更懂中文還兼顧SD生態,360開源文生圖模型結構,寡姐秒變中國新娘 | AAAI
冷大煒 投稿
量子位 | 公眾號 QbitAI
具備原生中文理解能力,還兼容Stable Diffusion生態。
最新模型結構Bridge Diffusion Model來了。
與Dreambooth模型結合,它生成的穿中式婚禮禮服的歪國明星長這樣。

它由360人工智能研究院提出,最近剛被AAAI接收,並已開源。

類似ControlNet的分支網絡思路
文生圖模型的中文原生問題,一直是一個重點研究問題。
受算力和數據因素的限制,國內大量的中文AI繪畫產品背後,實際上很多是以開源的英文模型及其微調模型為能力基座,但是,英文模型包括且不限於SD1.4/1.5/2.1/3.5以及DALLE、Midjourney、Flux等,因為這些模型的訓練數據以英文數據為主,因此在生成圖像時,主體形象包括人物、物品、建築、車輛、服飾、標誌等,都存在非常普遍和明顯的英文世界觀偏見。
BDM是我們在多模態生成方向比較早期的工作,關注兩個關鍵問題:
1)原生中文及生成模型的世界觀偏見
2)與SD生態的兼容性
冷大煒博士對BDM工作的主要著眼點做了如上的精煉概括。
「原生中文」問題指的不僅僅是文生圖模型支持中文輸入,更核心的是要求模型生成的人、物形象應該符合中文文化的認知。
下圖是AI繪畫模型的世界觀偏見實例,從左到右分別是SDXL,Midjourney,國內友商B*,國內友商V*:

中文AI繪畫模型,從實現的路線選擇上,從易到難大致有以下幾種方式:
英文模型 + 翻譯。
簡單直接,除了翻譯外幾無成本。這種方式只能解決表面上的中文輸入問題,並不能解決英文模型因為模型偏見而無法生成符合中文文化認知形象的問題。
英文模型 + 隱式翻譯。
與顯式調用翻譯服務不同,這種方式是將英文模型的text encoder替換為中文text encoder,並利用中英文平行語料對中文text encoder進行訓練,使其輸出的embedding空間與原來的英文text encoder對齊。本質上屬於一種隱式翻譯,也是成本非常低的一種方案,同樣無法解決模型的世界觀偏見問題。
英文模型 + 隱式翻譯 + 微調。
在上面方法基礎上,將對齊了text encoder的模型使用中文圖文數據進一步整體微調以提升模型對中文形象的輸出能力。可以在一定程度上緩解英文基底模型帶來的模型偏見問題。
中文數據從頭訓練。
這是最徹底的一種中文化方案:理解中文輸入,並能給出符合中文文化認知的圖像輸出結果,可以完美解決模型的世界觀偏見問題。
上述四種路線,第4種路線看上去非常完美,但仍有一點值得額外的研發努力:在基座模型之外,我們需要進一步考慮的是大模型時代的模型生態問題。
圍繞著以SD為代表的開源模型,已形成了非常龐大的開源社區生態,這個生態中大量衍生風格模型、插件模型等積累了非常寶貴的群體智力資產。
在克服AI繪畫模型世界觀偏見的基礎上,進一步實現對開源社區的兼容,就是我們的BDM工作所要解決的第二個關鍵問題。
BDM從模型結構上是一種類似ControlNet的分支網絡思路,以不同的網絡分支學習不同語言的數據,因此從原理上BDM不僅可以實現原生中文圖像生成,也可以實現任意X語言的圖像生成,並保證生成的圖像符合對應語言文化的認知。
英文部分可以直接複用已有的開源模型,從而實現與開源社區的無縫兼容。注意BDM在使用時只需要輸入一種語言,比如輸入中文時,英文分支是以空文本作為輸入的。
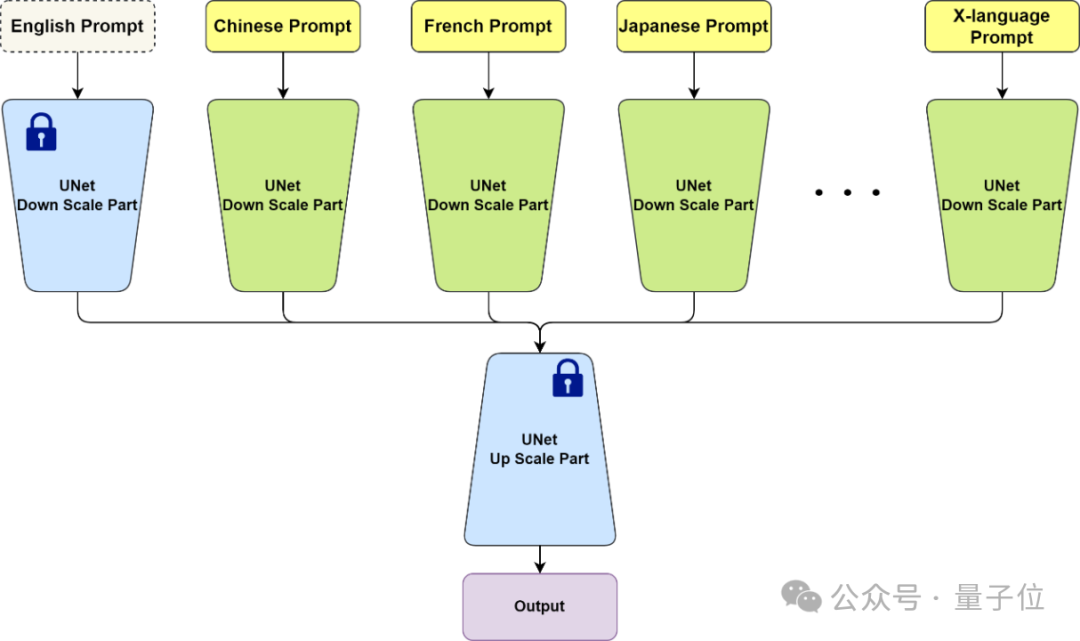
BDM v1版本使用10億量級的中文圖文數據進行訓練,並兼容SD1.5社區生態。
下圖展示了BDM在生成中文特有概念的能力和翻譯無法應對的中英多義情況下的生成效果:

下圖則展示了BDM在SD1.5社區生態兼容性上的情況,可以看到BDM對不同的SD1.5風格微調模型具有很好的兼容性,特別是BDM同時保持了中文形象的輸出能力,更多案例請詳見AAAI論文。

關於360人工智能研究院
在360集團All in AI的大背景下,360人工智能研究院發揮自身的智力優勢,承擔多模態理解和多模態生成大模型(俗稱圖生文和文生圖)的戰略研發任務,並在兩個方向上持續發力,陸續研發了360VL多模態大模型,BDM文生圖模型,可控佈局HiCo模型,以及新一代DiT架構Qihoo-T2X等一系列工作。
近日,研究院在多模態理解方向的工作IAA和在多模態生成方向的工作BDM分別被AI領域的top會議AAAI接收,這兩項工作的研發負責人為冷大煒博士。
據悉本屆AAAI 2025會議收到近1.3萬份投稿,接收3032份工作,接收率僅為23.4%。
Arxiv: https://arxiv.org/abs/2309.00952
Github: https://github.com/360CVGroup/Bridge_Diffusion_Model



















