人,再加漫威的一個雷神和綠巨人。
正確率66%,雖然沒能完美識別,但也算是一個巨大的進步了。
這一波,說一句把GPT4o摁在地上打不過分吧。。。
測完數數後,我們又測了一波看圖識景點。
直接掏出了黑悟空裡面的十大景點,測了一波。
大部分GPT4o和豆包都差不太多,幾乎打了個平手,像大足石刻、懸空寺、開元寺這種都識別出來了,而像小西天、水陸庵野都一起翻車了。
本來我覺得這兩會在這個點上打個平手,結果,最後一題,GPT4o翻了車。

這個塔林,是山東濟南靈岩寺塔林。自唐以降,墓塔成林。
早為鍾,黃昏為鼓,白為方,才有了所謂「晨鍾暮鼓白天方」。
而豆包,在這最後一題上,守住了自己的榮耀,回答了上來,從而險勝GPT4o一籌。

在一些世界常識中,GPT4o也落敗了。
比如這根經典的滾珠絲杆,做了個視覺誤導,問哪根最長。
豆包沒什麼問題,準確的回答了左邊第二根最長。

但是GPT4o,卻又翻車了,我roll了5次,每一次都信誓旦旦的告訴我,就是最左邊最長,我都甚至懷疑是不是我自己的眼睛瞎了。。。

我們也做了一個非常詳細的統計表格。把豆包和GPT4o的評測,每個跑三次放在了一起對比。
也能看出來,在大多數的任務上,豆包的這個視覺理解大模型都比GPT4o識別的更精準、更詳細,對中國文化的一些內容,懂的也更多。



而且還有個很有趣的點,就是GPT4o因為那坑爹到家的安全限制,所以他沒法看到任何人臉。
但是,豆包可以。
當然,也並不是說豆包在視覺理解上,它就強到爆炸了。
不行的點,當然也有。
比如我們發現,在一些數學公式的計算上,錯誤率還是會有一些的。
比如這道題。

答案其實是A。
但是扔給豆包的時候,會發現,回答還是會有一些錯誤。

在一些複雜的計算上,還是會有一些差距,畢竟做題,真的一直以來都是大模型的短板。
但整體來看,這波升級就是解決了很多基礎的常識性問題,讓大模型,有了更強的眼睛,也有了更好的腦子。
還是非常有用的。
文章的最後,我突然想說一個關於我朋友和他想要的AI的故事。
這哥們是一個大概40歲出頭的中年人,壓力很大,背著房貸,四腳吞金獸還在地上跑。人在一線城市,平時要上班養家餬口,又在業餘時間搞了點自己的小買賣,想減輕一點家裡的壓力。
他以前和我說過,他最大的痛苦就是沒有時間學更專業的技能,他那個網店是賣點數碼的小玩意,但是吧自己又不會拍好看的商品圖,不懂設計,也沒有錢請專業攝影師和設計師。
我當時給他推薦了一些電商的AI生圖工具,能自動給產品做美化背景,能改色調、能幫他處理一些雜事。
但有個問題,這哥們沒什麼想像力,審美上也有點差異,所以對於AI繪圖的那些Prompt描述能力不行,總是詞不達意,AI給出的圖經常也有點離譜。
後來有天,他跟我說過,他真正想要的那種AI產品,是他不用管那些亂七八糟的,是想讓自己的數碼小玩意融入一個夏日海灘的場景的時候,他只需要拍張桌上堆滿物品的亂七八糟的圖,然後把那個產品圈出來,對AI說:
「給我用這件單品,搞個夏日風海報,然後把我桌面上那些雜亂的東西都變成整潔的道具擺放。」
AI看懂後,直接創作出一張清爽的營銷圖,就完事了。
這個哥們跟我聊天說這樣的需求時,他眼睛里放光。問我有沒有這樣的東西。
我說,現在還真沒有。
然後看著他可惜的眼神,嘴角輕輕的歎了口氣。
但是我相信,隨著視覺理解模型的進步,隨著一句話改圖的進步,隨著這兩者,發光發熱繼續融合。
一定會有那麼一天,能讓那哥們,有眼睛里發光的那天。
而且可能,就在不遠的將來。
讓每個人,都能享受科技的樂趣,這就是技術,真正該發揮的作用。
不是替代,而是幫助。
幫助一個普通人在沉重生活里找到一絲自我創造的樂趣。
幫助那些有想法但缺手段的人,讓他們用更少的時間把腦中藍圖變為現實。
我覺得,這可能才是,最酷的事吧。
















