OpenAI o3 詳解:並非 AGI,比 o1 貴 1000倍(另附內測申請)
今日發佈
o3
o3 – 更強的 o1
按計算量:1000 倍的成本
(o3-high 對比 o1-high)
根據 ARC-AGI 測試標準
單任務成本,大概 3500 美金
問一句「9.09 和 9.11 誰更大」
2萬人民幣就沒了
模型的代號為 α
也可以叫他獵戶座
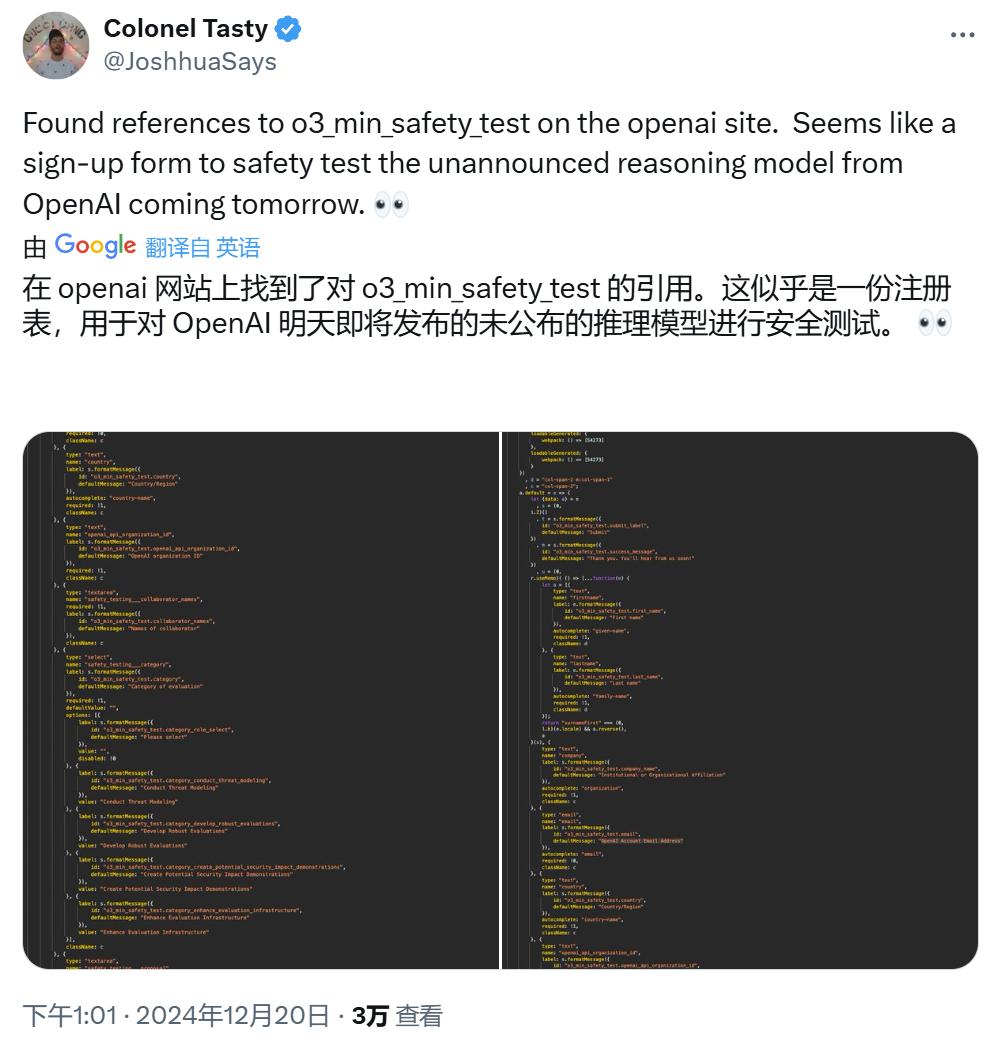
模型尚未開放
可在這裏申請內測
https://openai.com/index/early-access-for-safety-testing/
之後會有一個縮水版的 o3-mini
預計明年 1 月底開放
接下來
我們先談成績
再說問題
很會編程
在編程領域,非常優秀
Codeforces 2727 分

2727 分
相當於 CF 編程大神榜單 175 名

怎麼評價呢
OpenAI 現任首席科學家
以前也是玩 Codeforces 的
歷史最高得分是 2655

很會數學
在數學難題解答上
也是遙遙領先
Frontier Math
包含一個數據集
裡面都是未發佈的超高難度數學問題
即便是優秀的專業人員
解答其中的一個問題
也需要數小時到數天
在之前的測試中
AI 的最好成績是解決了 2% 的問題
而 o3 解決了 25.2% 的問題

再說問題
很貴
非常離譜的貴
o 系列模型
會有多種算力模式
比如:low/medium/high

在 ARC-AGI 測試中
對於 o3 – low
單任務成本約 20 美金
是 o1 – low 的 10 倍
對於 o3 – high
單任務成本約 3500 美金
是 o1-high 的 2000 倍

以上數據,來源 ARC
注意:o3-high 價格尚未確定,根據計算量進行成本推算
並非 AGI
上面提到的 ARC
是 OpenAI 的新晉測試夥伴
提供關於 AGI 的測試基準
(馬上我會詳細講)
雖然 o3 在這個測試中
取得了不錯的成績
但遠達不到 AGI 的標準
ARC 的官方說法是這樣
I don’t think o3 is AGI yet
我不認為 o3 是 AGI
o3 still fails on some very easy tasks
o3 在很多簡單問題上,做得很差。
indicating fundamental differences with human intelligence
這說明他和人類之間還是有根本性差距的
同時,ARC 官方也表示
在第2版榜單里
人類的基準成績是 95%
而 o3 的成績會跌到不到 30%
說說 ARC-AGI
這是 Keras 創始人 Chollet,在 2019 年搞出來的一個基準測試,來測測 AI 到底有多會”學習”。最開始發表在論文《On the Measure of Intelligence》。
https://arxiv.org/abs/1911.01547
怎麼測的
給被測試的 AI,一些彩色網格的示例對。然後再給一個新的輸入,讓他預測輸出。

每個格子可以是十種顏色之一,網格大小從 1×1 到 30×30 不等。
目前,o1 的正確率在 30% 左右,o3-high 則達到了 88%。
在定向任務的團隊中,目前的最好成績是 the ARChitects,正確率 53.5%。
代碼:
https://www.kaggle.com/code/gregkamradt/arc-prize-v8?scriptVersionId=211457842
論文:
https://github.com/da-fr/arc-prize-2024/blob/main/the_architects.pdf
為什麼有這個測試
對於 AGI 是什麼,有很多種表述,一個主流的說法是”能把大部分有經濟價值工作,進行自動化的系統”。
Chollet 覺得,這個定義有點偏離:真正的智能不是你會多少技能,而是你有多會學習。畢竟,現在的大模型,你只要給他足夠的數據,他就會有對應的技能,看不出到底有多聰明。
於是 Chollet 搞出來了這個 ARC-AGI 的基準測試,用來評估那些 「沒有出現過的問題」,也是目前唯一一個專門測量 AGI 進展的測試。
o3 的測試
測試在兩個數據集上進行:
-
一個是 100 道私密題目
-
另一個是 400 道公開題目
o3-low 的成績是 75.7%,而 o3-high(172 倍消耗) 則能達到 87.5%。在公開數據集上的表現更好,分別達到了 82.8% 和 91.5%。而之前最好的大模型成績,是 30%。

這個事情也證明了一點,對於創新性任務,只靠碓數據和加大算力(Scaling Laws),是不夠的,畢竟給 GPT-4 再多的算力也不行。
順道說一下,找外包來處理這些題目,人力成本大概是… 5 美金/題(放在國內,相信能捲到 1 塊錢一題),而即便是最便宜的 o3-low,也需要 20 美金。
所以,就目前來說:由於人工隊薪金低,飯碗還能保住。(什麼逆天言論)
你比 o3 更聰明
這裏有幾個 o3 沒有解決的難題,可以來試試。相信你比 o3 更聰明

Task ID: c6e1b8da

Task ID: 0d87d2a6

Task ID: b457fec5
一定要注意
即便某個 AI 完美通過 ARC-AGI,並不意味著已經實現 AGI。
另外的:由於 o3 在很多簡單問題上,做得很差,這說明他和人類之間還是有根本性差距的,更不能說 o3 探明了 AGI 之路。
此外,ARC-AGI-2 的測試標準即將亮相。即便是 o3-high,其得分也只不到 30% ,而聰明的人類則在在 95%,這還是基於無任何訓練的前提。
以及,Claude 和 OpenAI 在 ARC-AGI 的測試結果,可以在這裏看到:
https://github.com/arcprizeorg/model_baseline/tree/main/results

OpenAI 的12天發佈
美國時間 12 月 4 日,山姆奧特曼在Twitter上表示,要連發 12 天的貨。賽博禪心為此做了全程記錄,讓我們一起來回顧下。

Day 1:o1 / ChatGPT Pro
Plus 用戶,每月支付 20 美金:o1 會獲得更新,支持圖片上傳
Pro 用戶,每月支付 200 美金:無限使用 o1,並且可用 o1 pro mode
Day 3:Sora
年初展示的 Sora,終於發貨了,同時帶來的,還有一整套在線編輯工具。
Day 4:o1 / ChatGPT Pro
ChatGPT 中的畫板功能獲得更新,可在其中直接運行 Python,類似 Jupyter/Colab
Day 6:高級語音模式更新
手機版 ChatGPT 支持和 AI 進行影片通話了,還可以和 AI 共享屏幕。
Day 7:Projects
ChatGPT 有了「文件夾」,在對話之間,可以共享文件。
Day 8:o1 / ChatGPT Pro
ChatGPT 的搜索功能,更新了交互樣式,並且在語音對話的過程中,也能用。
Day 9:API 接口更新
對於開發者來說,這是一個海量更新,包括不僅限於:o1 支持了 Function Call, Realtime API 新貨調價 & 發佈 SDK,新增模型微調,新增 Java 和 Go 的 SDK…
Day 10:電話接入
撥打 +1 800 242 8478,可以和 ChatGPT 聊天了。也可以通過 WhatsAPP 和 ChatGPT 發短信
在下面這篇里,我做了一個非常好玩的 SVG 👇
Day 11:ChatGPT 的新玩法
ChatGPT 桌面版,能讀到別的應用信息了,在語音模式下更絲滑。
這是一個冷飯級別的發佈(之前就更新了)
Day 12:o3
也就是本篇:一個遙遙領先,但貴但匪夷所思的模型,期待調價。