禾頓商學院教授發文解析o1:能力仍有短板,「人機協同智能」或成AGI最重要難題

新智元報導
編輯:祖楊
【新智元導讀】OpenAI最近奉上了滿血版的o1 Pro,這一全新系列的模型究竟有多強?它能否指明AI發展的未來方向?禾頓商學院教授在3個月的前一篇博客就中給出了「神預言」一般的答案。
o1 preview問世3個月後,滿血版的o1 Pro終於在上週以每月200美元的身價正式上線,奧特曼號稱其為「當今世界上最智能的模型」。
所以,這個正式的o1 Pro究竟強大到了什麼程度?
可以肯定的是,它遠遠不是一個走到AGI終點的滅霸,但這是scaling law之後的又一個裡程碑嗎?代表著未來LLM的發展方向嗎?能像OpenAI研究院Jason Wei所說的,足以成為一個「傳奇」嗎?
就在o1 Pro發佈的當口,禾頓商學院副教授、GenAI實驗室聯合主任Ethan Mollick提起了這篇自己3個月前寫就的博客,可以說既是模型發佈前的「神預言」,也是一盆有理有據、恰到好處的「冷水」。
Ethan Mollick表示,早在9月份我們第一次見到o1 preview時,他就寫下了這篇博客文章,詳解這個模型對當下和未來都意味著什麼。模型的質量很重要,但更為重要的是,瞭解模型對人工智能未來的潛在意義。
下面,我們就把這篇文章當成時間傳送門,將3個月前橫空出世的o1 preview和處在性價比漩渦中的o1 Pro放在一起比較,或許可以給當下提供更多啟發。
「草莓」大顯身手

一段時間之前,我已經接觸到了傳聞沸沸揚揚的被稱為「草莓」的增強版推理系統,現在OpenAI將其發佈了,我也終於可以分享一些想法。
這個模型的確讓人驚訝,但能力仍然有限,但最重要的是,它的出現指明了AI的發展方向。
新模型被稱為o1-preview(此處Mollick狠狠「抽水」OpenAI等一眾AI公司在命名上非常糟糕),讓AI在解決問題之前先「思考」一個問題,因此能夠解決需要規劃和迭代的困難問題。
根據這張我們都熟悉的基準結果圖,o1-preview在數學和科學領域尤為強悍,對於極其困難的物理問題,甚至可以擊敗博士級別的人類專家。
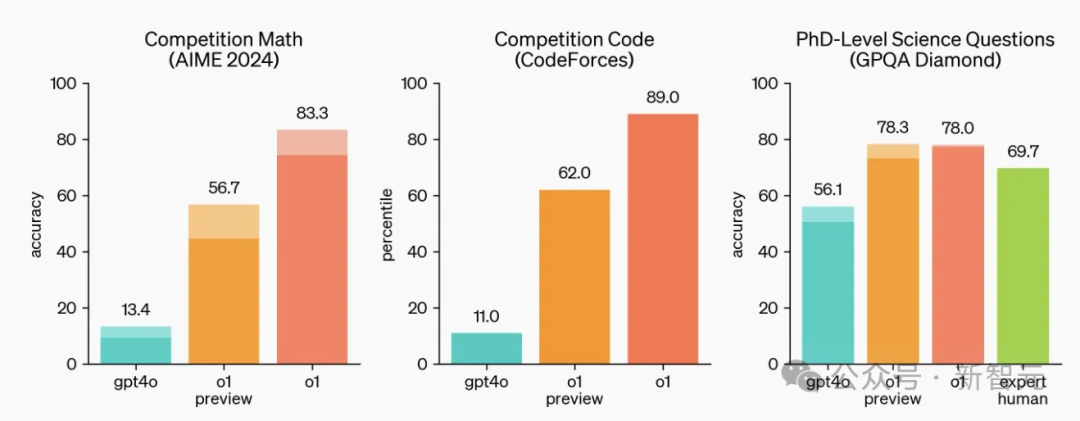
但需要明確的是,o1-preview並不是在所有方面都有提升,比如在寫作方面就沒有比GPT-4o更強;但對於需要計劃的任務來說,變化就相當大了。
由於很難評估所有這些複雜任務的輸出,因此要展示「Strawberry」模型的提升(以及一些限制),也許最簡單直觀的方法就是遊戲——比如填字遊戲(crossword puzzle)。
不要小瞧了填字遊戲,這是一個下限很低但上限也很高的項目,最難的填字遊戲完全可以達到地獄模式,而且非常考驗邏輯推理能力。
電影《模仿遊戲》中就有這樣的情節:二戰期間,AI之父Alan Turing擔任英國密碼破譯項目Enigma的負責人,為了招攬全國在數學和密碼學方面的才俊,他就在報紙上登出了一個填字遊戲作為報名測試,甚至最後一關的現場考核也是要求a在規定時間內做出填字遊戲題。
 電影《模仿遊戲》劇照
電影《模仿遊戲》劇照由於o1 preview還無法從圖片中讀取文字,因此Mollick只能自己手動打出來喂給模型。如下圖所示,這是一個相當具有挑戰性的難題,而且,Mollick只挑選了18條線索中的8條提供給o1。
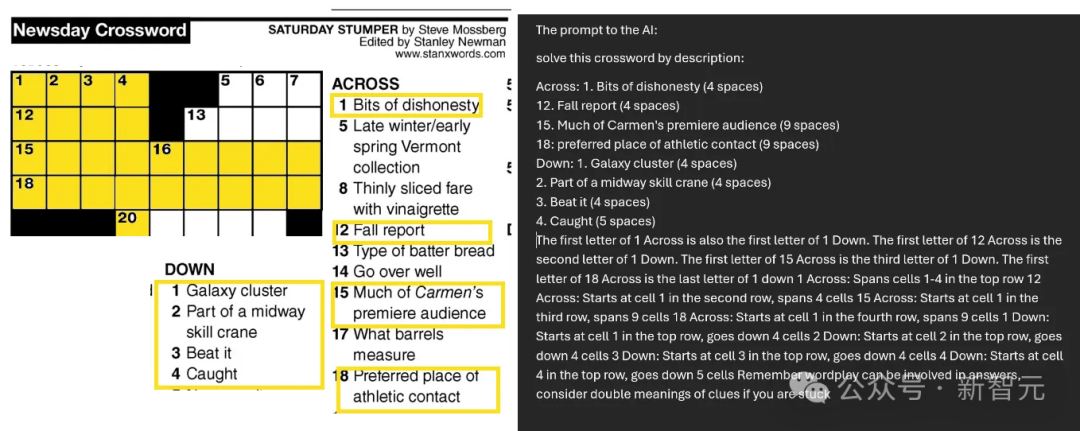
填字遊戲對於LLM來說尤其困難,因為需要迭代解決:嘗試並否決掉許多相互關聯的答案——這是之前的大模型無法做到的,因為他們一次只能在答案中添加一個token/單詞。
如下圖所示,如果給Claude提供相應的線索,它首先給出序號1的答案(它猜測是STAR,但這個答案是錯誤的),然後在此基礎上嘗試解答其餘部分。
然而,由於第一顆扣子就扣錯了,Claude永遠都無法接近正確答案。如果沒有規劃流程,它就只能向前衝,並不知道自己前進的方向是對是錯。
 Claude的嘗試
Claude的嘗試但面對相同的問題時,「草莓」時會怎麼做呢?
首先,它會開始「思考」,這個過程持續了整整108秒(但大多數問題都能在更短的時間內解決)。
而且,o1思考時並不是一聲不吭,而是會「自言自語」,輸出自己的「思維鏈」讓你看到它的想法。下面是其中的一個示例(還有更多內容未展示出來),而且這些想法非常有啟發性,值得你花點時間閱讀。

在這個過程中,「草莓」反復迭代,不斷創造想法並否決其中不可行的部分,結果做得很好,令人印象深刻。
但值得注意的是,o1-preview似乎仍然基於GPT-4o,而且有時對於語言的理解過於拘泥於字面意思。
比如,下圖右側中1 Down的答案是「Galaxy cluster」,這顯然並不是指真正的星系,而是Samsung Galaxy手機——「APPS」。
AI並沒有猜到這層意思,因此不斷嘗試各種星系團的名稱,然而確定Down 1是COMA(是一個真實的星系團),可想而知,其餘的結果也不正確。雖然不完全符合規則,但也相當有創意。
但公平來講,Mollick本人也沒有猜到這層意思。如果把「Down 1是APPS」這個線索提供給o1,可以看到模型又開始在接下來的1分鐘內快速迭代想法(下圖左側),並正確推理出了Across 1的答案是「ACTS」。
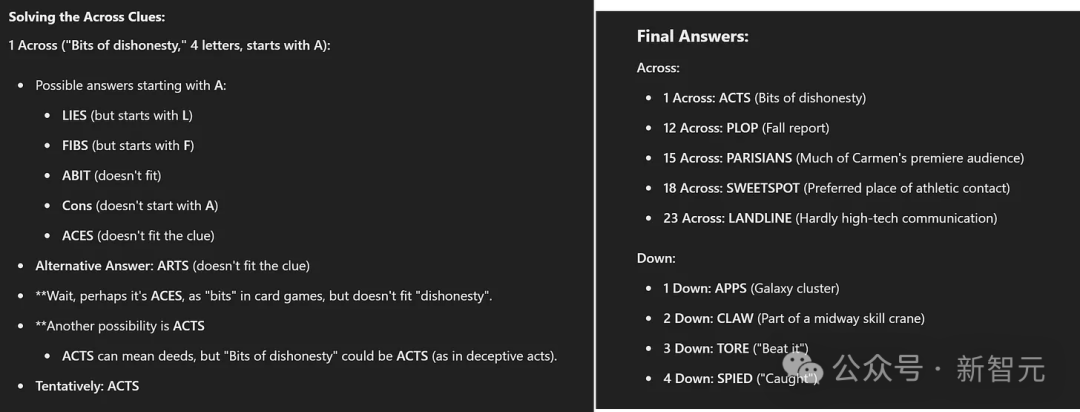
這裏是o1在一條線索的基礎上給出的最終答案,完全正確,而且解決了硬引用,儘管它幻想出了一條不存在的新線索。相比之下,身為名牌大學副教授的Ethan Mollick甚至都沒能接近這個正確答案。
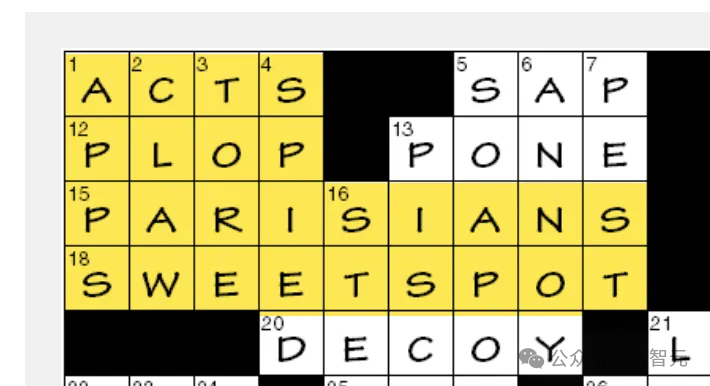
至此我們可以發現,o1-preview做了一些沒有Strawberry就不可能完成的事情,但它仍然不是完美無缺的:錯誤和幻覺仍然會發生,而且仍然受限於底層模型GPT-4o的「智能」的限制。
雖然Claude有很多優點,但相比之下,o1在複雜規劃或解題方面遠遠勝出,代表了這些領域的巨大飛躍。
從協同智能到…
o1-preview意味著我們正面臨人工智能範式的改變。「規劃」是智能體的一種表現形式,人工智能可以在沒有人類幫助的情況下自行得出結論並解決問題。
可以從上面的例子中看到,AI完成了太多繁重的思考工作,並產生了完整的結果,人類作為合作夥伴的角色反而被削弱了,整個過程的主體是AI完成了自己的工作並給出答案。
當然,我們可以篩選推理思維鏈的輸出來發現AI犯了哪些錯誤,但Ethan Mollick的感覺是,他作為佈置任務的人,和AI的輸出內容之間沒有什麼聯繫,也沒有在引導解決方案的走向上發揮重要作用。這不一定是壞事,但和之前不同。
隨著這些系統不斷升級並逐漸接近真正的自主智能體,我們需要弄清如何與其保持人類在保持同步——既能捕獲錯誤,又要及時察覺到我們試圖解決的問題。
o1-preview正在緩緩拉開帷幕,解鎖我們尚未見到的AI能力,儘管它目前還存在局限性。這給我們留下了一個關鍵問題:隨著AI的發展,我們如何進化人類與人工智能的合作?這是o1-preview目前還無法解決的問題。
參考資料:
https://x.com/emollick/status/1864857524840616345