UniReal登場:用影片架構統一圖像生成與編輯,還學到真實世界動態變化規律
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
論文一作陳汐,現為香港大學三年級博士生,在此之前本科碩士畢業於浙江大學,同時獲得法國馬賽中央理工雙碩士學位。主要研究方向為圖像影片生成與理解,在領域內頂級期刊會議上發表論文十餘篇,並且 GitHub 開源項目獲得超過 5K star.
本文中,香港大學與 Adobe 聯合提知名為 UniReal 的全新圖像編輯與生成範式。該方法將多種圖像任務統一到影片生成框架中,通過將不同類別和數量的輸入/輸出圖像建模為影片幀,從大規模真實影片數據中學習屬性、姿態、光照等多種變化規律,從而實現高保真的生成效果。
-
論文標題:UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
-
項目主頁:https://xavierchen34.github.io/UniReal-Page/
-
論文鏈接:https://arxiv.org/abs/2412.07774
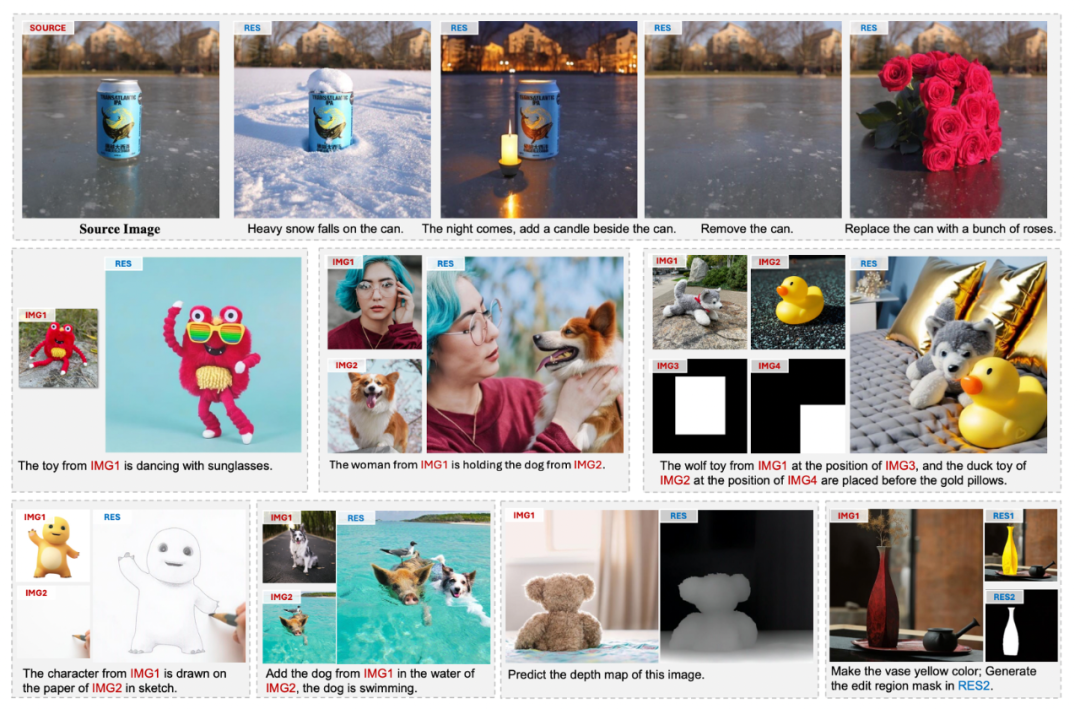
效果展示
我們重點展示了圖像生成與編輯中最具挑戰性的三個任務的效果:圖像定製化生成、指令編輯和物體插入。
此外,UniReal 還支持多種圖像生成、編輯及感知任務,例如文本生成圖像、可控圖像生成、圖像修復、深度估計和目標分割等。
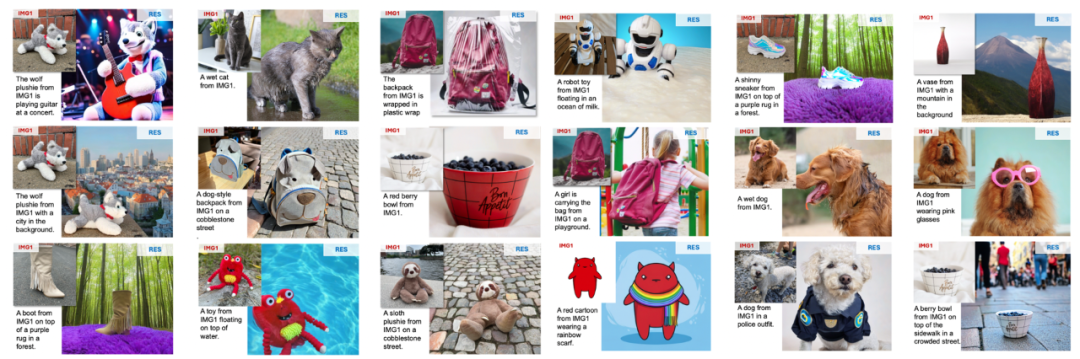
在單目標定製化生成任務中,UniReal 能夠在準確保留目標細節(如 logo)的同時,生成具有較大姿態和場景變化的圖像,並自然地模擬物體在不同環境下的狀態,從而實現高質量的生成效果。

與此同時,UniReal 展現了強大的多目標組合能力,能夠精確建模不同物體之間的交互關係,生成高度協調且逼真的圖像效果。

值得注意的是,我們並未專門收集人像數據進行訓練,UniReal 仍能夠生成自然且真實的全身像定製化效果,展現了其出色的泛化能力。
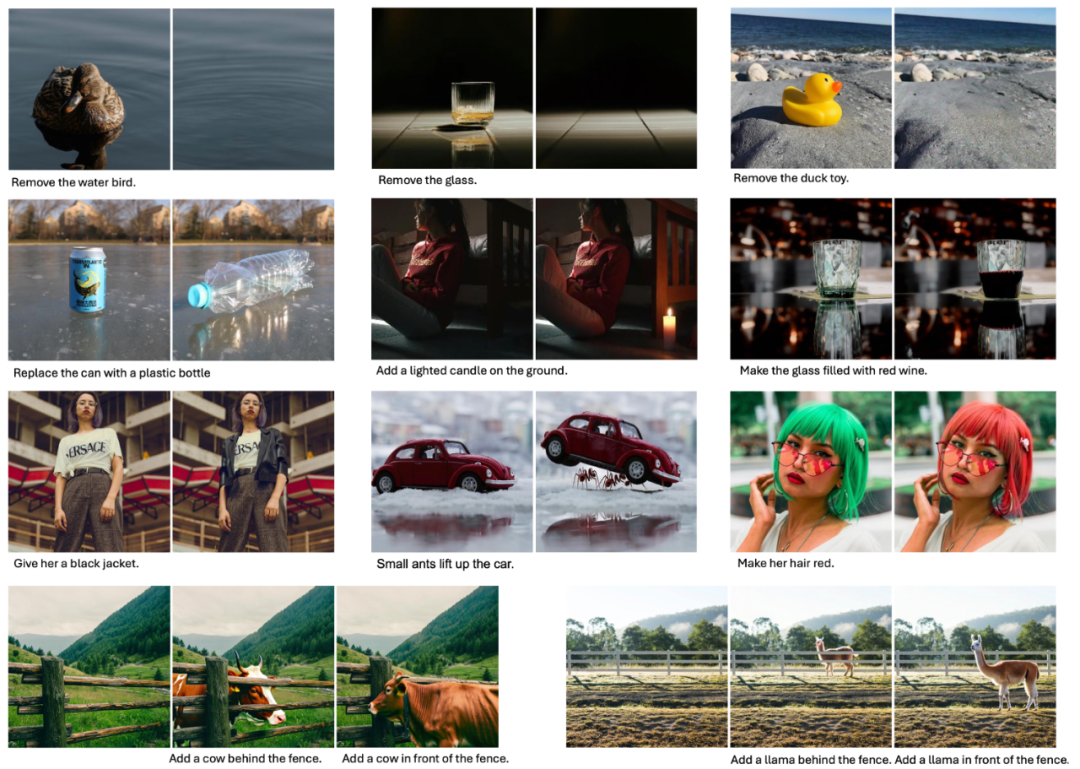
在指令編輯方面,UniReal 支持用戶通過自由輸入文本對圖像進行靈活編輯,例如添加或刪除物體、修改屬性等。實驗結果表明,UniReal 展現出了卓越的場景理解能力,能夠真實地模擬物體的陰影、反射以及前後遮擋關係,生成高度逼真的編輯效果。

UniReal 支持從圖像中提取特定目標作為前景,插入到背景圖像中,天然適用於虛擬試衣、Logo 遷移、物體傳送等任務。實驗表明,UniReal 插入的目標能夠非常自然地融入背景圖像,呈現出與背景一致的和諧角度、倒影效果及環境匹配度,顯著提升了任務的生成質量。
除了上述任務外,UniReal 還支持文本生成圖像、可控圖像生成、參考式圖像補全、目標分割、深度估計等多種任務,並能夠同時生成多張圖像。此外,UniReal 支持各類任務的相互組合,從而展現出許多未經過專門訓練的強大能力,進一步證明其通用性和擴展性。
方法介紹
UniReal 的目標是為圖像生成與編輯任務構建一個統一框架。我們觀察到,不同任務通常存在多樣化的輸入輸出圖像種類與數量,以及各自獨特的具體要求。然而,這些任務之間共享一個核心需求:在保持輸入輸出圖像一致性的同時,根據控制信號建模圖像的變化。
這一需求與影片生成任務有天然的契合性。影片生成需要同時滿足幀間內容的一致性與運動變化,並能夠支持不同的幀數輸出。受到近期類似 Sora 的影片生成模型所取得優異效果的啟發,我們提出將不同的圖像生成與編輯任務統一到影片生成架構中。
此外,考慮到影片中自然包含真實世界中多樣化的動態變化,我們直接從原始影片出發,構建大規模訓練數據,使模型能夠學習和模擬真實世界的變化規律,從而實現高保真的生成與編輯效果。
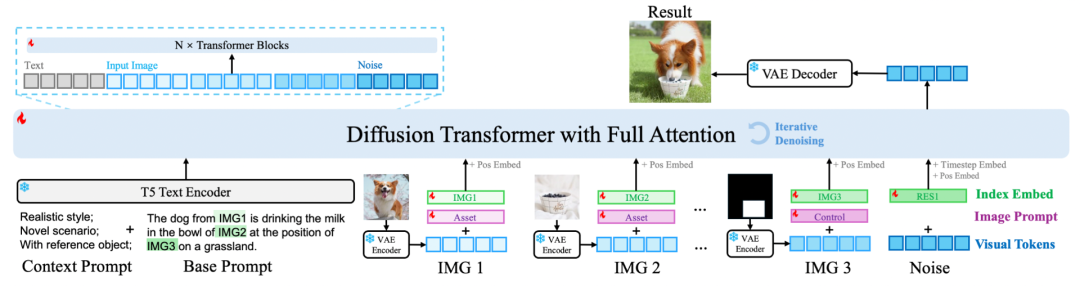
模型結構:我們借鑒了與 Sora 類似的影片生成架構,將不同的輸入輸出圖像統一視作影片幀處理。具體來說,圖像通過 VAE 編碼後被轉換為視覺 token,接著輸入 Transformer 進行處理。與此同時,我們引入了 T5 text encoder 對輸入指令進行編碼,將生成的文本 token 與視覺 token 一同輸入 Transformer。通過使用 full attention 機制,模型能夠充分建模視覺和文本之間的關係,實現跨模態信息的高效融合和綜合理解。這種設計確保了模型在處理多樣化任務時的靈活性和生成效果的一致性。
層級化提示:為瞭解決不同任務和數據之間的衝突問題,同時支持多樣化的任務與數據,我們提出了一種 Hierarchical Prompt(層級化提示)設計。在傳統提示詞(Prompt)的基礎上,引入了 Context Prompt 和 Image Prompt 兩個新組件。
-
Context Prompt:用於補充描述不同任務和數據集的特性,包括任務目標、數據分特點等背景信息,從而為模型提供更豐富的上下文理解。
-
Image Prompt:對輸入圖像進行層次化劃分,將其分為三類:
-
Asset(前景):需要重點操作或變更的目標區域;
-
Canvas(畫布):作為生成或編輯的背景場景;
-
Control(控制):提供約束或引導的輸入信號,如參考圖像或控制參數。
為每種類別的輸入圖像單獨訓練不同的 embedding,從而幫助模型在聯合訓練中區分輸入圖像的作用和語義,避免不同任務和數據引發的衝突與歧義。
通過這種層級化提示設計,模型能夠更高效地整合多樣化的任務和數據,顯著提升聯合訓練的效果,進一步增強其生成和編輯能力。
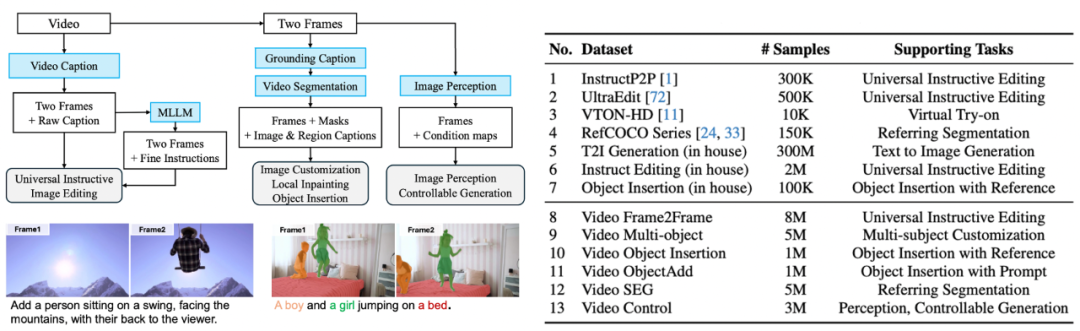
數據構造:我們基於原始影片數據構建了大規模訓練數據集,以支持多樣化的任務需求。具體步驟如下:
1.編輯數據生成
從影片中隨機抽取前後兩幀,分別作為編輯前和編輯後的圖像結果,並借助視覺語言模型(VLM)生成對應的編輯指令,以模擬多樣化的圖像編輯任務。
2.多目標定製化生成
我們結合 VLM 與 SAM2,在影片首幀中分割出不同的目標區域,並利用這些目標區域重建後續幀,構造多目標定製化生成的數據。這種方式能夠模擬目標在複雜場景中的動態變化,並為多目標生成任務提供高質量的數據支持。
3.可控生成與圖像理解標註
利用一系列圖像理解模型(如深度估計模型)對影片和圖像進行自動打標。這些標籤不僅為可控生成任務(如深度控制生成)提供了豐富的條件信息,還為圖像理解任務(如深度估計、目標分割)提供了標準參考。
通過這種基於原始影片的多層次數據構造策略,我們的模型能夠學習真實世界中的動態變化規律,同時支持多種複雜的圖像生成與理解任務,顯著提升了數據集的多樣性和模型的泛化能力。
效果對比
在指令編輯任務中,UniReal 能夠更好地保持背景像素的一致性,同時完成更具挑戰性的編輯任務。例如,它可以根據用戶指令生成 「螞蟻抬起轎車」 的畫面,並在轎車被抬起後動態調整冰面上的反射,使其與場景的物理變化相一致。這種能力充分展現了 UniReal 在場景理解和細節生成上的強大性能。

在定製化生成任務中,無論是細節的精確保留還是對指令的準確執行,UniReal 都展現出了顯著的優勢。其生成結果不僅能夠忠實還原目標細節,還能靈活響應多樣化的指令需求,體現出卓越的生成能力和任務適應性。

在物體插入任務中,我們與此前的代表性方法 AnyDoor 進行了對比,UniReal 展現出了更強的環境理解能力。例如,它能夠正確模擬狗在水中的姿態,自動調整易拉罐在桌子上的視角,以及精確建模衣服在模特身上的狀態,同時保留模特的頭髮細節。這種對場景和物體關係的高度理解,使 UniReal 在生成真實感和一致性上遠超現有方法。

未來展望
UniReal 在多個任務中展現了強大的潛力。然而,隨著輸入和輸出圖像數量的進一步擴大,訓練與推理效率問題成為需要解決的關鍵挑戰。為此,我們計劃探索設計更高效的注意力結構,以降低計算成本並提高處理速度。同時,我們還將這一方案進一步擴展到影片生成與編輯任務中,利用高效的結構應對更複雜的數據規模和動態場景需求,推動模型性能與實用性的全面提升。



















