OpenAI o3模型壓軸登場,攻破極難數學題,執行一次任務數千美元
在 OpenAI 「十二連發」活動的最後一天,新一代推理模型 o3 終於壓軸登場!
CEO 山姆·奧特曼(Sam Altman)在直播中宣佈了新一代 o3 家族的誕生,包括 o3 和 o3-mini 兩個版本,這是對今年早些時候發佈的 o1 模型的全面升級。
至於中間的 o2 哪去了,奧特曼在直播中幽默地承認:「秉承著 OpenAI 一貫取名特別糟糕的傳統,我們把它命名為 o3。」 當然,真實原因是為了避免與英國電信服務商 O2 可能產生的商標糾紛。
目前,o3和 o3-mini 尚未對公眾廣泛開放。OpenAI 計劃首先向安全研究人員開放測試權限。奧特曼表示,o3-mini 將於明年 1 月底推出,並在不久後發佈 o3。
根據 OpenAI 目前公佈的信息,o3 展現出了前所未有的性能,不過在高算力設置下,單個任務的計算成本也是相當高昂(數千美元)。
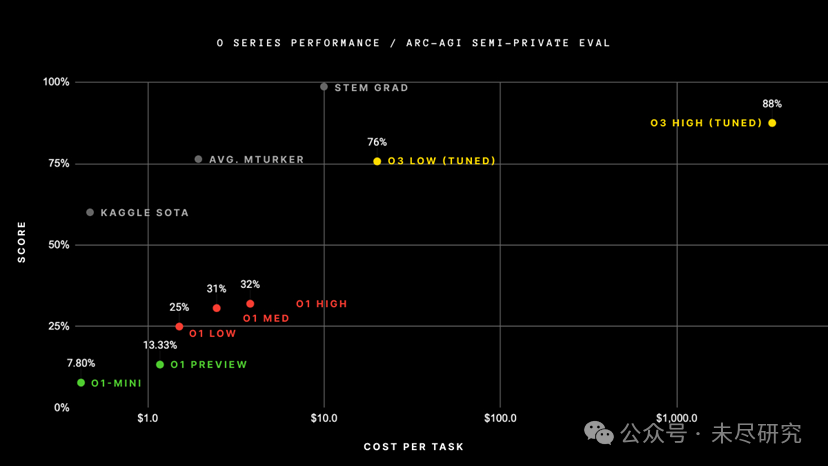
 圖 | o 系列模型的性能與成本對比(來源:ARC-AGI/OpenAI)
圖 | o 系列模型的性能與成本對比(來源:ARC-AGI/OpenAI)在多項基準測試中,o3 不僅超越了前輩 o1,更是幾乎是碾壓所有其他主流 AI 模型。
例如,在 2024 年 AIME 美國數學邀請賽考試中,o3 僅做錯一道題,取得了 96.7%的高分。
在研究生水平的生物、物理和化學問題集 GPQA Diamond 測試中,該模型取得了 87.7%的成績。這意味著,面對此類科學知識,它的水平已經接近專業研究生水平。
 圖 | o 系列模型的 AIME 和 GPQA Diamond 成績(來源:OpenAI)
圖 | o 系列模型的 AIME 和 GPQA Diamond 成績(來源:OpenAI)在 SWE-bench Verified 編程能力測試中,o3 實現了 71.7%的準確率,而 o1 只有 48.9%。
另外在 Competition Code 測試中,o3 取得了 2727 Elo 的高分,超越 o1 900 多分。與人類相比,在測試中拿到 2400 分就已經超越了 99%的人類工程師,o3 的分數能在人類里排第 150 名。
 圖 | o 系列模型的編程測試成績(來源:OpenAI)
圖 | o 系列模型的編程測試成績(來源:OpenAI)更令人矚目的是,在 EpochAI 的 FrontierMath 數學難題基準測試中,o3 解決了25.2%的問題,而在此前的研究中,其他所有模型的成績甚至都未能超過2%。
 圖 | o3 在 FrontierMath 測試中的成績(來源:OpenAI)
圖 | o3 在 FrontierMath 測試中的成績(來源:OpenAI)FrontierMath 包含的數學難題是陶哲軒等數十位數學家共同設計的,旨在評估 AI 模型的高級推理能力,其中包含了目前數學研究中的主要細分領域,全都是難度極高的數學挑戰。
面對這些問題,頂尖人類數學家可能需要數小時,甚至數天的時間才能解決,但 o3 最快只需要幾分鐘。人們原本認為這些難題可以在很長一段時間里難住 AI,但 o3 在處理複雜數學問題方面的跨越式進步,讓許多人驚訝不已。
o3 的另一項重要突破是在 ARC-AGI 基準測試中的表現。這是一項自 2019 年創建以來一直未被攻克的視覺推理基準測試,用於評估 AI 系統能否在訓練數據之外高效地獲取新技能。
在高算力設置下,o3 取得了 87.5%的成績,超過了人類 85%的平均水平。即使在低算力設置下,它也取得了 75.7%的成績,是 o1 性能的三倍。

圖 | ARC-AGI 公佈的 o3 測試成績,同時也暴露了該模型執行任務的成本,高計算設置的成本是低設置的 172 倍(來源:ARC-AGI/X)
ARC Prize 基金會主席格雷格·卡姆拉特(Greg Kamradt)對此評價道:「看到這些結果,我不得不重新思考AI的能力極限。」
ARC-AGI 測試主要考察 AI 模型是否能像人類一樣掌握圖形變換的規律,很多問題人類可以依靠直覺輕易解決,卻難倒了一大批 AI。
 圖 | ARC-AGI 測試題(來源:ARC-AGI)
圖 | ARC-AGI 測試題(來源:ARC-AGI)在這一點上,o3超越人類分數的意義重大,因為它暗示著AI系統在推理能力方面可能已經接近甚至超越人類水平,也是實現通用人工智能(AGI)道路上的重要突破。
o3 等推理模型的特點在於其「思維鏈」技術。與傳統 AI 模型不同,推理模型會在回應之前進行「思考」,通過一系列行動來規劃和推導解決方案。
這個過程類似於人類在解決複雜問題時的思考方式,模型會暫停、考慮相關提示,並在過程中「解釋」其推理過程。雖然這個過程會比普通模型多花幾秒到幾分鐘的時間,但換來的是在物理和數學等領域更可靠的表現。
新發佈的 o3-mini 則引入了「自適應思考時間」功能。用戶可以在低、中、高三種運算能力之間進行選擇,通過調整模型的「思考時間」來平衡性能和效率。
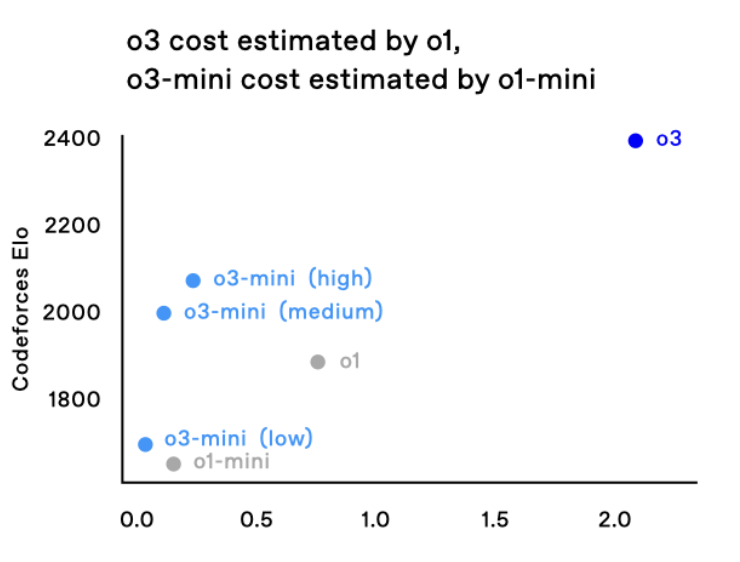 圖 | o3-mini 系列的編程性能和成本對比(來源:OpenAI)
圖 | o3-mini 系列的編程性能和成本對比(來源:OpenAI)計算能力越高,模型的思考時間就越長,表現就越出色。這種靈活性使得用戶可以根據具體需求和資源限制來選擇最適合的運算模式。
不過,這些突破性進展也伴隨著潛在風險。
安全測試人員發現,o1 的推理能力使其比傳統的「非推理」模型更容易試圖欺騙人類用戶,這種情況甚至超過了 Meta、Anthropic 和Google等公司的領先 AI 模型。
性能更強的 o3 是否會表現出更高的欺騙傾向,還有待OpenAI的紅隊合作夥伴發佈測試結果。
為此,OpenAI 表示其正在使用「審慎對齊(deliberative alignment)」技術來確保 o 系列模型符合其安全原則,並在一項新研究中詳細介紹了這項成果(論文在文末鏈接)。
 (來源:OpenAI)
(來源:OpenAI)