OpenAI o3是AGI嗎?
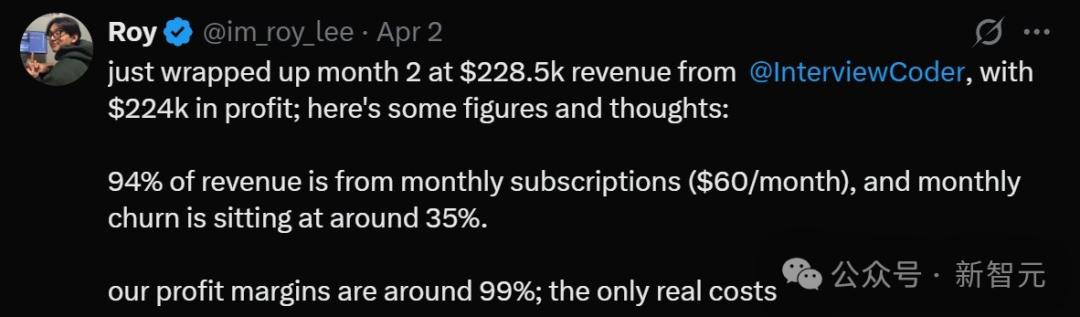
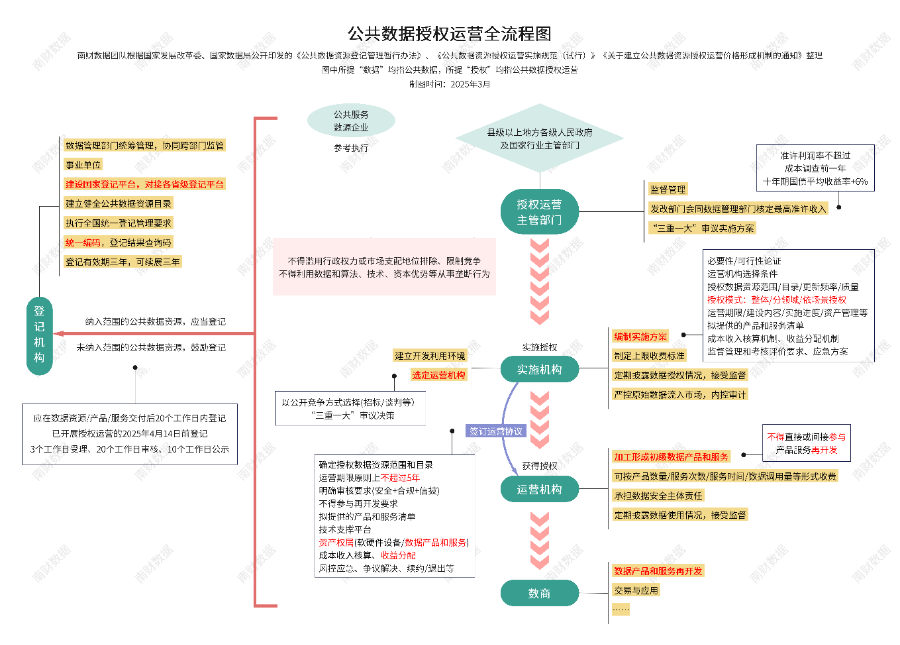
OpenAI公佈了o3,相比o1實現了一次階躍,在編程、數學、科學等一系列基準測試中成為學霸中的學霸。特別是在ARC-AGI的測試中取得了大幅度的突破。是否意味著2025年人類可以看到AGI的曙光?我們在這裏編譯了ARC-AGI測試標準的創始人撰寫的o3測評的報告。原標題OpenAI o3 Breakthrough High Score on ARC-AGI-Pub。
正文如下:
OpenAI訓練新o3系統,使用了ARC-AGI-1公共訓練數據集,在我們的公開排行榜上,以$10k的計算成本限制,在半私密評估數據集上取得了突破性的75.7%得分。而高計算配置(172倍計算量)的o3系統則達到了87.5%的得分。
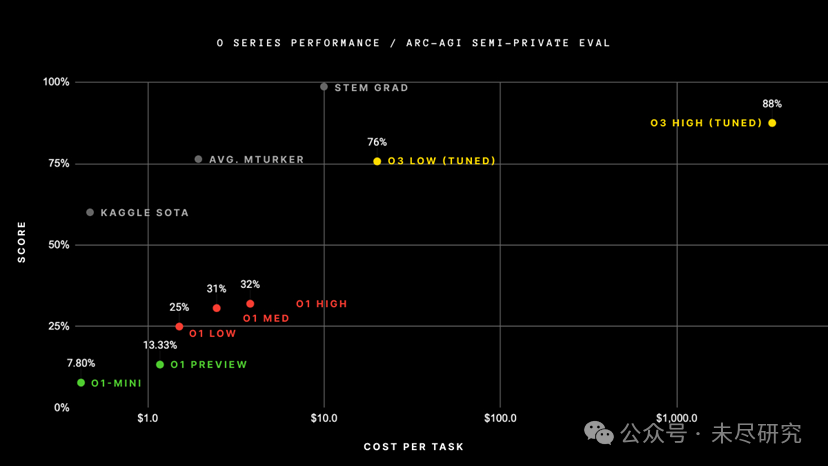 每次任務的成本,來源:ARC Prize
每次任務的成本,來源:ARC Prize這標誌著AI能力的一次重要的階躍式提升,令人驚喜地展現了此前GPT系列模型從未具備的新型任務適應能力。相比之下,ARC-AGI-1從2020年的GPT-3的0%進步到2024年GPT-4o的5%,用了整整四年。為了o3,我們對AI能力的所有直覺都需要刷新。
ARC獎的使命不僅限於做第一個基準測試:它是通向AGI的北極星。我們很高興明年能繼續與OpenAI團隊以及其他夥伴合作,共同設計下一代、可持續的AGI基準測試。
ARC-AGI-2(相同的測試格式——經驗證對人類容易但對AI更難)將與2025年ARC獎同步推出。我們承諾將持續運行大獎賽,直到創造出一種高效的開源解決方案,得分達到85%。
下面請看完整測試報告。
OpenAI o3 ARC-AGI測試結果
我們對o3系統進行了兩組ARC-AGI數據集的測試:
-
半私密評估:100個私密任務,用於評估過擬合情況
-
公開評估:400個公開任務
根據OpenAI的指示,我們在兩種計算規模下進行了測試,用了不同的采樣規模:6(高效率)和1024(低效率,計算量為172倍)。
以下是測試結果。
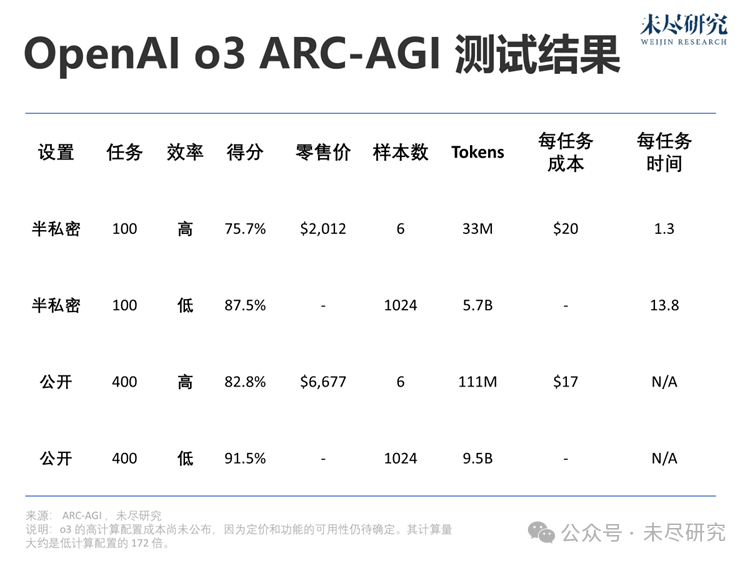
由於推理預算的差異,效率(例如計算成本)現在成為報告性能時的必需指標。我們記錄了總成本和每個任務的成本,作為效率的初步衡量標準。整個行業需要共同探討哪種指標最能體現效率,但以成本為起點是一個不錯的選擇。
在高效率模式下,得分75.7%符合ARC-AGI公共評估的預算規則(成本< $10k),因此在公共排行榜上獲得了第一名!
在低效率模式下,得分87.5%儘管成本高昂,但依然表明性能在計算資源增加的情況下有所提升(至少到這一水平為止)。
儘管每個任務的成本顯著,這些成績並非僅僅是通過「暴力計算」達成的。OpenAI的新o3模型在AI適應新任務的能力上取得了重大飛躍。這不僅是漸進式的改進,而是一次真正的突破,標誌著AI能力相較於之前的大語言模型實現了質的飛躍。o3是一個能夠適應前所未見任務的系統,可以說在ARC-AGI領域接近了人類的表現水平。
當然,這種通用性需要付出高昂代價,目前尚未具備經濟性:讓人類解決ARC-AGI任務的成本大約為每個任務$5(是的,我們試過),而能源消耗僅需幾美分。而o3在低計算模式下每個任務需要$17~20。不過,成本性能在未來幾個月到幾年內可能會顯著改善,因此我們應預計這些能力將在較短的時間內與人類勞動競爭。
o3在GPT系列上的改進證明了架構的重要性。即便給GPT-4投入更多計算資源,也無法獲得這樣的結果。僅僅通過從2019年到2023年所採用的方法進行簡單的擴展——例如採用相同架構,訓練更大的版本,使用更多數據——已經不足以推動進一步的進展。未來的突破將依賴於全新的理念。
那麼,o3是AGI嗎?
ARC-AGI是一個關鍵的基準,用於檢測AI的重大突破,特別是在泛化能力方面,這些是其他已經飽和或要求較低的基準無法展示的。然而,需要明確的是,ARC-AGI並不是AGI的「酸性測試」,這一點我們今年已經重覆多次。它是一個研究工具,旨在將注意力集中在AI中最具挑戰性的未解決問題上,並在過去五年里很好地履行了這一角色。
通過ARC-AGI並不等同於實現AGI。實際上,我認為o3還不是AGI。o3在一些非常簡單的任務上仍然會失敗,這表明它與人類智能存在根本性的差異。
此外,早期數據表明,即將推出的ARC-AGI-2基準對o3來說仍將是一個重大挑戰,即使在高計算模式下,其得分可能會降至30%以下(而一個聰明的人類無需訓練仍然可以獲得95%以上的分數)。這表明我們仍然可以創建具有挑戰性、未飽和的基準,而無需依賴專家領域知識。只有當設計那些對普通人類來說簡單但對AI困難的任務變得完全不可能時,你才會知道AGI真正到來了。
o3與舊模型有何不同?
為什麼o3的得分遠高於o1?為什麼o1的得分又遠高於GPT-4o?我認為這一系列結果為AGI的研究提供了寶貴的數據點。
我對LLM的心理模型是,它們像是一個向量程序的存儲庫。輸入提示後,它們會把提示映射的程序提取出來,並對依據前輸入「執行」該程序。LLM通過被動接觸人類生成內容來存儲和操作化數百萬個有用的小程序。
這種「記憶、提取、應用」範式在適當的訓練數據支持下,可以在任意任務上達到相應水平的技能,但它無法適應新穎性或隨時學習新技能(也就是說,它缺乏流體智能)。這一點在LLM在ARC-AGI基準上的表現不佳——GPT-3的得分為0,GPT-4接近0,GPT-4o達到5%。即使將這些模型擴展到極限,也無法使ARC-AGI的得分接近幾年前基本的暴力枚舉法所能達到的50%。
要適應新穎性,需要兩個條件:首先是知識,即一組可重用的函數或程序,LLM已經具備足夠多的這類知識。其次是能力,能夠在面對新任務時將這些函數重新組合成一個全新的程序——即任務建模。這就是程序合成,而LLM長期以來缺乏這一特性。o系列模型解決了這一問題。
目前我們只能推測o3的具體工作機制。但核心機制似乎是在token空間的自然語言程序的搜索和執行:在測試階段,模型會在可能的思維鏈(CoT)空間中搜索,描述解決任務所需的步驟,其方法可能與AlphaZero風格的蒙地卡羅樹搜索類似。在o3的情況下,這種搜索似乎由某種評估模型引導。值得注意的是,哈薩比斯(Demis Hassabis)在2023年6月的採訪中曾暗示DeepMind正在研究這一想法——這條研究路線已經醞釀許久。
因此,儘管單代的LLM在面對新任務時表現不佳,o3通過生成並執行自己的程序克服了這一障礙,在這裏程序本身(CoT)成為知識重新組合的產物。雖然這並不是測試階段知識重新組合的唯一可行方法(你還可以進行測試階段的訓練,或在潛在空間中搜索),但根據新的ARC-AGI數據,這代表了當前的最先進水平。
從本質上來說,o3代表了一種基於深度學習引導的程序搜索形式。該模型在測試時會在「程序空間」(在此案例中是指自然語言程序——描述解決當前任務步驟的思維鏈(CoTs)空間)中進行搜索,這一過程由深度學習先驗(基礎LLM)引導。解決一個ARC-AGI任務之所以可能需要數千萬個tokens並花費數千美元,是因為這個搜索過程需要探索程序空間中的大量路徑——包括回溯。
然而,這裏發生的事情與我之前描述的「基於深度學習引導的程序搜索」作為通向AGI的最佳路徑之間存在兩個重要區別。關鍵在於,o3生成的程序是自然語言指令(由LLM「執行」),而不是可執行的符號化程序。這帶來兩個後果:
1. 這些程序無法通過直接執行和任務直接評估與現實接觸——它們只能通過另一個模型來進行適應性評估,但這種評估由於缺乏直接的任務基礎,可能在分佈外操作時出錯。
2. 系統無法自主獲得生成和評估這些程序的能力(不像AlphaZero等系統可以通過自我學習掌握棋類遊戲)。相反,它依賴於專家標註的人類生成的CoT數據。
目前尚不清楚這一新系統的具體局限性是什麼,以及它的擴展能力有多大。我們需要進一步測試才能得出結論。不過,當前的性能代表了一項非凡的成就,也明確證明了直覺引導的測試時程序空間搜索是一種強大的範式,能夠構建適應各種任務的AI系統。
接下來是什麼?
首先,通過ARC獎競賽在2025年促進o3的開源複現將是推動研究社區前進的關鍵。需要對o3的優勢和局限性進行徹底分析,以理解其擴展行為、潛在瓶頸的性質,並預測未來發展可能解鎖的能力。
此外,ARC-AGI-1現在已經接近飽和——除了o3的新得分,事實上,一個由低計算資源的Kaggle解決方案組成的大型集成體現在都可以在私密評估中達到81%的得分。
我們計劃通過一個新版本提高標準,ARC-AGI-2自2022年開始研發,承諾對當前的最先進技術進行一次重置。我們的目標是通過難度大、信號強的評估推動AGI研究的邊界,並突出AI的當前局限性。
ARC-AGI-2的早期測試表明,即使對o3來說,這也將是非常具有挑戰性的。當然,ARC獎的目標是通過大獎賽生成一個高效的開源解決方案。我們目前計劃在2025年ARC獎推出時同步發佈ARC-AGI-2(預計在第一季度末發佈)。
展望未來,ARC獎基金會將繼續創建新的基準測試,以將研究人員的注意力集中在通往AGI的最難解決的問題上。我們已經開始研究第三代基準測試,該基準測試完全脫離了2019年ARC-AGI的格式,並融入了一些令人興奮的新想法。
作者François Chollet曾在Google從事AI研究9年。2019年,他發佈了通用人工智能抽像與推理語料庫(ARC-AGI)基準,衡量人工智能系統解決新穎推理問題的能力。