微調時無需泄露數據或權重,這篇AAAI 2025論文提出的ScaleOT竟能保護隱私
機器之心報導
機器之心編輯部
螞蟻數科、浙江大學、利物浦大學和華東師範大學團隊:構築更好的大模型隱私保護。
要讓大模型適應各不一樣的下遊任務,微調必不可少。常規的中心化微調過程需要模型和數據存在於同一位置 —— 要麼需要數據所有者上傳數據(這會威脅到數據所有者的數據隱私),要麼模型所有者需要共享模型權重(這又可能泄露自己花費大量資源訓練的模型)。此外,在第二種情況下,模型的參數可能暴露,這可能會增加其微調模型受到攻擊的可能性。這些問題都可能阻礙 LLM 的長期發展。
為了有效地保護模型擁有權和數據隱私,浙江大學、螞蟻數科、利物浦大學和華東師範大學的朱建科與王維團隊提出了一種全新的跨域微調(offsite-tuning)框架:ScaleOT。該框架可為模型隱私提供多種不同規模的有損壓縮的仿真器,還能促進無損微調(相比於完整的微調)。該研究論文已被人工智能頂會 AAAI 2025 錄用。第一作者為姚凱(螞蟻摩斯高級算法工程師,浙大博後),通訊作者為朱建科教授與王維老師。

-
論文標題:ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
-
論文地址:https://arxiv.org/pdf/2412.09812
原生跨域微調的不足之處
如下圖 2(b) 所示,跨域微調(OT)不是使用完整的模型進行訓練,而是允許數據所有者使用模型所有者提供的有損壓縮仿真器進行微調,但這種範式有個缺點:會讓數據所有者得到的仿真器的性能較差。然後,訓練得到的適配器會被返回給模型所有者,並被插入到完整模型中,以創建一個高性能的微調模型。特別需要指出,數據所有者和模型所有者端之間的模型性能差異是模型隱私的關鍵因素,這會促使下遊用戶使用微調的完整模型。

因此,跨域微調的主要難題在於高效壓縮 LLM,通過在維持性能差異的同時提升微調的完整模型,從而實現對模型隱私的保護。
遵循跨域微調策略,原生 OT 方法採用的策略是 Uniform LayerDrop(均勻層丟棄),從完整模型中均勻地刪除一部分層,如圖 1(a)所示。

圖 1:分層壓縮策略比較。(a)Uniform LayerDrop;(b)帶估計的重要性分數的 Dynamic LayerDrop;(c)帶協調器的 Dynamic LayerReplace;(d)使用不同壓縮比的結果。新方法在所有者端實現了更好的性能,同時保持了性能差異。
然而,儘管大型模型中的許多參數是冗餘的,但每層的重要性差異很大,這種均勻刪除可能會導致適應後的完整模型的性能下降。此外,直接的層刪除會導致被刪除層的輸入和輸出隱藏空間之間錯位,這也會導致所有者端的性能下降。雖然知識蒸餾可以緩解這個問題,但訓練一個所需的仿真器的成本至少是 LLM 大小的一半,這意味著巨大的訓練成本為提供具有不同壓縮比的仿真器帶來了重大缺陷。
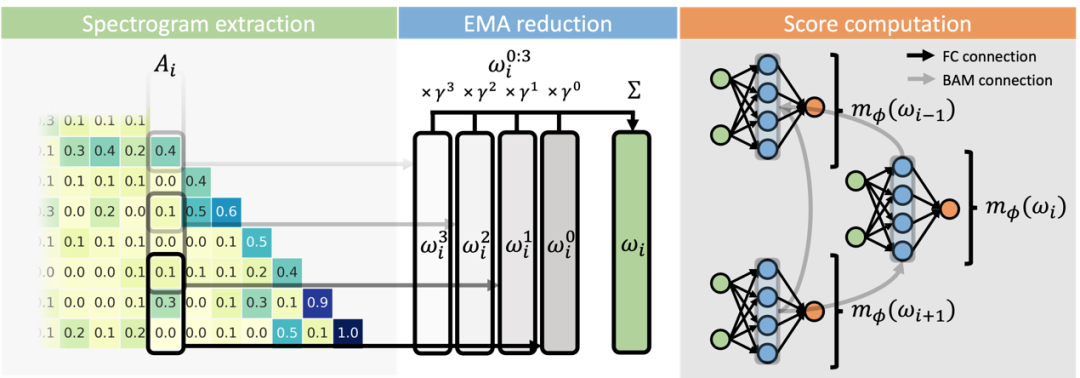
ScaleOT 實現框架設計和創建過程
如圖 2 (c) 所示,該框架由兩個階段組成:重要性估計和仿真器生成。
對於第一階段,該團隊提出了一種基於重要性感知型層替換的算法 Dynamic LayerReplace,該算法需要使用一種強化學習方法來確定 LLM 中每一層的重要性。同時,對於不太重要的層,動態選擇並訓練一組可訓練的協調器作為替代,這些協調器是輕量級網絡,可用於更好地實現賸餘層的對齊。
在第二階段,根據學習到的重要性得分,可將原始模型層及其對應的協調器以各種方式組合到一起,從而得到仿真器(emulator),同時還能在模型所有者端維持令人滿意的性能,如圖 1 (d) 所示。
他們根據實踐經驗發現,如果使用秩分解來進一步地壓縮賸餘的模型層,還可以更好地實現隱私保護,同時模型的性能下降也不會太多。基於這一觀察,該團隊提出了選擇性秩壓縮(SRC)方法。
該團隊進行了大量實驗,涉及多個模型和數據集,最終證明新提出的方法確實優於之前的方法,同時還能調整壓縮後仿真器模型的大小以及 SRC 中的秩約簡率。因此,這些新方法的有效性和可行性都得到了驗證。
總結起來,該團隊的這項研究做出了三大貢獻:
-
提出了一種靈活的方法,可為跨域微調得到多種大小的壓縮版模型:提出了一種重要性感知型有損壓縮算法 Dynamic LayerReplace,該算法面向使用 LLM 的跨域微調,可通過強化學習和協調器來擴展仿真器。這些組件可以實現靈活的多種規模的壓縮模型生成。
-
僅需一點點微調性能下降,就能通過進一步的壓縮獲得更好的隱私:新提出的選擇性秩壓縮策略僅需少量性能損失就能進一步提升模型隱私。
-
全面的實驗表明,新提出的 ScaleOT 優於當前最佳方法。
在研究中,該團隊考慮到隱私問題阻止了數據和 LLM 的所有者之間共享和共存數據及模型。他們的目標是在不訪問模型所有者的模型權重的情況下,使用數據所有者的數據來調整模型。從預訓練的 LLM M 開始,其參數由權重 Θ 表示,以及下遊數據集 D,該團隊在下遊數據上微調這個模型,以實現

,其中
該團隊的目標是通過找到一個比




),從而消除了直接訪問 M 的需求。
),幾乎可以複製直接在數據集上優化 M 時觀察到的性能(表示為
。該團隊希望,通過將訓練好的權重∆^∗重新整合到原始模型中(表示為
不會威脅到 LLM 的擁有權。然後,數據所有者使用他們的數據集對替代模型進行微調,得到
(稱為仿真器),來促進隱私遷移學習。這種方法可確保與下遊用戶共享
更小、更弱的替代模型
為了方便,他們給出了以下定義:

表示微調(FT)性能;
和
分別表示仿真器ZS和FT的性能;
表示插件性能。
表示零樣本(ZS)性能;
一個有效的跨域微調應該滿足以下條件:1)ZS < 插件,以使微調過程成為必要。2)仿真器 FT < 插件,以阻止下遊用戶使用微調後的仿真器。3)插件 ≈ FT,以鼓勵下遊用戶使用 plugged model。
基於 Transformer 架構設計跨域微調更具實用性
這篇論文關注的重點是基於 Transformer 架構來設計跨域微調。
這裏需要將每個 Transformer 層視為一個基本單元,而 LLM 可以表示成 M = {m_1, m_2, . . . , m_n},其中 n 是總層數。該團隊的新方法需要將 M 分成兩個組件:一個緊湊型的可訓練適應器 A 和模型的其餘部分 E。層索引的集合可以定義成滿足此條件

為了保護模型的隱私,需要對保持不變的組件 E 執行一次有損壓縮,這會得到一個仿真器 E*,從而可通過更新 A 來促進模型微調。
待完成在數據所有者端的訓練後,更新後的適應器 A′ 會被返回到模型所有者端並替換 M 中的原來的 A。於是可將最終更新後的 LLM 表示為 M′ = [A′, E]。值得注意的是,有損壓縮必定會限制下遊用戶的 [A′, E∗] 模型性能,但卻實現了對模型擁有權的保護。
這篇論文解決了該問題的兩個關鍵:獲得 A 和 E 的適當劃分以及實現從 E 到 E∗ 的更好壓縮,從而實現有效的微調並保持隱私。
對於前者,該團隊在模型層上引入了重要性分數(importance score),可用於引導 A 和 E 的選擇。具體而言,在用輕量級網絡動態替換原始層的過程中,可通過強化學習來估計重要性分數。
這些輕量級網絡(稱為協調器 /harmonizer)可以進一步用作 E 中各層的替代,從而提高完整版已適應模型的性能。此外,對於 E 中被協調器替換的其餘層,該團隊還提出了選擇性秩壓縮(selective rank compression)方法,該方法在保持完整版已適應模型性能的同時還能保證更好的隱私。
重要性感知型動態層替換
該團隊提出了一種全新的基於層替換的壓縮算法:Dynamic LayerReplace(動態層替換)。其目標是估計 LLM 中每層的重要性,並用輕量級網絡(稱為協調器)替換不太重要的層,以保持層之間的語義一致性。為此,他們採用了一種雙過程方法,其中包括使用強化學習 (RL)來評估每個 LLM 層的重要性,使用深度學習(DL)來通過梯度下降訓練協調器。在訓練階段,這些過程交替迭代以保持穩定性。
從數學形式上看,首先將 LLM 記為 M。然後對重要性分數 S 和協調器進行初始化。用於預訓練的數據集的兩個子集會被用作訓練集 D^T 和驗證集 D^V ,它們與下遊任務無關。在訓練過程中,利用 RL 更新 S 並通過 DL 訓練 H,同時保持 M 不變。下面將介紹 RL 的基本動作 LayerReplace 采樣,並描述如何獲得重要性分數。
LayerReplace 采樣。首先,需要將 RL 過程的狀態空間定義為網絡內層的配置,其中包含了原有層和協調器。是否用相應的協調器替換特定層 —— 這個決定將用作動作,會受到基於每層重要性分數的動作策略 π_i 的影響:

其中 U (a, b) 表示 a 和 b 之間的均勻分佈。每次,隨機采樣一個概率 p_i ∼ π_i,得到所有層的概率集 P = {p_1, p_2, . . . , p_n}。
根據實踐經驗,該團隊具體設置成:根據 P 采樣 LLM 中一半數量的層,然後代之以協調器。
但是,由於 LLM 通常很深,並且訓練早期的動作策略不準確,因此直接選擇一半的層可能會導致選中大量相鄰層,從而可能導致訓練崩潰。為瞭解決這個問題並確保訓練穩定性,該團隊將網絡層重新分組為 N_g 個相鄰層索引組,並替換每個組中的一半層。各個組的集合可記為

剩下層的索引集的結構為:
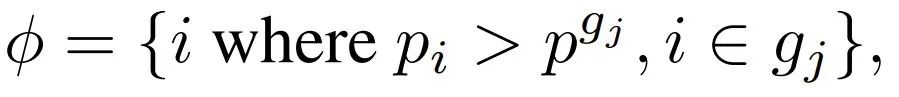
其中 p^gj 是第 j 組中的中位數概率,N_g 根據經驗預設設置為 4。根據 φ,采樣得到的 LayerReplace 候選網絡可以寫成:

其中 f_i ◦ f_{i+1} 表示組合函數。
重要性和協調器更新。為了提升效率,該團隊提出可以聯合更新重要性分數和協調器,這涉及到 DL 和 RL 的訓練。對於 DL 的訓練,先執行一次 LayerReplace 采樣,並使用訓練數據集 D^T 通過任務損失更新采樣候選網絡中的協調器的參數,即

。這裏,該團隊使用了負對數似然損失,這是一個被廣泛使用的下一 token 預測標準。隨後,通過反向傳播得出更新協調器所需的梯度。
對於 RL 的訓練,則是基於采樣得到的概率集

采樣 N_c 個 LayerReplace 候選網絡。然後,使用留存的驗證集 D^V 生成索引集


和它們相應的損失
最後,可將第 j 個動作策略的獎勵寫成:

如果該獎勵大於 0,就表明與其他策略相比,該策略憑藉采樣得到的候選網絡而損失較小,從而是更優的策略。因此,該策略中包含的層更加重要。於是,便可以通過下式來更新重要性分數(其中 σ 表示 S 型函數):

使用 Dynamic LayerReplace 完成訓練後,可以得到該 LLM 的每一層的重要性分數,以及替換這些層的協調器;它們將被用於後續的仿真器創建過程。
選擇性秩壓縮
該團隊通過大量研究發現,大語言模型的參數數量遠超過實際需要,即使去掉一部分參數也不會顯著影響模型的整體性能。
基於這一發現,該團隊提出了一種通過低秩近似壓縮仿真器權重的方法來增強模型的隱私保護功能。當權重的高階份量被降低時,仿真器的表達能力會相應減弱,從而產生更大的性能差距。同時,賸餘的低階權重份量仍然可以為調優過程中的適配器更新提供近似梯度方向。
對特定模塊的秩壓縮策略
Transformer 模型的每一層主要由兩個部分組成:多頭自注意力層 (MHSA) 和前饋神經網絡層 (FFN)。MHSA 負責處理詞元之間的交互,而 FFN 則進一步處理單個詞元內的信息轉換。為了提升表達能力,FFN 的隱藏維度通常設置得很高,是輸入輸出維度的 2.5 到 4 倍。
考慮到 FFN 本身就具有高秩的特性,該團隊提出了一種策略 —— 只對 MHSA 層的權重進行秩壓縮,以增強模型的隱私保護。
如圖 3 所示,實驗表明,如果對所有層 (MHSA+FFN) 或僅對 FFN 進行秩壓縮,都會導致模型和數據性能的指數級下降。相比之下,僅對 MHSA 層進行秩壓縮時。雖然會使仿真器性能快速下降,但對插件性能的影響較小,尤其是在壓縮比大於 0.6 時。因此,研究團隊選擇了對仿真器中的 MHSA 層進行秩壓縮的策略。

創建保護隱私且實用的仿真器
既要滿足保護隱私,還具備擴展性的仿真器的設計基於三個核心參數:調整層數量 (Na)、協調器替換比例 (α) 和結構秩壓縮比例 (β)。這些參數共同決定了如何使用大語言模型 (M)、重要性分數 (S) 和協調器 (H) 來創建仿真器 (E),從而在保護隱私和保持模型性能之間取得平衡。
具體來說,給定
到 N_g,把模型中的所有層按以下指標規定的重要性分成兩組:
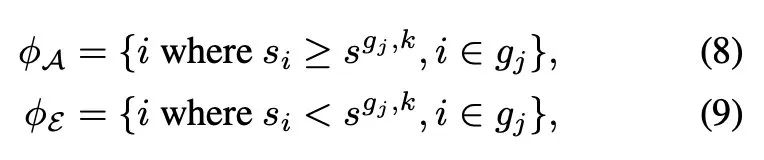
這個分組過程使用了一個基於組大小的動態閾值參數


代表每組中第 k 大的重要性分數。
,其中
由於目標是調整最重要的層,同時保持 LLM 中較不重要的層不變,因此

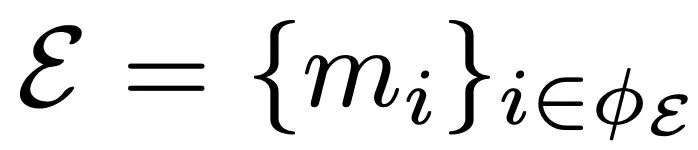
。既而,協調器的指標集定義如下:
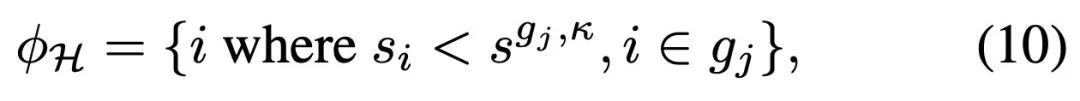
其中,
是第 j 組中第 κ 個最大的重要性分數,φH ∈ φE。仿真器 E∗可以表示為:
,

通過調節 α 和 β,可以有效管理模型的隱私。通過增加 α 和 β 的值,用更高的壓縮率來增強隱私,減小這些值則可以更適配模型的性能。在用 E 調整 A 之後,下遊用戶將 A’ 返回給模型所有者,以形成優化後的 LLMs M’ = [A’, E]。
ScaleOT 效果評估更好的性能,更優的模型隱私
該團隊首先在中等大小的模型(包括 GPT2-XL 和 OPT-1.3B,大約 10 億參數量)上評估了他們提出的 ScaleOT,如表 1 所示。所有方法都滿足了跨域微調的條件,即插件的性能超過了完整模型的零樣本和仿真器微調的性能。此外,沒有 SRC 的 ScaleOT 幾乎實現了與完整微調相當的無損性能。這突出了動態層替換與基線 OT 中使用的 Uniform LayerDrop 相比的有效性。
值得注意的是,由於選擇了重要的層進行更新,插件的性能可以超過直接在 LLM 上進行微調的性能,這得益於稀疏訓練帶來的更好收斂性。最後,SRC 的加入顯著降低了仿真器零樣本和微調的性能,平均降低了 9.2% 和 2.2%,而插件的性能幾乎沒有下降。總體而言,ScaleOT 不僅實現了更好的性能,還確保了良好的模型隱私。

隨後,該團隊驗證了他們提出的 ScaleOT 在更大的 LLM 上的有效性,包括擁有大約 70 億參數的 OPT-6.7B 和 LLaMA-7B。如表 2 所示,由於在有限的硬件上無法執行知識蒸餾,OT 未能達到令人滿意的性能。CRaSh 通過 LayerSharing 提高了性能,但由於壓縮後無法完全恢復性能,導致結果並不理想。

相比之下,ScaleOT 使得大型模型的壓縮變得可行,僅需要在壓縮階段訓練大約 1-2% 的參數。值得注意的是,該團隊提出的方法在 WebQs 任務上實現了強大的插件性能,其中零樣本準確率為零,突顯了其在新的下遊應用中的潛力。此外,ScaleOT 取得了值得稱讚的結果,表明其有效性並不局限於特定的模型大小。這使得 ScaleOT 成為增強不同規模模型跨域微調結果的有價值策略。
SRC 的效果
為了評估 SRC 在提高模型隱私方面的有效性,該團隊在 WikiText 數據集上對 GPT2XL 和 OPT-1.3B 進行了實驗。如圖 4 所示,他們線性地將壓縮比率 β 從 0 提高到 1,導致網絡中的秩降低。

隨著 β 的提高,他們觀察到仿真器微調和插件性能都出現了持續下降,特別是在包含前饋網絡(FFN)的配置中,此處線性關係非常明顯。相比之下,在 0.6 到 1 的範圍內,對於 MHSA 配置,仿真器 FT 性能顯示出指數級下降,而插件性能則表現出線性降低。這表明 SRC 有潛力在不降低整體性能的情況下增強模型隱私。
重要性得分
該團隊對 OPT-6.7B 和 LLaMA-7B 的估計重要性得分進行了可視化,如圖 6 所示。
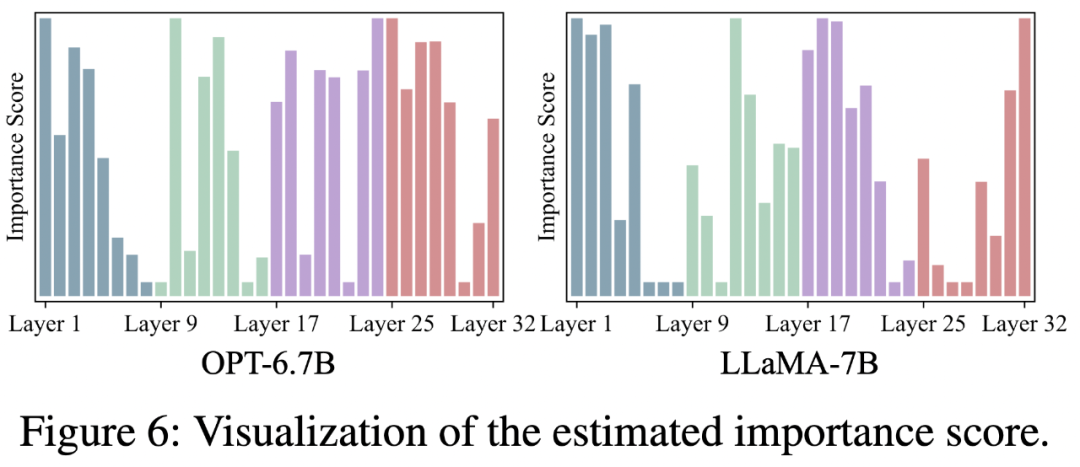
可以明顯看出,在不同網絡中,重要性分佈存在相當大的差異。然而,一個一致的模式出現了:第一層具有顯著的重要性。這一發現與 OT 的觀察結果相呼應,儘管缺乏明確的解釋。
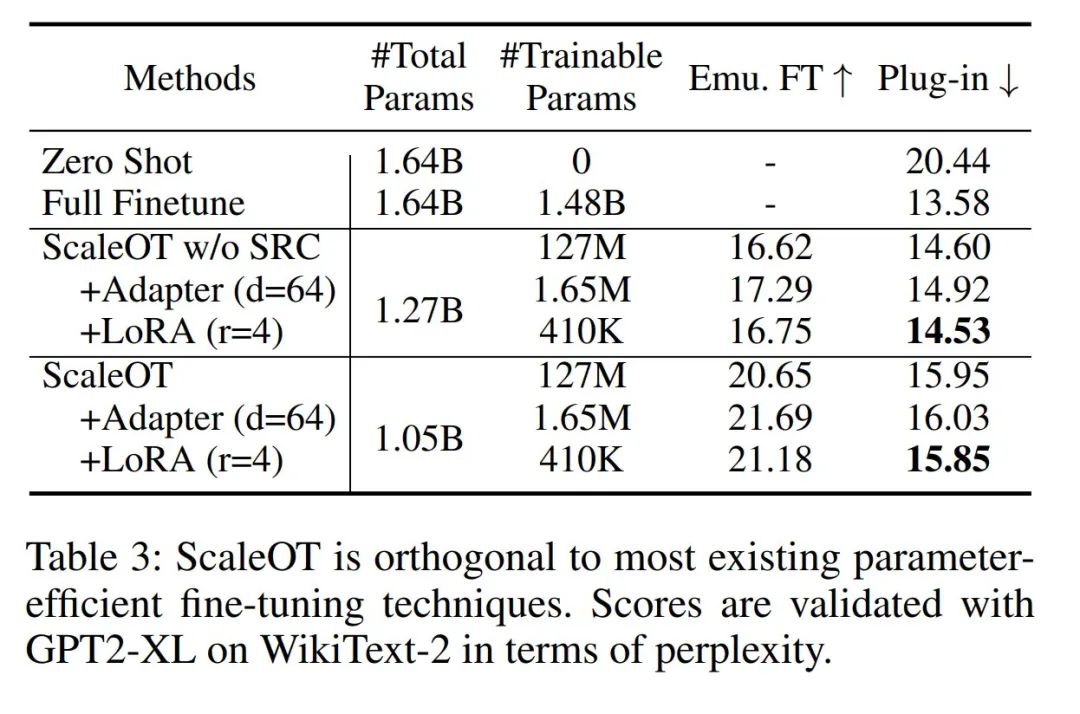
與參數高效微調的正交性
根據設計,ScaleOT 能與參數高效微調(PEFT)方法無縫集成,從而形成一種綜合方法,顯著減少可訓練參數並提升效率。這可以通過在調整層中使用 PEFT 方法來實現,包括 Adapter-tuning 和 LoRA 等策略。如表 3 所示,該團隊觀察到 Adapter-tuning 和 LoRA 在保持插件性能的同時大幅減少了可訓練參數。
結語
螞蟻數科摩斯團隊這一全新的大模型隱私微調算法,有效攻克了在仿真器生成時計算複雜度高、模型隱私安全性不足等難題,成功為大模型隱私保護提供了新穎的思路與解決方案。作者表示,該創新源自螞蟻數科在 AI 隱私安全領域的持續投入與實踐,這一算法融入摩斯大模型隱私保護產品,並已成為首批通過信通院大模型可信執行環境產品專項測試的產品之一。