o3並非獨門秘技,Google已發背後關鍵機制,方法更簡單、成本更低
小交 發自 凹非寺
量子位 | 公眾號 QbitAI
o1/o3帶火的推理計算Scaling,原來Google早在今年8月就曾探討過。

當時,來自史丹福、牛津以及GoogleDeepMind的團隊提出通過重覆采樣來擴展推理計算量——
結果在編碼任務中將性能最多提高40%。
他們發現小模型通過生成多種答案/樣本,其任務表現可能比一些大型模型單次嘗試還要好。
比如,DeepSeek-Coder通過重覆採集5個樣本,性能優於GPT-4o,而成本卻僅為後者的三分之一。
這篇論文講了什麼?
這篇論文取名Monkey,靈感來自於無限猴子定理。
一隻猴子在打字機鍵盤上隨機敲擊鍵盤無限長的時間,幾乎肯定會打出任何給定的文本。

而在大模型的語境下,只要采的樣夠多,那麼大模型總能找到正確解。
本文遵循的重覆采樣程序,首先通過大模型中采樣,為給定的問題生成許多候選解。
其次再選擇特定領域的驗證器Verifier(比如代碼的unittests),從生成的樣本中選擇最終答案。
重覆采樣的有效性取決於兩個關鍵特性。
-
覆蓋率,隨著樣本數量的增加,我們可以利用生成的任何樣本解決多少問題。
-
精確度,在從生成的樣本集合中選擇最終答案的情況下,我們能否識別出正確的樣本?
他們關注的是yes or no的任務,在這些任務中,答案可以直接被打分為對或者錯,主要指標是成功率——即能夠解決問題的比例。
通過重覆采樣,考慮這樣一種設置,即模型在嘗試解決問題時可以生成許多候選解。
因此,成功率既受到為許多問題生成正確樣本的能力(即覆蓋率)的影響,也受到識別這些正確樣本的能力(即精確度)的影響。
基於此,確定了五種數學和編程任務:GSM8K、MATH、MiniF2F-MATH、CodeContests、SWE-benchLite。
結果顯示,在多個任務和模型中,覆蓋率隨樣本數量增加而提升,在某些情況下,重覆采樣可使較弱模型超越單樣本性能更好的強模型,且成本效益更高
比如在使用Gemma-2B解決CodeContests編程問題時。隨著樣本數量的增加,覆蓋率提高了300倍以上,從一次嘗試的0.02%提高到10000次嘗試的7.1%。解決來自GSM8K和MATH的數學單詞問題時,Llama-3模型的覆蓋率在10,000個樣本的情況下增長到95%以上。
有趣的是,log(覆蓋率)與樣本數之間的關係往往遵循近似的冪律。
在Llama-3和Gemma模型中,可以觀察到覆蓋率與樣本數呈近似對數線性增長,超過幾個數量級。

在不同參數量、不同模型以及後訓練水平(基礎模型和微調模型)下,都顯示通過重覆采樣Scaling推理時間計算,覆蓋率都有一致的提升。

此外,他們還證明了這種Scaling還能降本增效,以FLOPs作為成本指標,以LIama-3為例。
計算公式如下:

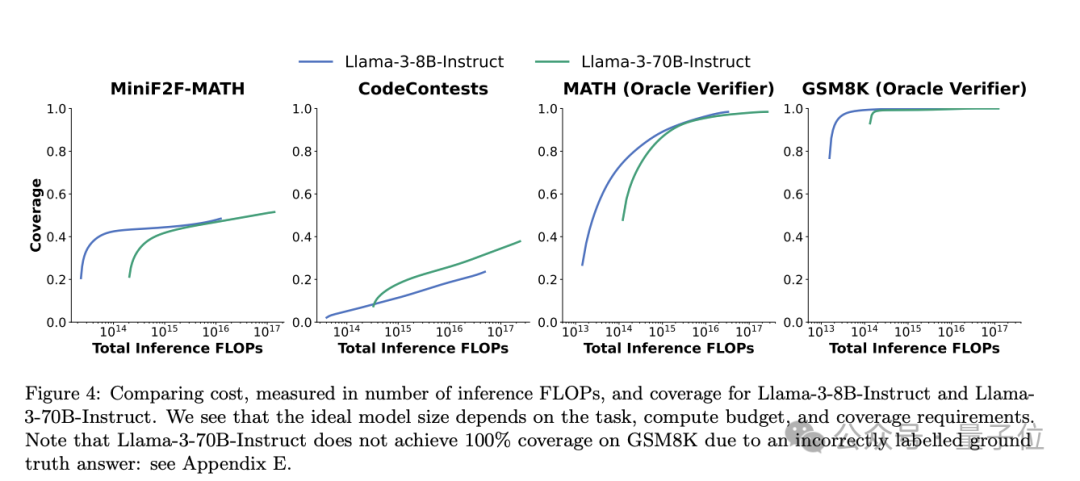
比較 Llama-3-8B-Instruct 和 Llama3-70B-Instruct 的成本(以推理 FLOPs 數量衡量)和覆蓋率。當FLOPs預算固定時,在 MiniF2F、GSM8K和 MATH 上,Llama-3-8B-Instruct的覆蓋率總是高於更大(更貴)的 70B 模型。然而,在 CodeContests 中,70B 模型幾乎總是更具成本效益。
對比API成本,當采樣較多時,開源 DeepSeek-Coder-V2-Instruct 模型可以達到與閉源模型GPT-4o相同的問題解決率,而價格僅為後者的三分之一。

有趣的是,他們發現對於大多數任務和模型,覆蓋率與樣本數之間的關係可以用指數冪律來模擬。

因此總結,這篇文章以重覆采樣為軸心,在推理時擴展計算量,從而提高模型性能。
在一系列模型和任務中,重覆采樣可以顯著提高使用任何生成樣本解決問題的比例(即覆蓋率)。當可以識別出正確的解決方案時(通過自動驗證工具或其他驗證算法),重覆采樣可以在推理過程中放大模型的能力。
與使用較強、較昂貴的模型進行較少的嘗試相比,這種放大作用可使較弱的模型與大量樣本的組合更具性能和成本效益。
來自史丹福牛津Google
這篇論文是來自史丹福、牛津大學以及GoogleDeepMind團隊。TogetherAI提供計算支持。
其中可以看到有Google傑出科學家Quoc V. Le。

有網民表示,這有點像更簡單的靜態版o3。

o3在評價器的指導下,通過回溯動態搜索程序空間,而這種方法則依賴於靜態采樣和事後評價(投票、獎勵模型等)。兩者都能擴展推理計算,但O3的適應性更強。
o3會反復探索解決方案,不斷完善路徑,而重覆采樣會並行生成輸出,沒有反饋回路。如何取捨?o3的計算密集度更高,但在需要結構化推理的任務中表現出色。這種方法在編碼/數學方面更具成本效益。
不過也有網民指出了背後的局限性。

我們不能一味地增加采樣數量來提高性能。在某些時候,模型會出現停滯,生成的樣本也會開始重覆。
無論成本如何,都有一個極限,一個模型無法超越的最大思維水平。
參考鏈接:
[1]https://arxiv.org/abs/2407.21787
[2]https://x.com/_philschmid/status/1870396154241843312
[3]https://x.com/rohanpaul_ai/status/1834446350810849510