在卷價格這事上,勸你別拿「豆包」不當乾糧
作者|陶然 編輯|魏曉
大模型應用落地元年最後的一個月,字節旗下豆包大模型再次迎來模型及應用層的全面升級。
先總結兩個關鍵詞:感知世界、回應需求。
12月18日的火山引擎Force冬季大會上,月初接入豆包APP及PC端的視覺理解模型正式發佈,一併亮相的還有圍繞AI視覺理解能力打造的諸多產品應用。

以及,豆包家族其餘模型的大量升級,圖文、代碼、音影片都在射程範圍。

視覺理解模型,通過各AI應用具象成用戶手邊能看見並理解萬物的助理,也成為豆包此次升級最核心的變化。
研究表明,人類接受的所有信息中,有超過80%的部分來自我們的眼睛——來自視覺。
同理,對於旨在無限趨近於人類、成為工作和生活幫手的Agent來說,視覺理解能力也能極大拓展AI技術的應用邊界。
隨著AI與我們的眼睛完成信息對齊,人與AI交互的門檻會將會進一步降低,解鎖更為豐富的應用場景:只要能看見,都可以問AI。
從理解信息
到理解世界
先說下大會開場給的一段測試案例,場景為火山引擎公司辦公區。
這次測試預先載入了火山引擎企業知識庫,相當於給模型圈定了一個大概的考試範圍,即問答題目大多會是公司相關內容。

而視覺理解模型,就是要通過理解攝像頭所看到的內容,查找並調用這個企業知識庫信息,給出回答。比如,畫面中這個公司logo擺件散了,怎麼拚回去。

模型準確理解了三維空間中前後左右等等位置信息,和擺件之前的物理狀態,最終給出了具體的組裝方案。以此類推,載入火山引擎知識庫能拚擺件,載入傢俱品牌知識庫理論上就能決絕動手能力不足群體看不懂說明書、拚不上傢俱的問題。

還能,讀懂體檢報告再給出生活建議;

還能,讀懂代碼並提出修改意見;

再比如,通過圖片瞭解到用戶此刻正在火山引擎大樓,從這裏到北京南站要40分鐘車程。


倘若這項功能可以與具體城市、地區的高精地圖聯動,顯然就會是路癡人群福音,被動導航從此升級為主動導航。
火山引擎總裁譚待在採訪中表示,推出視覺理解模型相當於解鎖了一個很大的場景,同過去只有文字對話形式的AI相比,聊天功能與深度推理的、圖像視覺理解等能力的融合,能讓模型有能力處理好真實世界大量綜合性的信息,輔助人類完成一系列複雜工作。
「語言是來描述世界的,首先你理解這個事情得靠視覺。就像我們今天坐在一起聊一些事情,都得是你看得到它、感覺得到它,說出它的信息再來交互。」

由功能增強帶來的應用拓展,也會對大模型的調用量和場景帶來大幅提升。
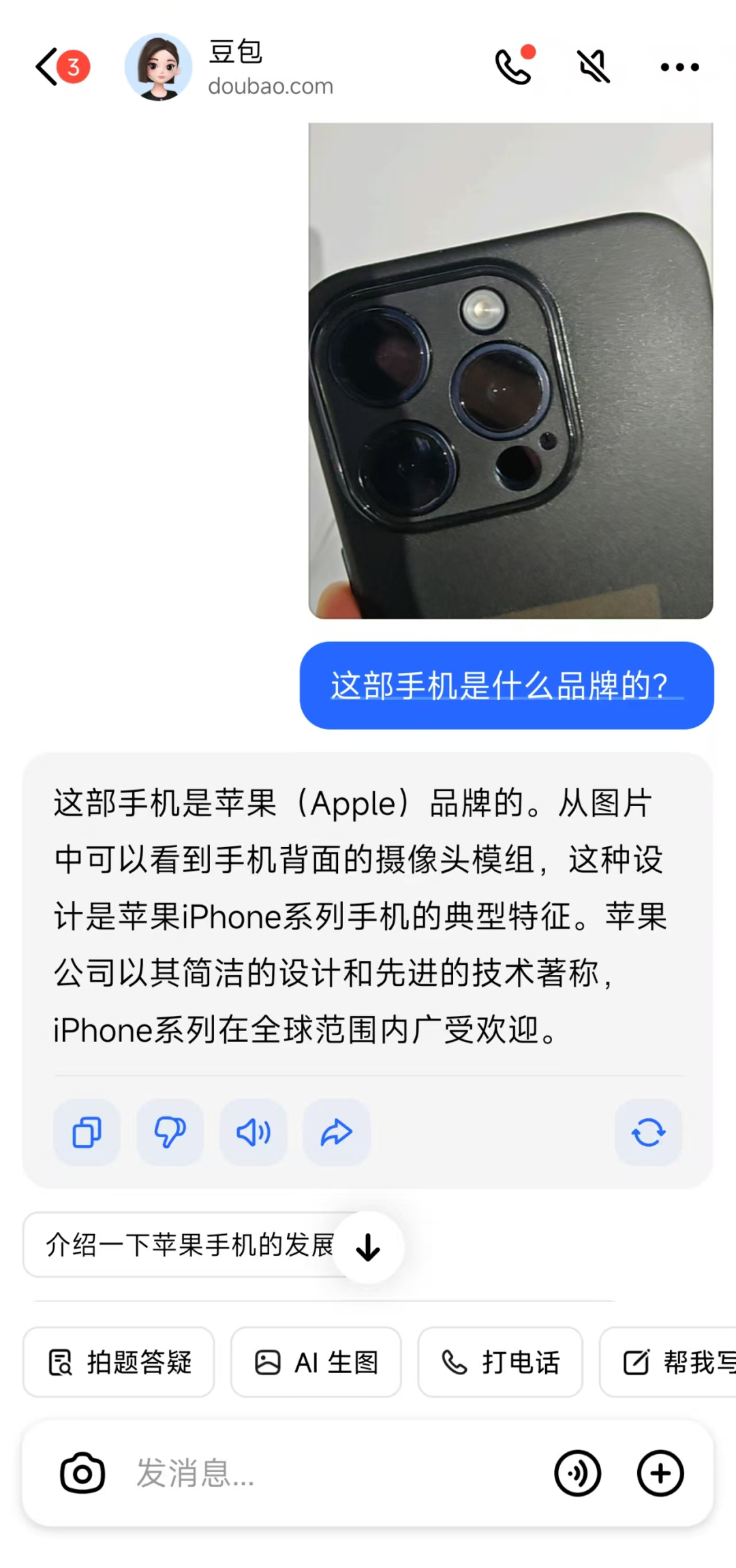 圖/AI藍媒彙現場測試識圖功能
圖/AI藍媒彙現場測試識圖功能能看懂世界的大模型,離「全知全能「的AI助理又近一步。
即夢
更值得期待了
前段時間,坊間曾傳出「字節已經提升了剪映即夢業務的產品優先級,計劃後續把更多資源向更多模態的產品形態轉移到該業務」的流言。
本次大會,剪映業務負責人張楠同樣登台演講,內容基本圍繞即夢展開。即夢,是張楠由抖音集團CEO改任剪映團隊一號位之後推出的AI創作工具和社區,於2024年5月上線,包括智能畫布、文生圖/圖生圖、對口型、運鏡調節等大量AI技術已在其圖片、影片創作功能中落地。

得益於底層模型多模態,尤其是視覺能力的升級,即夢後續的發展空間顯然會進一步拓展。
會上,張楠分享了兩位即夢創作者用AI創作的短片,一部借聚光燈下大螢幕女明星的奇幻故事還原了從默片到有聲時代、從黑白到彩色的電影發展史;另一部來自今年7月在抖音上線的科幻短劇《覺醒》。據稱,該科幻短劇一經上線就吸引了許多關注與討論,也成為抖音上首部單日點讚破40萬的AI短劇。
如果說抖音是記錄和分享「真實世界」的相機,那麼即夢就是呈現「想像力的相機」。產品的靈感來自OpenAI先前發佈的DALL-E 2模型,張楠希望用戶「只需要輸入某一刻的想法,借助 GenAI 的技術,畫面就可以瞬間被呈現在眼前。」

基於字節自研的豆包·文生圖模型、豆包·影片生成模型,即夢AI近期上線了三款各具特色的影片生成模型,並接入了最新的豆包·文生圖模型,業內首創了「一句話P圖」、「一鍵海報」和「動態海報」能力,並大幅提升了困擾行業多時的文字生成準確率難題,靈活且精準的圖片創作編輯從此成為現實。

不管是畫面的完成度,還是文字生成的質量,可以說這就是目前國產大模型的t0,中文文字生成的標杆。
依舊是價格屠夫
當然,該卷的地方,還是要卷的。
橫向比較,豆包在整個大模型賽道可以算姍姍來遲,今年5月才正式發佈。但,第一個特點就是後來居上:發佈之初的模型日均tokens是1200億。7月份漲到了5000億,9月份達到1.3萬億;而截止到上週日,12月15號,豆包大模型的日均tokens數已經突破了4萬億,在7個月的時間里增長超過33倍。
第二個特點,則是整頓行業定價:豆包發佈之初,捅破地板的模型價格把行業定價降低了99%,也掀起了第一輪大模型集體降價潮,用譚待的話說,是「降低到一個合理水平,讓企業可以放心大膽的去做大模型應用創新。」
這次上架視覺理解模型,豆包又一次當起了價格屠夫:目前,Claude的價格是每千token 兩分一里錢;GPT-4o的價格,是每千Tokens 一分七厘。阿里的通義千問的價格,是每千Tokens 2分錢。
而豆包,把這個價格殺到了「每千tokens 3厘錢」,再次比行業平均價格降低85%。相當於一塊錢可以處理284張720P的圖片。

視覺理解模型賽道也被豆包帶入了厘時代,「好模型就是要讓每家企業都用得起」。
現在來看,大模型或許會是一個比手機、比新能源更加「贏者通吃」,所以更需要所謂「終局思維」的賽道:scaling law路線下不斷擴大的是模型能力,也是訓練成本,只有產品力足夠強,客源足夠多,且有資源撐到最後的極少數玩家才能倖存。
豆包,顯然是最夠拚,目前也足夠強:綜合目前行業數據,豆包在國內目前以接近900萬的DAU遙遙領先於第二名的Kimi(300萬);甚至,在全球範圍內,豆包約6000萬的月活也僅次於OpenAI的ChatGPT,居全球第二。
並且,視覺理解等模型下一步的應用場景也在打開:會上演示的模型理解案例中,豆包大模型在接收到高跟鞋推薦相關問題後,自動連接到了似乎是抖音電商的相關購物推薦界面。
這種連接和傳統廣告營銷的「硬塞」完全不同,AI做的是理解並回應用戶需求。何況,豆包能理解的場景不只局限於是電商,畢竟字節旗下還有內容平台,還有教育等等。

足夠豐富的內部生態、足夠多的優質數據和應用場景,且都全面接入AI並相互打通,才是豆包成為行業「卷王」的秘訣。