AI看病竟比醫生強?哈佛、史丹福等聯合評估o1-preview,診斷準確率高達近80%

新智元報導
編輯:KingHZ
【新智元導讀】o1-preview在醫療診斷中遠超人類,賽博看病指日可待?
「根據(關於)OpenAI的最新論文,o1-preview在推理任務上遠遠優於醫生,甚至天壤之別。AI對143項困難的NEJM CPC診斷結果分別為約80%到30%。現在相信你的醫生而不諮詢人工智能模型是危險的。」
Deedy的言論引來百萬圍觀。

事實究竟如何?
在解決複雜的信息學、數學和工程問題以及醫療問答方面,o1-preview模型顯示出優於 GPT-4 的能力。
醫療決策遠非問答,o1-preview在醫學上是否已全面超越人類?
哈佛、史丹福、微軟等機構的多名醫學、AI專家聯手,在醫學推理任務中評估了OpenAI的o1-preview。
結果顯示,模型在鑒別診斷、診斷臨床推理和管理推理方面,已經超越人類;建議使用更好和更有意義的評估策略,跟上自動化系統在醫療推理基準上的進步。
文章推測要使用大語言模型輔助醫生, 需要集成AI系統的臨床試驗和勞動力(再)訓練。
 論文鏈接:https://www.arxiv.org/abs/2412.10849
論文鏈接:https://www.arxiv.org/abs/2412.10849AI輔助診斷工具評估
在醫學頂刊《JAMA》、《JAMA·內科》和《NPJ·數字醫學》,有論文已指出大語言模型已在診斷基準測試中超越了人類,包括醫科學生、住院醫師和主治醫師。
此次,針對鑒別診斷生成、推理報告、概率推理和管理推理任務, 聯合團隊評估了o1-preview的臨床多步推理能力。
與醫生、已有的大語言模型相比, o1-preview在鑒別診斷以及診斷和管理推理的質量都有明顯提高。

鑒別診斷
自20世紀50年代以來,評估鑒別診斷生成器的首要標準是《新英格蘭醫學雜誌》(NEJM)發表的臨床病理學會議(CPCs)病例。這是也是評估o1-preview的第一個基準。

兩位醫生同時評估o1-preview的鑒別診斷質量,且在143個案例中有120個結果一致。
o1-preview在鑒別診斷中準確率高達78.3%(見圖1)。
 圖1:鑒別診斷(DDx)生成器和大語言模型在鑒別診斷的正確率條形圖,按年份排序
圖1:鑒別診斷(DDx)生成器和大語言模型在鑒別診斷的正確率條形圖,按年份排序圖1中的o1-preview的數據是基於在《新英格蘭醫學雜誌》(NEJM)發表的臨床病理學會議(CPCs)病例。其他大語言模型或DDx生成器的數據是從文獻中獲得的。
o1-preview的建議的首次診斷的正確率為52%。
o1-preview在預訓練截止日期前的準確率為79.8%,之後為73.5%, 沒有顯著差異。
表1展示了o1-preview可以解決而ChatGPT4無法解決的複雜案例。
 表1:o1-preview正確診斷出GPT-4無法解決的三個複雜病例
表1:o1-preview正確診斷出GPT-4無法解決的三個複雜病例表1中Bond Score的範圍是從0到5, 其中5分表示鑒別診斷列表中包含了正確的目標診斷, 而0分表示鑒別診斷列表中沒有接近目標的選項。
o1-preview在88.6%的病例中得出了準確或非常接近準確的診斷結果,而GPT-4只有72.9%(見圖 2A)。

兩名醫生根據CPC中描述的患者實際治療情況,對o1-preview提出的檢查計劃進行了評分, 總計132例,其中113例兩人的評分一致。
在87.5%的病例中,o1-preview選擇了正確的檢查項目,另有11%的病例中,兩位醫生認為所選的檢查方案是有用的,只有1.5%的病例認為是沒用的(圖 3)。相關例子見表2。
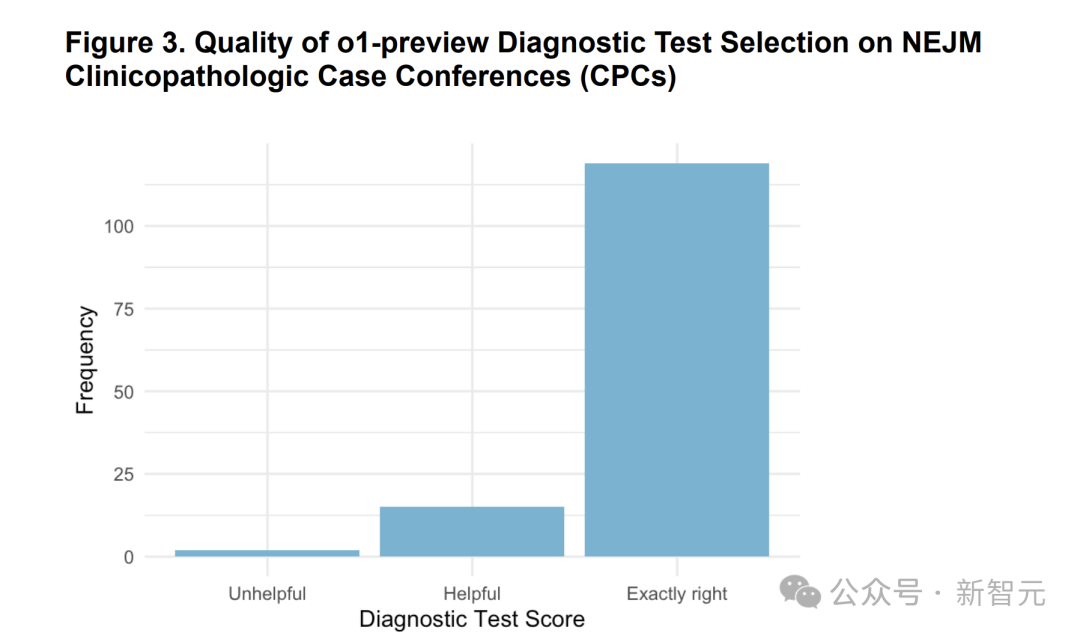 圖3:o1-preview在預測下一步應進行的診斷測試方面的性能
圖3:o1-preview在預測下一步應進行的診斷測試方面的性能在實驗中兩名醫生使用「無用(unhelpful)」、「有用(helpful)」和「完全正確(exactly right)」的李克特量表對預測結果進行了測量。
並從全部病例中剔除了7個病例,因為這些病例要求進行下一次檢查是不合理的。






 表2:o1-preview 建議的測試計劃與案例中使用的測試計劃對比示例(左右滑動查看)
表2:o1-preview 建議的測試計劃與案例中使用的測試計劃對比示例(左右滑動查看)表2中案例得分為2分,表明測試比較好,與案例計劃幾乎完全相同。1分表示所建議的診斷本來是有幫助的,或者可以通過病例中沒有使用的測試得出診斷結果。0分表示所建議的診斷方法沒有幫助。
NEJM Healer診斷案例
為評估臨床推理, NEJM Healer案例專門設計了虛擬患者遭遇。

兩位醫生分別評估o1-preview的臨床推理質量,在80個案例中,有79個案例達成了一致(約佔99%)。
在80個案例中,o1-preview在78個案例中達到了完美的R-IDEA評分, 其表現遠超GPT-4、主治醫師和住院醫師,如圖4A所示。

圖4:圖A表示在20個NEJM Healer案例中,根據回答者分層的312個R-IDEA評分分佈。圖B表示初診報告( initial triage presentation)中包含的不能遺漏診斷的比例的箱線圖
圖B中的總樣本量為70,其中包括來自主治醫師、GPT-4和o1-preview的18個回答,以及來自住院醫師的16個回答。
o1-preview在初診報告( initial triage presentation)中識別「不能錯過」的診斷的比例見圖4B,包含「不能錯過」的診斷的中位數比例為0.92,與GPT-4、主治醫師或住院醫師沒有顯著差異。
灰質管理案例
在真實案例基礎上,25位醫生專家利用共識方法開發了5個臨床實例(clinical vignettes)。
測試中先將臨床實例呈現給模型,然後向其提出關於下一步管理的一系列問題。
兩位醫生對o1-preview的五個案例的回應進行了評分,一致性相當大。
o1-preview每個案例的中位數評分為86%(圖5A),優於GPT-4、使用GPT-4的醫生和使用傳統資源的醫生。
 圖5:圖A表示大語言模型和醫生的管理推理得分的標準化箱線圖。圖B表示模型和醫生診斷推理得分的標準化箱線圖
圖5:圖A表示大語言模型和醫生的管理推理得分的標準化箱線圖。圖B表示模型和醫生診斷推理得分的標準化箱線圖圖A共包括五個案例。o1-preview為每個案例生成一個響應,GPT-4為每個案例生成五個響應,使用GPT-4的醫生總有176個響應,使用傳統資源的醫生總有199個響應。
使用混合效應模型估計,o1-preview比單獨的GPT-4高出41.6%,比使用GPT-4的醫生高出42.5%,比使用傳統資源的醫生高出49.0%。
標誌性診斷案例
兩位內科醫生對o1-preview在六個診斷推理案例中的回答進行了評分,評價結果較為一致。o1-preview的中位數評分為97% (圖5B)。
與歷史控制數據相比,比GPT-4的得分為92%,使用GPT-4的醫師得分為76% ,而使用傳統資源的醫師為74%。
使用混合效應模型估計,o1-preview與GPT-4相比表現相當(高出4.4%),比使用GPT-4的醫師高18.6%,比使用傳統資源的醫師高20.2%。
診斷概率推理案例
在診斷概率推理中, 總使用了五個初級保健主題的案例。
以科學參考概率(scientific reference probabilities)為基準,比較了o1-preview,GPT-4和人類的概率推理能力。
其中人類由553名具有全國代表性的醫療從業者組成, 包括290名住院醫師、202名主治醫師和61名護士或醫生助理。
 如圖6和表3所示,在概率推理方面, 無論在測試前還是在測試後o1-preview與GPT-4表現差不多。
如圖6和表3所示,在概率推理方面, 無論在測試前還是在測試後o1-preview與GPT-4表現差不多。只有冠狀動脈疾病的壓力測試中,o1-preview的預測密度比模型和人類更接近參考範圍。

研究的局限性
此研究也有四處主要的局限性。
首先,o1-preview有囉嗦的傾向,可能會在試驗中取得更高得分。

其次,目前的研究只反映了模型性能, 但現實中離不開人機交互。人機交互對開發臨床決策輔助工具至關重要, 下一步應該確定大語言模型(比如o1-preview)能否增強人機交互。
但人類與計算機之間的交互或許是不可預測的,甚至表現良好的模型與人類交互中可能出現退化。

第三,研究只考察了臨床推理的五個方面;但已經發現了幾十個其他任務,它們可能對實際的臨床護理有更大影響。
第四,研究案例集中在內科,但並不代表更廣泛的醫療實踐,包括多個亞專業,這些專業需要各種技能,如外科決策。研究也沒有考慮診斷、患者特徵或就醫地點的差異。
參考資料:
https://arxiv.org/pdf/2412.10849
https://x.com/deedydas/status/1869049071346102729



















