諾獎得主David Baker:AI for Science的13片藍海
隨著過去2年AI的快速發展,大模型的C端應用層出不窮,深入人心。與之相比,AI for Science一直披著神秘的面紗。
最近。AI業界的觀點開始產生變化,Jason Wei明確指出AI for Science蘊藏著巨大的機遇,而其中最大的場景在於AlphaFold 2掀起的蛋白質革命。
近日,2024年盧保化學獎得主David Baker進行了一場題為《De Novo Protein Design》的精彩演講,站在科研最前沿為我們揭開了謎底:AI for Science究竟有哪些應用場景,能帶來哪些實際價值。
David Baker預測,在接下來的5~10年內,我們將會看到各種全新的人工合成蛋白質在AI大模型的幫助下誕生,解決包括癌症、自體免疫疾病、阿茲海默症在內的醫學難題,同時在生物電子、催化劑合成、太陽能採集等領域大展拳腳。
文章有點硬核,但內容重要性很高,建議耐性閱讀,也可以收藏起來慢慢看。
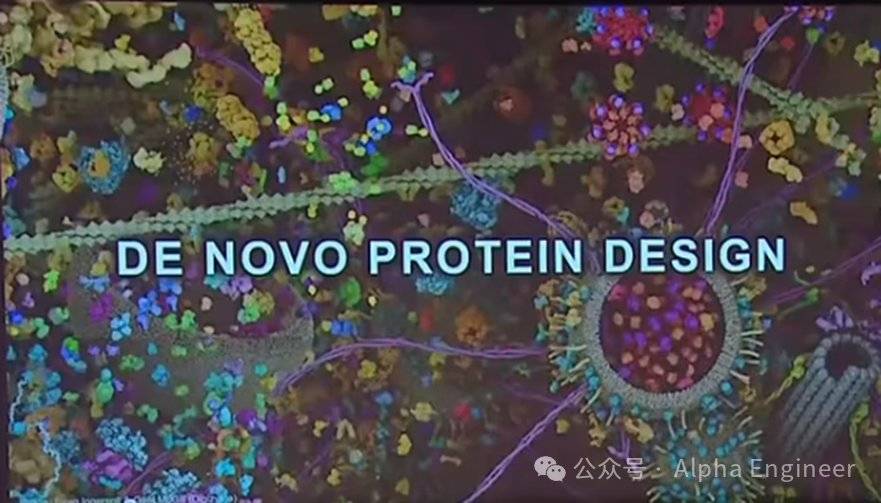
一、Sequence ← → 3D Structure:蛋白質領域的雙生難題
2024年的盧保化學獎集中在兩大領域:Computational Protein Design,Protein Structure Prediction,二者其實是一體兩面的雙生問題。
眾所周知,肽鏈會摺疊成複雜的三維結構,這種三維結構以某種方式編碼在構成肽鏈的氨基酸序列中。也就是說,氨基酸的線性序列決定了蛋白質的三維結構。
因為這個重要發現,Christian Anfinsen在1972年被授予盧保化學獎。
這意味著,原則上我們可以根據氨基酸序列直接預測三維結構。反之亦然,給定一個具體的蛋白質三維結構,理論上我們可以反推出構成這個蛋白質的氨基酸序列。
這一正一反兩個問題就是蛋白質研究的核心。
-
3D Structure -> Sequence,稱為Computational Protein Design;
-
Sequence -> 3D Sequence,稱為Protein Structure Prediction。
「蛋白質設計」這一挑戰在2003年被David Baker攻克,他設計出了一種包含93個氨基酸的全新蛋白質,並且計算出氨基酸序列。隨後他們在實驗室合成了這種蛋白質,並證明了預測的正確性。
與此相對,根據氨基酸序列預測蛋白質的三維結構是一個龐大的搜索問題,這點早在1960年就被Cyrus Leventhal指出。
幾十年以來,這個領域的進展十分緩慢,但是Denis Hassabis以及John Jump在2020年通過訓練神經網絡模型成功解決了這個問題。
如今AlphaFold2能夠準確地預測氨基酸序列之間的距離圖,並進一步轉化為三維結構,實現蛋白質結構的準確預測。
二、蛋白質的誕生:自然進化 or AI合成
蛋白質是生命通過數十億年逐漸進化而來的,它們就像微型機器人,在生命體中承擔著各種各樣的重要職能。
但隨著近年來人均壽命不斷提高,人類面臨著包括癌症、神經退行性疾病、全球變暖等全新挑戰。
如果還是依靠大自然進化出全新的蛋白質來解決這些問題,恐怕要等上數億年的時間。
但如果我們能夠按需設計出蛋白質,便能在短短幾年內取得突破性成果,這就是蛋白質設計的價值。
在蛋白質設計中,我們先構建出一個預計具有某種特定功能的蛋白質,隨後計算出這個蛋白質對應的氨基酸序列。
由於這是個全新的蛋白質,大自然中不存在能夠編碼它的基因,人們需要製造一個合成基因,一個能夠編碼這個蛋白質的合成DNA片段。
隨後將其放入細菌中,細菌充當生產蛋白質的工廠,最後我們把蛋白質提取出來,測試它是否滿足預期的功能需求。
三、潛在未被發掘的蛋白質數量是個天文數字
一個典型的蛋白質包含100多個氨基酸構成的序列,而氨基酸本身就有20種。這意味著潛在蛋白質的種類有至少20^100次方個,這是一個天文數字。
生命自然進化中誕生的蛋白質只是其中非常非常微小的一部分。下圖中灰色的區域表示潛在的蛋白質空間,紅色的區域是大自然中存在的蛋白質種類。
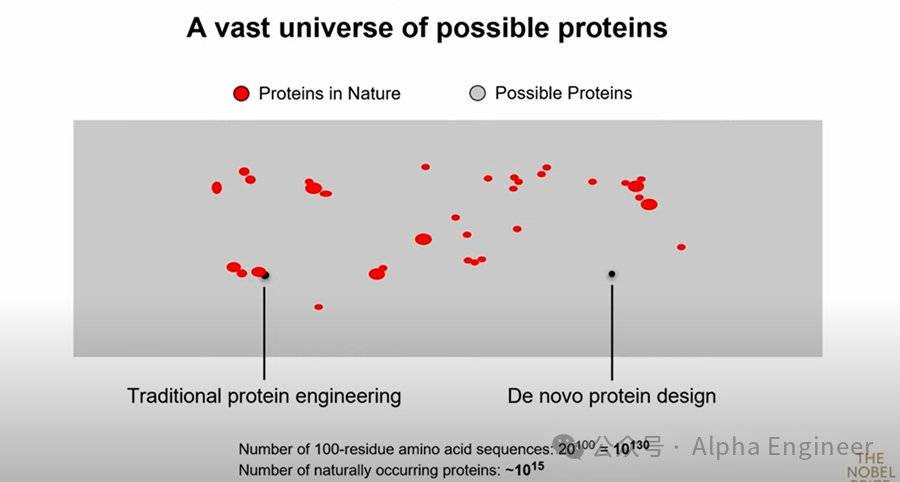
由於生命進化是漸進的,大自然中存在的蛋白質之間往往存在較高的相關性,比如我們人類體內的蛋白質和其他哺乳動物中的蛋白質就高度相似,所以圖中的紅點呈現聚集性的特徵。
因此當科學家想要設計一種新蛋白質時,傳統方法是先去大自然中看看,有沒有性狀相似的蛋白質,在它基礎上做微創新,這種做法稱為「生物勘探」(Bio Prospecting)。
但這種做法有很多問題。首先大自然中存在的蛋白質種類有限,能實現的功能也有限,當我們想要實現一些特殊功能時,可能沒有近似的自然蛋白質可供勘探。與此同時,大自然中存在的蛋白質結構非常複雜,在一個複雜系統上進行微創新可不容易,就像在幾百萬行的軟件代碼中debug一樣。
四、RF Diffusion:像生成圖片一樣生成蛋白質
近年來人們開始使用RF Diffusion方法來進行蛋白質設計,這種算法其實是受到了圖像生成算法的啟發。
在Diffusion算法中,人們先往圖片里添加不同的噪聲,然後訓練一個神經網絡來去除噪聲還原圖片。
一旦這個神經網絡能夠完美的去除噪聲,它就可以從完全隨機的噪聲像素點開始,逐步去除噪聲,生成一副全新的圖像。
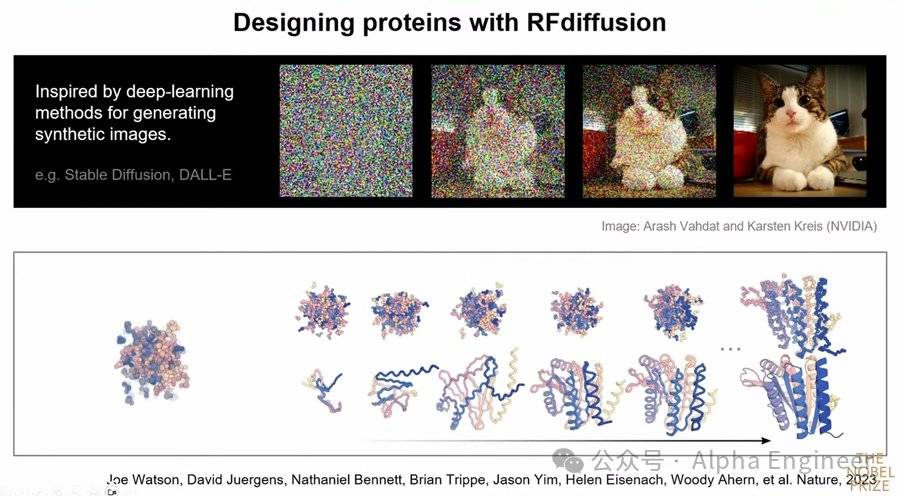
RF Diffusion算法的原理與之高度相似。首先我們從PDB中提取海量蛋白質結構數據,往裡面注入越來越多的噪聲,然後訓練一個神經網絡來去除蛋白質結構數據中的噪聲。
訓練完成後,我們可以從完全隨機的氨基酸配置開始,逐步去除噪聲,生成一個全新的蛋白質結構。
正如在生成圖片的時候,我們可以通過Prompt、Lora等方法來限制想要生成圖片的內容。在生成蛋白質的時候,我們也可以加上限制條件,來產生具備某些功能性狀的蛋白質。
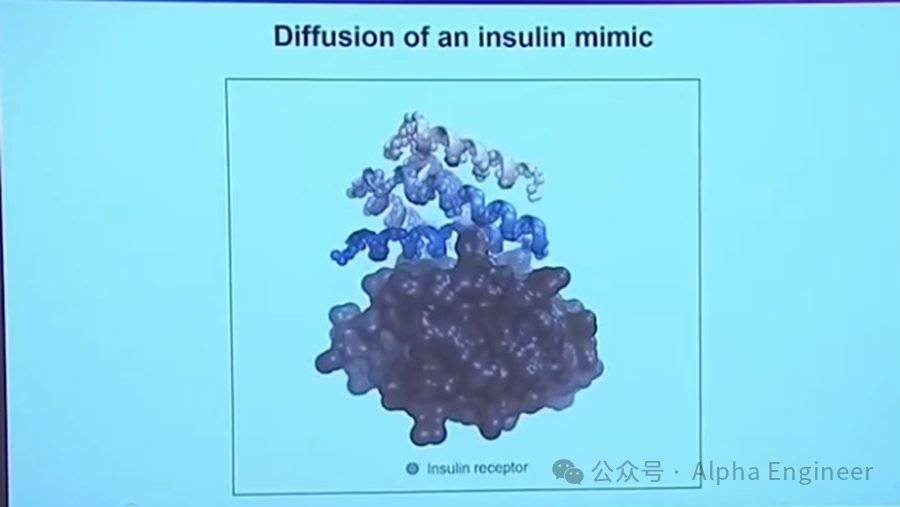
比如下圖展示的是在給定胰島素受體的前提下,合成能夠與之結合的蛋白質。在訓練過程中,神經網絡已經學會蛋白質之間的形狀互補特徵,因此能夠合成出完美契合靶點的蛋白質。目前科學家已經設計出能夠與200多種靶點結合的蛋白質。
接下來我們來探討蛋白質設計的應用價值,共計13個場景,分別對應醫藥、電子科技、可持續發展這三大領域。
五、蛋白質 × 新藥研發:蛇毒疫苗
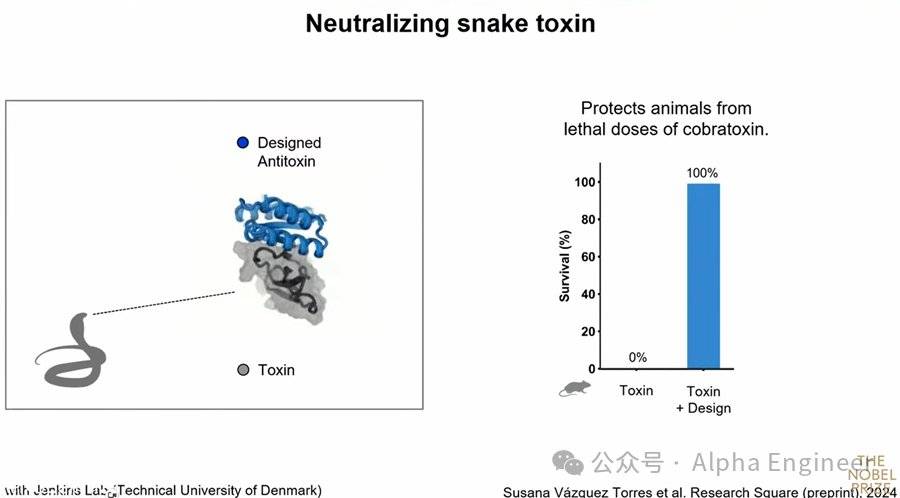
蛇毒目前依然是一個重要的醫學問題,尤其在發展中國家,因為蛇毒能夠直接干擾基礎生化反應。
蛇毒疫苗必須有著足夠穩定的化學性質,並且足夠便宜,因為它需要在那些沒有冷鏈運輸的國家使用。
左邊圖中藍色的部分是AI設計出的蛋白質,它能夠和蛇毒完美結合,把它注射到小鼠體內後,蛇毒被完全緩解,死亡率從100%降低到0%。
六、蛋白質×新藥研發:自體免疫疾病
炎症是當前醫療領域的重點話題,它與自體免疫、癌症腫瘤都有較大關聯。
炎症的核心是一種稱為TNF受體的蛋白質,它也是目前市場上很多藥物的靶點。
下圖左側是根據TNF受體生成出來的蛋白質,將其注入動物體內能夠有效抑制炎症。
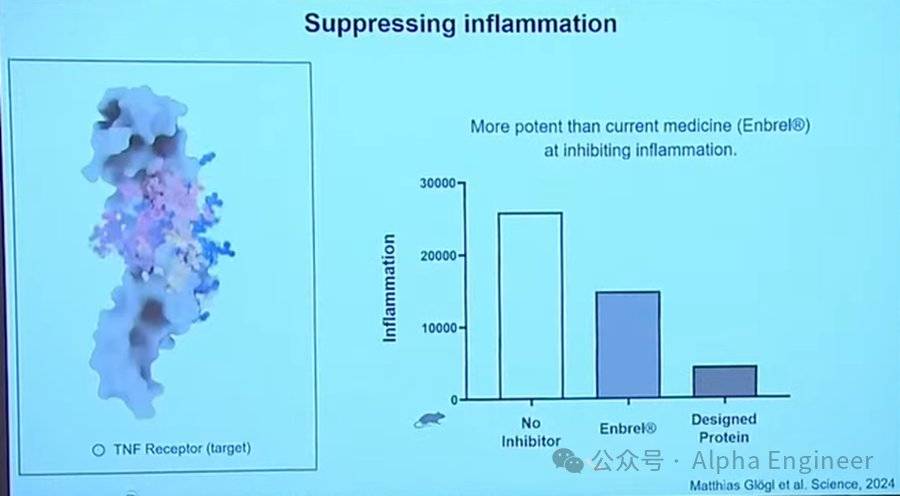
當前用於治療炎症的藥物比如Enbrel(依那西普)有一定效果,但AI合成的蛋白質和受體結合得更加緊密,因此抗炎效果更好。
這意味著在不久的將來,人們能夠設計出全新的藥物治療多種自體免疫疾病。
七、蛋白質×新藥研發:癌症腫瘤治療
癌症治療是蛋白質設計發光發熱的重點領域。如今科學家可以設計全新的蛋白質來激活免疫系統,從而治療癌症。
下圖左側紅色的蛋白質將兩個免疫受體結合在一起,從而引起免疫系統的強烈激活。
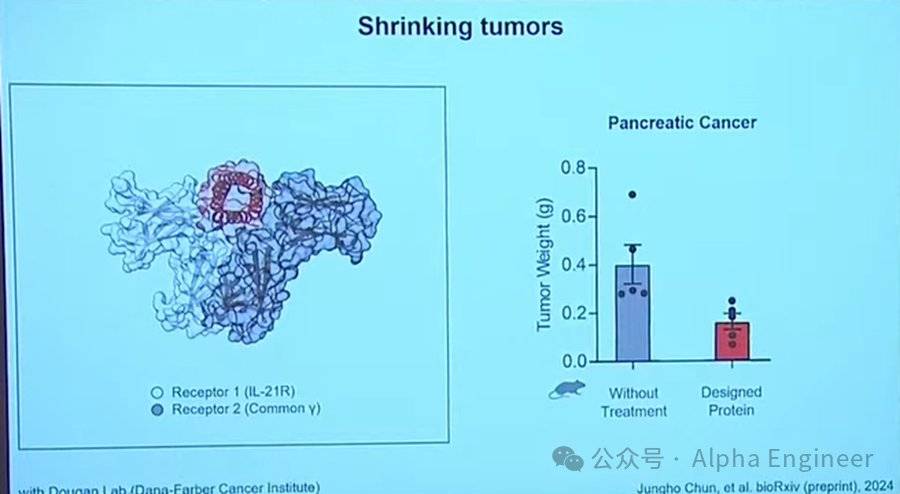
在治療胰腺癌的實驗中,該方法相比傳統治療方法取得了更好的成果,腫瘤顯著縮小。
八、蛋白質×新藥研發:流行病抗體
下圖左側灰色的部分是流感病毒表面蛋白,我們可以在它上面用AI生成一個結合蛋白質。
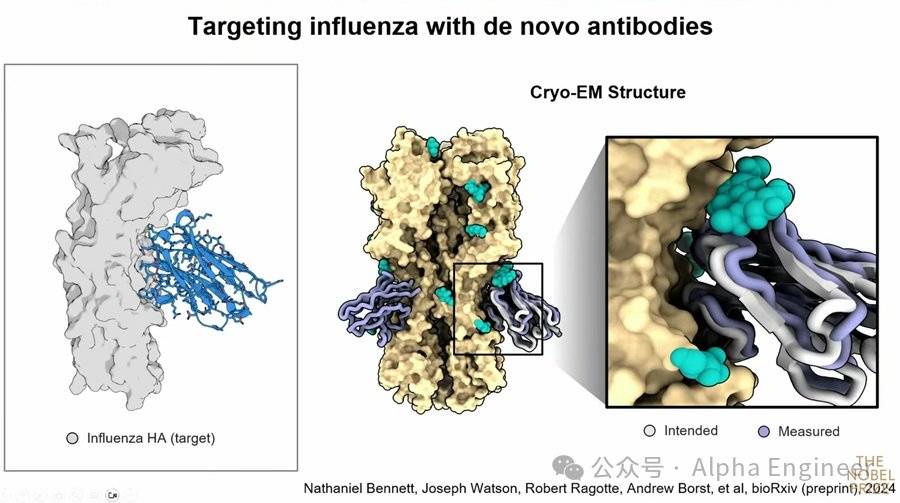
在生成的時候,我們可以加上一個限制條件:我們希望這個蛋白質成為一種抗體,即一種特殊類型的蛋白質摺疊。
上面右圖中紫色部分是實驗室測得的抗體蛋白質結構,灰色的部分是模型生成的蛋白質結構,二者幾乎完全一致。
抗體是通過CDR Loop來識別目標的,通過神經網絡合成出的抗體蛋白質完美模擬了CDR Loop,而且能夠與流感病毒表面蛋白緊密結合,因此具備良好的抗體效果。
其實基於蛋白質設計的流行病抗體研發早已進入我們的日常生活。
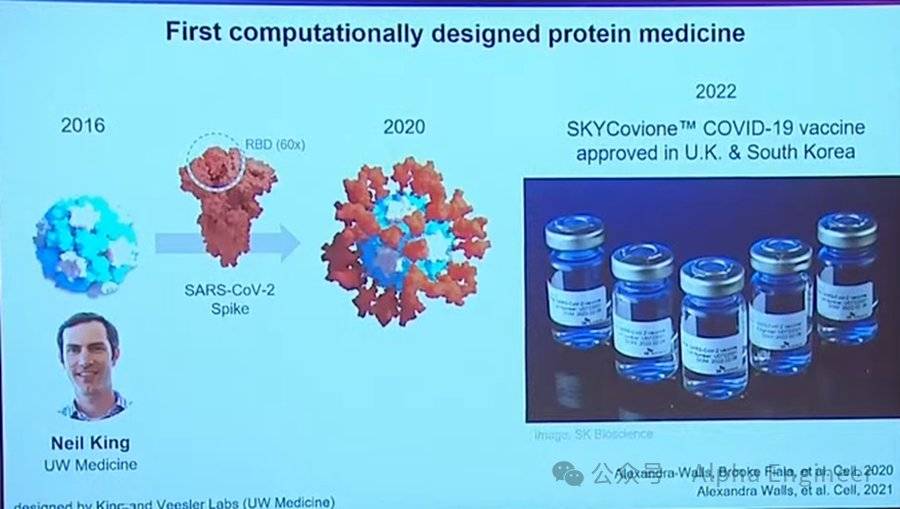
早在2016年,Neil King開始嘗試製作自組裝的納米顆粒,成功製作之後他意識到可以將一些病毒蛋白片段放在上面來生產疫苗。
基於這個想法,在Covid期間,它在這些納米顆粒上放置了Covid表面蛋白受體,他發現這能引發非常強烈的免疫反應。
基於這項研究,SKYCovione誕生了,它是一種臨床獲批的藥物。在未來的幾年內,會有越來越多類似的新藥誕生。
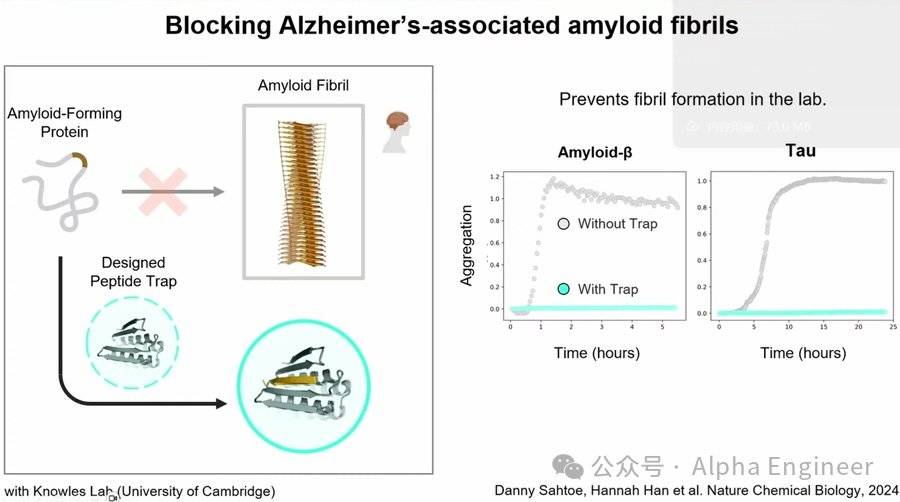
九、蛋白質×新藥研發:阿茲海默症
另一個越來越重要的醫學問題是神經退行性疾病,如阿爾茲海默症,它與長澱粉樣纖維(long amyloid fibrils)的形成有關。
長澱粉樣纖維的形成過程涉及多種蛋白質,包括Amyloid β以及Tau蛋白,它們之間會互相結合從而形成長澱粉樣纖維。
我們可以設計出一種全新的蛋白質,與這些蛋白質的無序部分相結合,這樣就可以阻止澱粉樣蛋白的形成,從而避免阿茲海默症的發生。
以上我們對AI for Science在新藥研發上的潛在應用價值進行了梳理。
下一篇文章我會給大家深入解讀AI合成蛋白質在分子傳感器、DNA測序、太陽能採集、催化劑合成、半導體生長等重要領域取得的突破性進展。
本文來自: Alpha Engineer,作者:費斌傑(北京市青聯委員,熵簡科技CEO)