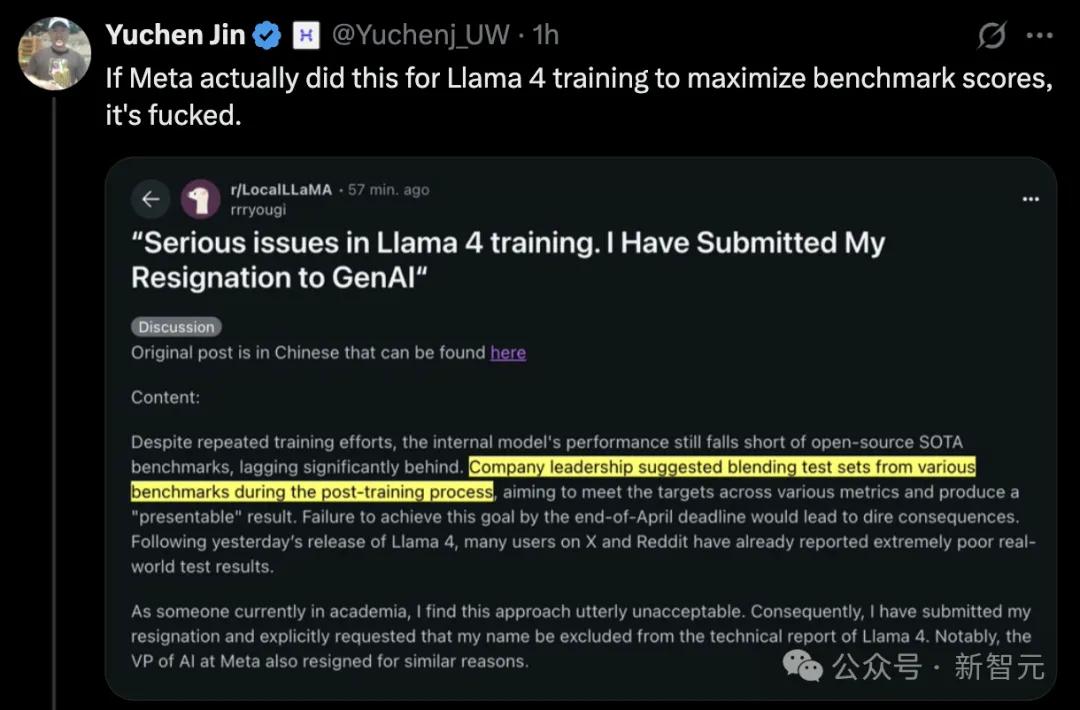
Sakana AI推出LLM記憶管理技術NAMMs,可將內存成本降低75%
記憶是認知的關鍵組成部分,讓人類能夠從充斥我們生活的無盡噪音中選擇性存儲和提取重要信息。相比之下,大語言模型(Large Language Model,LLM)則缺乏這種能力,只能無差別地存儲和處理所有過去的輸入,這在長時間任務中對它們的性能和成本產生了嚴重影響。
就像人類大腦會選擇性地保留重要信息並逐漸淡忘不重要的細節一樣,人工智能系統也需要這樣的智能記憶管理機制。否則,隨著模型規模的不斷擴大,其訓練和部署對計算資源和內存的需求也會無限上升。
長期以來,研究人員一直在探索如何讓 AI 系統具備更接近人類的記憶能力。傳統的解決方案主要依賴預設的規則來管理模型的記憶,比如基於時間順序或注意力分數(Attention Score)來選擇性地保留或丟棄信息。
然而,這些方法往往過於機械,無法像人類記憶那樣智能地區分信息的重要性,導致在提高效率的同時往往會損害模型的性能。
在此背景下,日本初創公司 Sakana AI 的研究團隊提出了一種新的解決方案——神經注意力記憶模型(Neural Attention Memory Models,NAMMs)。
這一方案借鑒了自然進化在塑造人類記憶系統中發揮的關鍵作用,通過進化算法訓練一個專門的神經網絡來,這種方法能夠像人類大腦一樣主動選擇和保留重要信息,從而在提高效率的同時提升模型的性能。
就像人類大腦會根據信息的長期使用價值來決定是否保留一樣,NAMMs 通過對注意力模式的分析來評估信息的重要性。其核心機制包括三個關鍵組成部分:特徵提取系統、記憶管理網絡和進化優化策略。
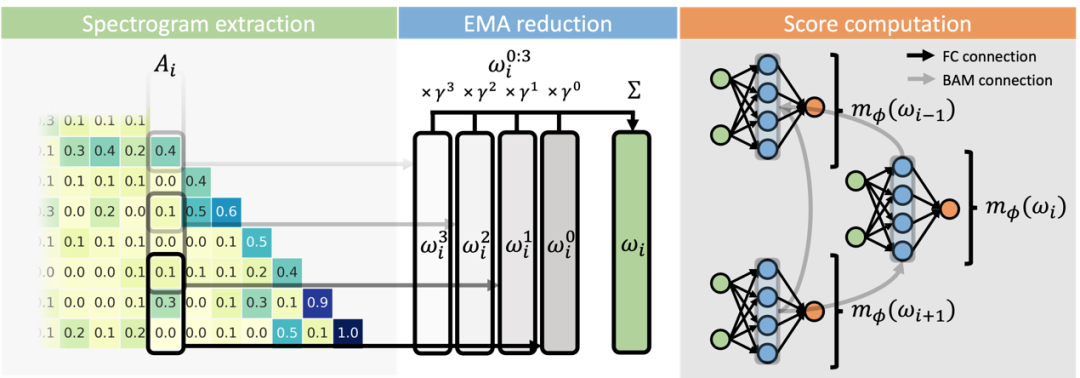 圖丨 NAMMs 執行過程中的三個主要步驟(來源:arXiv)
圖丨 NAMMs 執行過程中的三個主要步驟(來源:arXiv)首先是特徵提取機制。NAMMs 採用短時傅里葉變換(STFT)來處理注意力矩陣的列向量。具體來說,它使用大小為 32 的 Hann 窗口進行處理,生成 17 個複值頻率的頻譜圖表示。
這種表示方式非常巧妙,因為它既保留了注意力值隨時間變化的頻率特徵,又大大壓縮了數據量。研究團隊通過實驗發現,這種頻譜表示比直接使用原始注意力值或手工設計的特徵更有效。
其次是向後注意力記憶(BAM)架構的設計。這是 NAMMs 的核心創新之一,它引入了一種特殊的注意力機制,允許 token 只能關注其在 KV 緩存中的「未來」相關內容。
這種設計的妙處在於,它能夠建立 token 之間的競爭關係,使得模型能夠學會保留最有信息量的 token。例如,當出現重覆的句子或詞語時,模型會傾向於保留最新的出現,因為它包含了更完整的上下文信息。
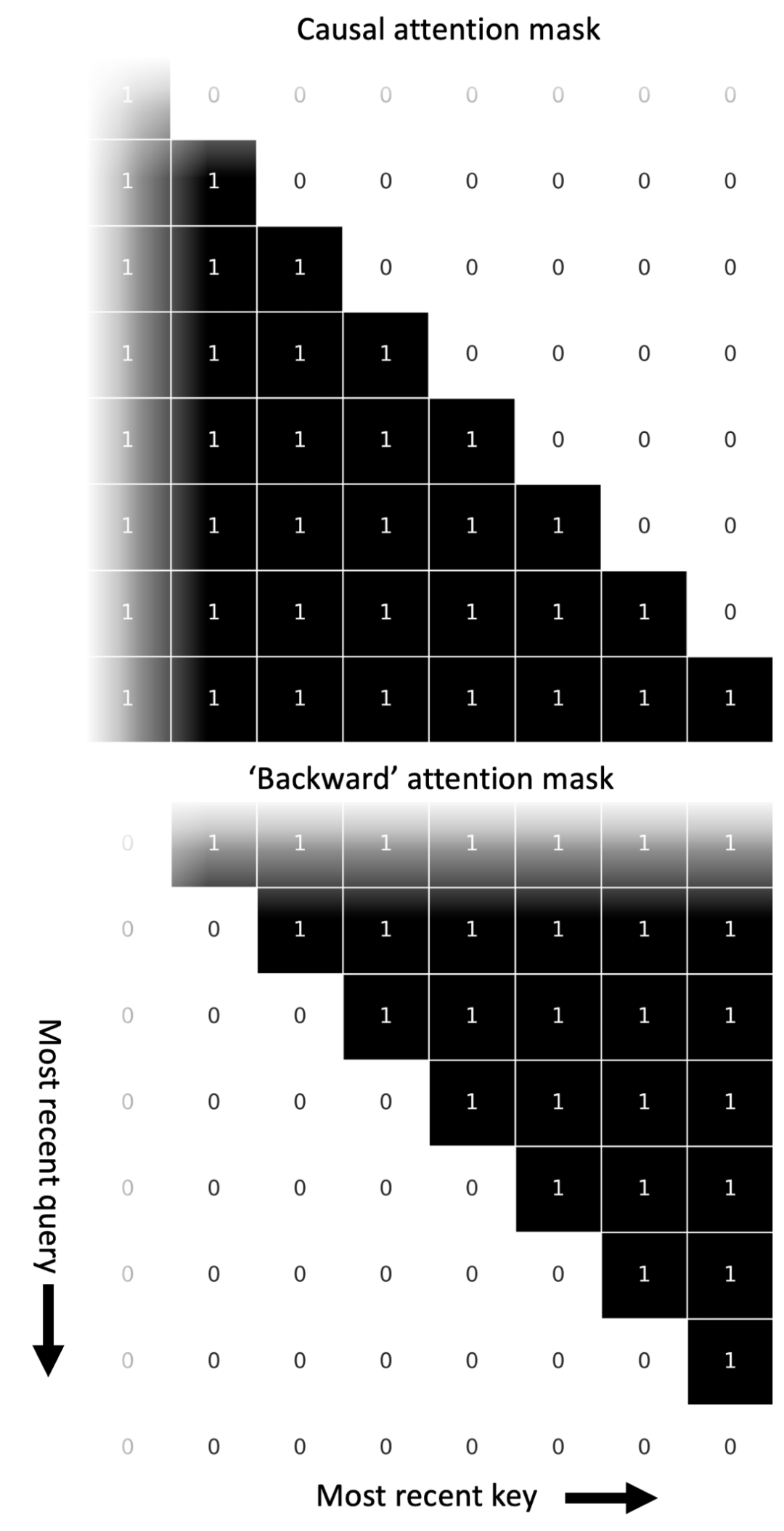 圖丨 NAMMs 的反向掩碼使每個 token 僅關注 KV 緩存中的未來相關詞(來源:arXiv)
圖丨 NAMMs 的反向掩碼使每個 token 僅關注 KV 緩存中的未來相關詞(來源:arXiv)在優化策略上,研究團隊採用了 CMA-ES(協方差矩陣自適應進化策略)算法。傳統的梯度下降法難以處理記憶管理這種具有離散決策的問題,而 CMA-ES 通過模擬自然進化過程,能夠直接優化非可微的目標函數。
具體來說,團隊採用了增量進化的方式,從單個任務開始,逐步增加訓練任務的數量,這種方式能夠提供更好的正則化效果,提高模型的泛化能力。
研究團隊選擇 Llama 3-8b 作為基礎模型訓練了 NAMMs,並在 LongBench、InfiniteBench 以及 ChouBun 上進行了全面評估。結果顯示,NAMM 為 Llama 3-8b Transformer 帶來了明顯的性能提升,在總體表現上超越了已有的 H2O 和 L2 這兩種手工設計的內存管理方法。
例如,在 LongBench 基準測試中,NAMMs 不僅將 KV 緩存大小減少到原來的 25%,還實現了 11% 的性能提升。在 InfiniteBench 測試中模型性能從基線的 1.05% 提升到了 11%,同時將緩存大小減少到原來的 40%。
 圖丨 LongBench 基準測試結果(來源:arXiv)
圖丨 LongBench 基準測試結果(來源:arXiv)NAMMs 的另一個重要特性是其出色的零樣本遷移能力。研究團隊發現,僅在語言任務上訓練的 NAMMs 可以直接應用到其他架構和模態上。
比如,當應用到 Llava Next Video-7B 模型時,NAMMs 在 LongVideoBench 和 MLVU 基準測試中都取得了不錯的表現,視覺任務的性能提升了 1%,同時將影片幀的緩存大小減少到原來的 72%。
在強化學習方面,使用決策轉換器(Decision Transformer)時,NAMMs 在 D4RL 基準測試中實現了 9% 的性能提升,同時將緩存大小減少到原來的 81%。
深入分析 NAMMs 的工作機制,研究團隊發現它學會了一種智能的記憶管理策略。通過觀察不同層的記憶保留模式,發現模型在早期和中期層傾向於保留更多和更老的 token,這可能是因為這些層負責處理和聚合長距離信息。而在信息密度較高的代碼任務中,模型則學會了保留相對更多的 token。
實際上,NAMMs 延續了 Sakana AI 此前的研究方法,即從自然界獲取靈感,通過模擬自然進化的過程來優化 AI 系統。這一研究思路與該公司在模型合併和進化優化方面的技術積累具有內在的一致性。
同 Sakana AI 此前開發的自動化「進化」算法能夠自主識別和合併優秀模型一樣,NAMMs 也採用了進化算法來優化記憶管理系統,無需人工干預即可實現性能的持續提升。
其特殊的研發思路,已經為這家僅成立了一年的初創公司贏得了 2.1 億美元的 A 輪融資,在這融資中,其估值已達 15 億美元。
未來,研究團隊可能會探索更複雜的記憶模型設計,比如考慮更細粒度的特徵提取方法,或者研究如何將 NAMMs 與其他優化技術結合使用。
他們表示:「這項工作才剛剛開始挖掘我們新類記憶模型的潛力,我們預計這可能會為未來幾代 Transformer 的發展提供許多新的機會。」
參考資料:
1.https://sakana.ai/namm/
2.https://arxiv.org/abs/2410.13166
運營/排版:何晨龍