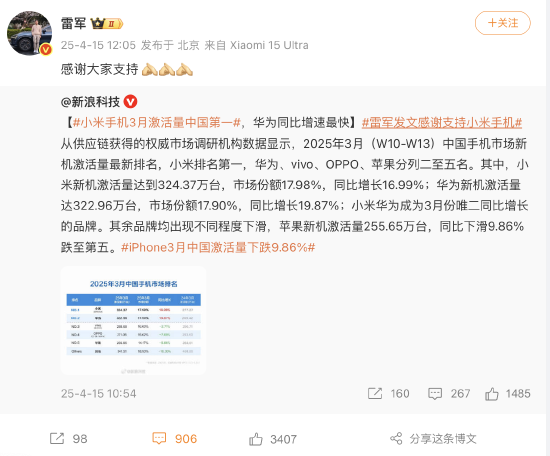
時隔6年BERT升級!僅編碼器架構沒被殺死,更快更準確更長上下文
西風 發自 凹非寺
量子位 | 公眾號 QbitAI
時隔6年,一度被認為瀕死的「BERT」殺回來了——
更現代的ModernBERT問世,更快、更準、上下文更長,發佈即開源!
去年一張「大語言模型進化樹」動圖在學術圈瘋轉,decoder-only枝繁葉茂,而曾經盛極一時的encoder-only卻似乎走向沒落。
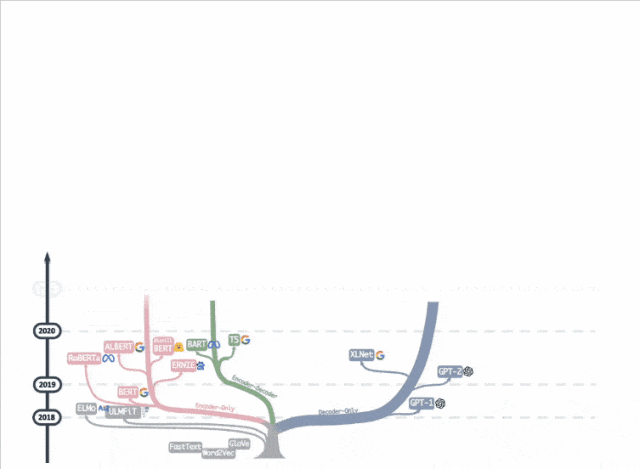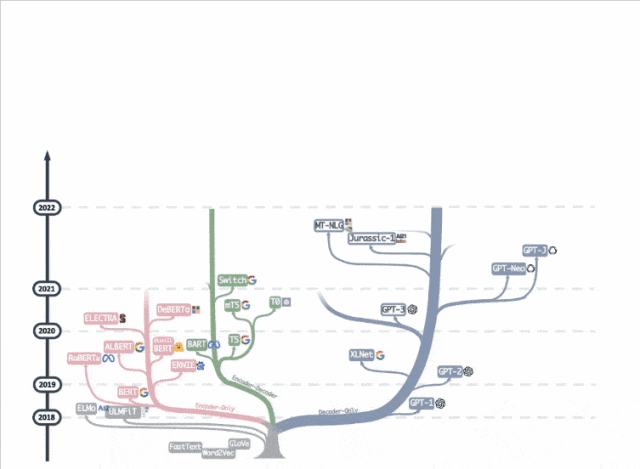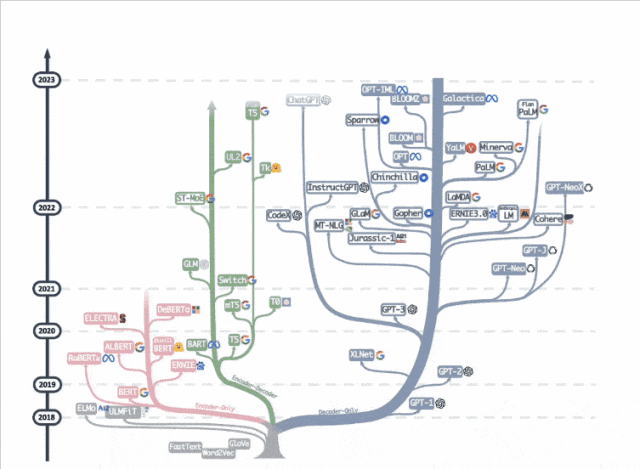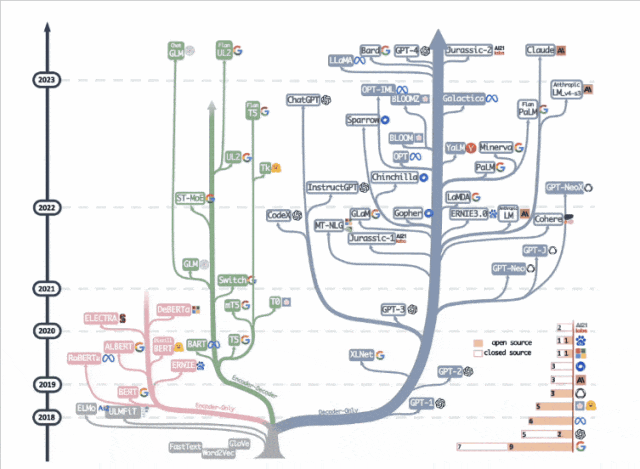
ModernBERT作者Jeremy Howard卻說:
encoder-only被低估了。

他們最新拿出了參數分別為139M(Base)、395M(Large)的兩個模型,上下文長度為8192 token,相較於以BERT為首的大多數編碼器,其長度是它們的16倍。
ModernBERT特別適用於信息檢索(RAG)、分類、實體抽取等任務。
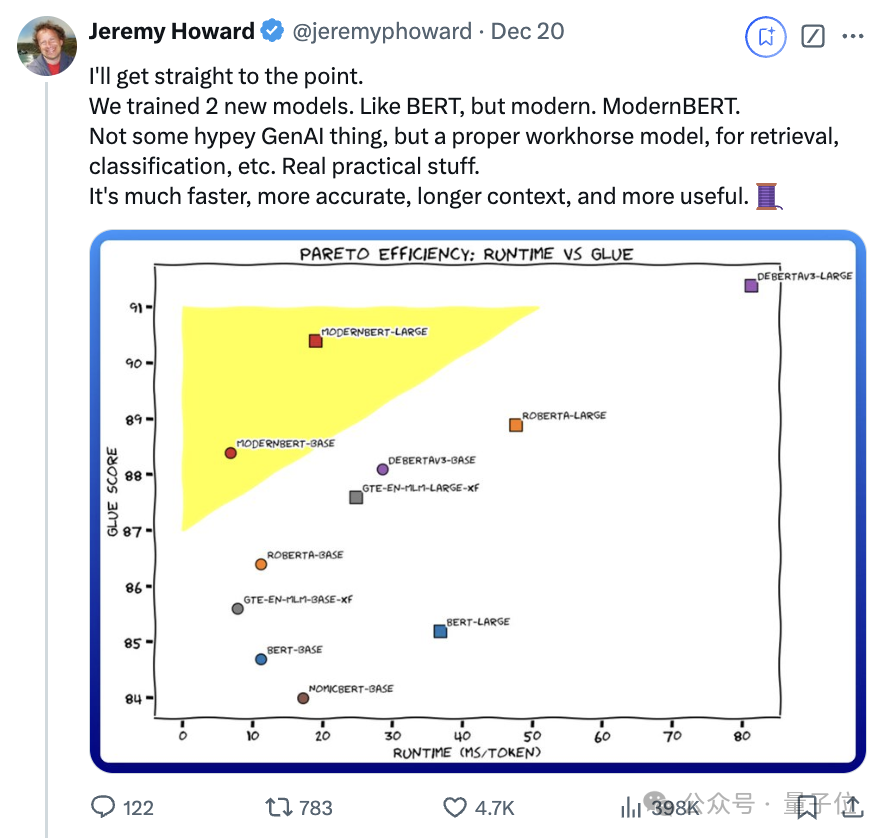
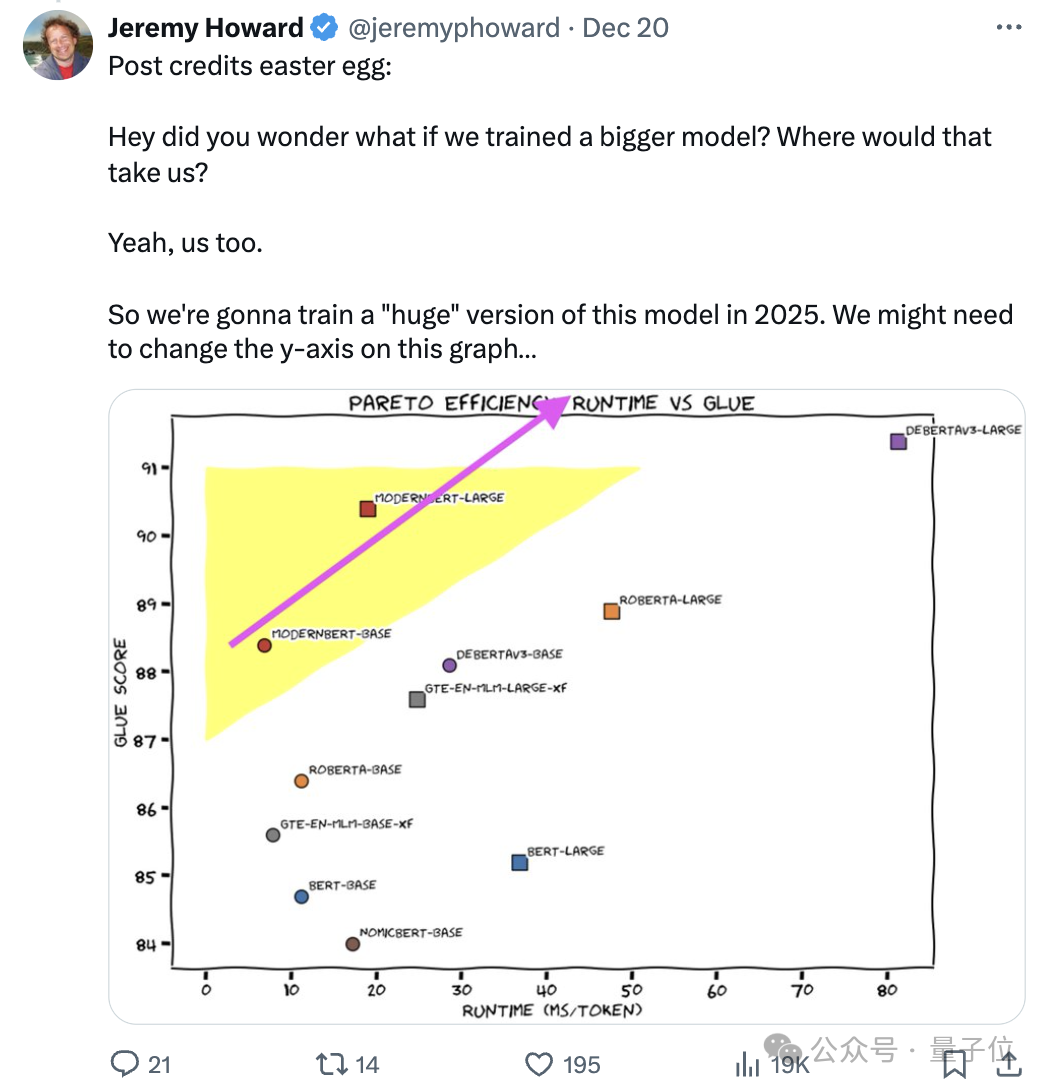
在檢索、自然語言理解和代碼檢索測試中性能拿下SOTA:
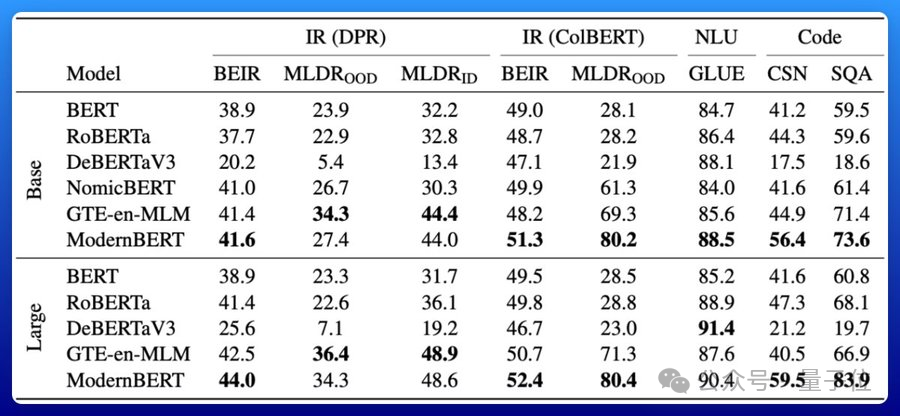
效率也很高。
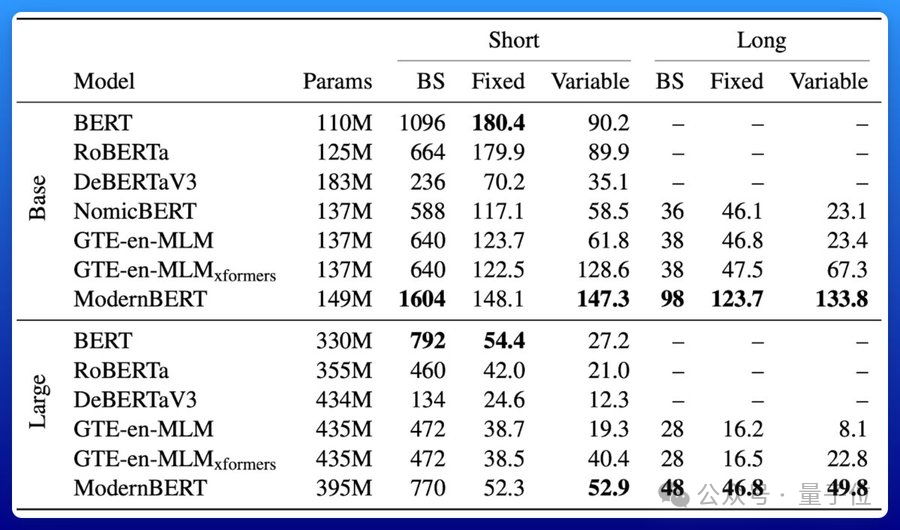
ModernBERT速度是DeBERTa的兩倍;在更常見的輸入長度混合的情況下,速度可達4倍;長上下文推理比其它模型快約3倍。
關鍵它所佔的內存還不到DeBERTa的五分之一。
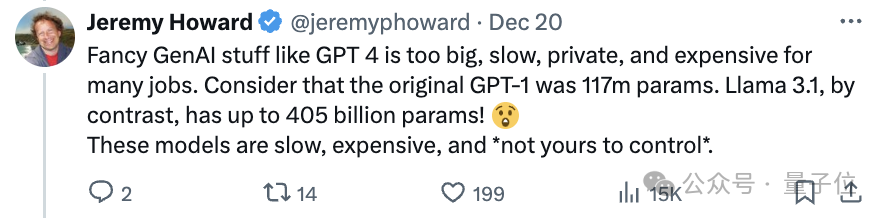
Jeremy Howard表示,目前關於生成式模型的熱議掩蓋了encoder-only模型的作用。
像GPT-4這樣大模型,太大、太慢、私有化、成本高昂,對許多任務來說並不適合,還有Llama 3.1,參數都達到了405B。
這些模型運行緩慢,價格昂貴,而且不是你可以控制的。
GPT-4這樣的生成模型還有一個限制:它們不能預先看到後面的token,只能基於之前已生成的或已知的信息來進行預測,即只能向後看。
而像BERT這樣的僅編碼器模型可以同時考慮前後文信息,向前向後看都行。

ModernBERT的發佈吸引數十萬網民在線圍觀點讚。
抱抱臉聯合創始人兼CEO Clem Delangue都來捧場,直呼「愛了!!」。
為什麼ModernBERT冠以「現代」之名?相較於BERT做了哪些升級?
殺不死的encoder-only
ModernBERT的現代體現在三個方面:
-
現代化的Transformer架構
-
特別關注效率
-
現代數據規模與來源
下面逐一來看。
首先,ModernBERT深受Transformer++(由Mamba命名)的啟發,這種架構的首次應用是在Llama2系列模型上。
ModernBERT團隊用其改進後的版本替換了舊的BERT-like構建塊,主要包括以下改進:
-
用旋轉位置嵌入(RoPE)替換舊的位置編碼,提升模型理解詞語之間相對位置關係的表現,也有利於擴展到更長的序列長度。
-
用GeGLU層替換舊的MLP層,改進了原始BERT的GeLU激活函數。
-
通過移除不必要的偏置項(bias terms)簡化架構,由此可以更有效地使用參數預算。
-
在嵌入層之後添加一個額外的歸一化層,有助於穩定訓練。
接著,在提升速度/效率方面,ModernBERT利用了Flash Attention 2進行改進,依賴於三個關鍵組件:
一是使用交替注意力(Alternating Attention),提高處理效率。
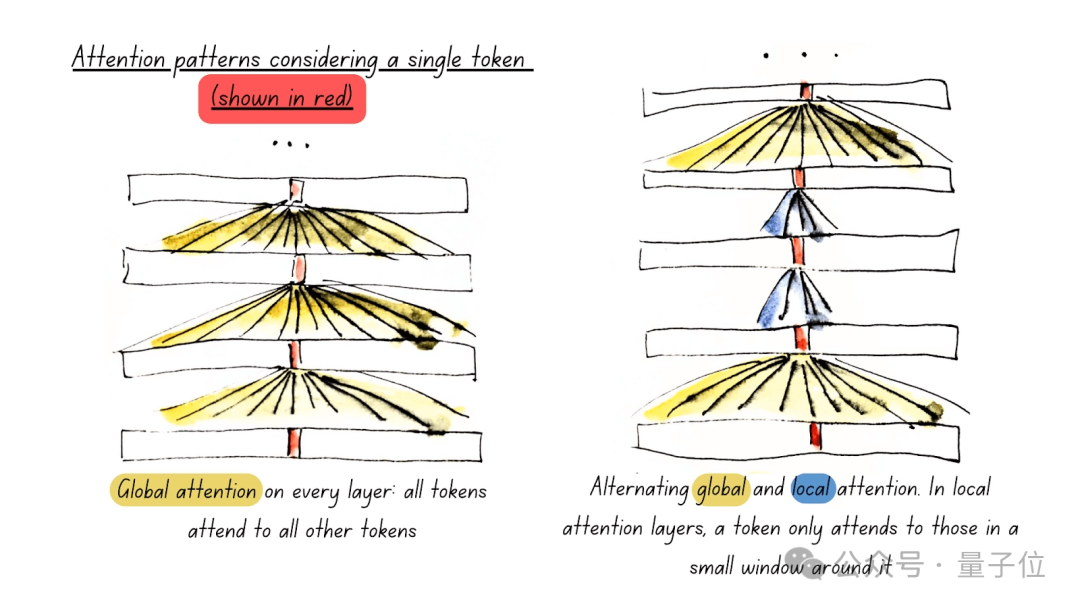
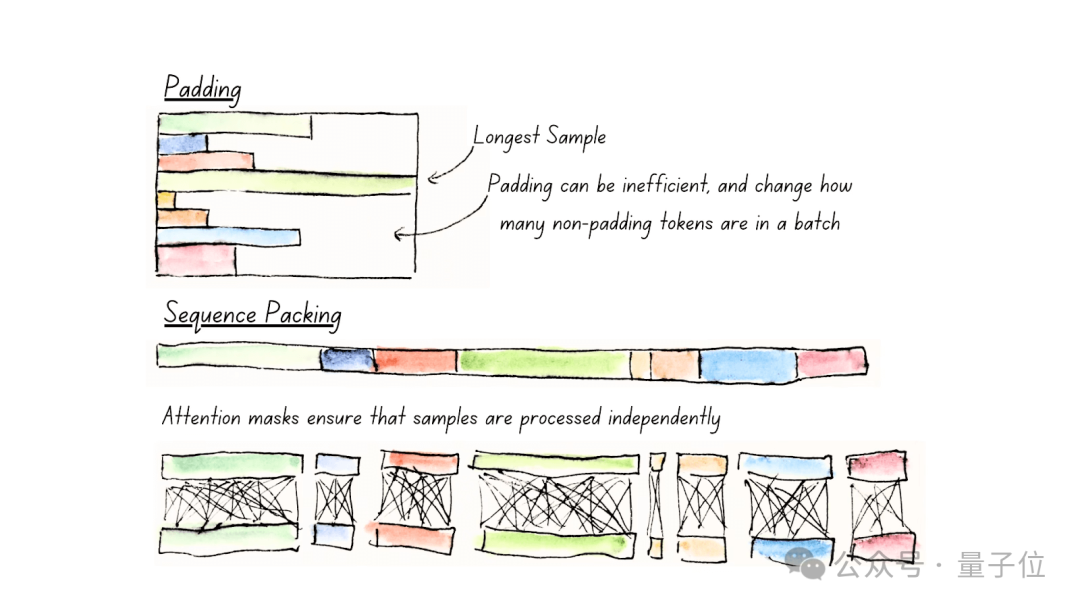
二是使用Unpadding和Sequence Packing,減少計算浪費。
三是通過硬件感知模型設計(Hardware-Aware Model Design),最大化硬件利用率。

這裏就不詳細展開了,感興趣的童鞋可以自行查閱原論文。
最後來看訓練和數據方面的改進。
團隊認為,encoders在訓練數據方面的落後,實際問題在於訓練數據的多樣性,即許多舊模型訓練的語料庫有限,通常只包括域奇百科和書籍,這些數據只有單一的文本模態。
所以,ModernBERT在訓練時使用了多種數據,包括網絡文檔、編程代碼和科學文章,覆蓋了2萬億token,其中大部分是獨一無二的,而不是之前encoders中常見的20-40次的重覆數據。
訓練過程,團隊堅持使用原始BERT的訓練配方,並做了一些小升級,比如移除了下一句預測目標,因為有研究表明這樣的設置增加了開銷但沒有明顯的收益,還將掩碼率從15%提高到30%。
具體來說,139M、395M兩個規格的模型都通過了三階段訓練。
首先第一階段,在序列長度為1024的情況下訓練1.7T tokens。然後是長上下文適應階段,模型處理的序列長度增加到8192,訓練數據量為250B tokens,同時通過降低批量大小保持每批次處理的總tokens量大致相同。最後,模型在500億個特別采樣的tokens上進行退火處理,遵循ProLong強調的長上下文擴展理想混合。
一番操作下來,模型在長上下文任務上表現具有競爭力,且處理短上下文的能力不受損。
訓練過程團隊還對學習率進行了特別處理。在前兩個階段,模型使用恒定學習率,而在最後的500億tokens的退火階段,採用了梯形學習率策略(熱身-穩定-衰減)。
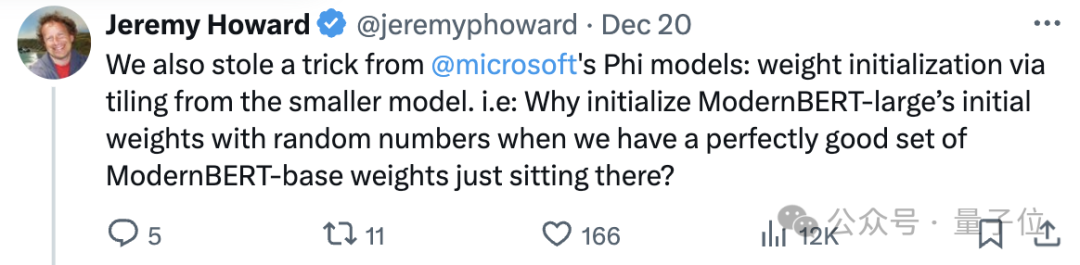
團隊還使用兩個技巧,加速模型的訓練過程,一個是常見的batch-size warmup,另一個是受微軟Phi系列模型啟發,利用現有的性能良好的ModernBERT-base模型權重,通過將基礎模型的權重「平鋪」擴展到更大的模型,提高權重初始化的效果。
作者透露將將公開checkpoints,以支持後續研究。
誰打造的?
前面提到的Jeremy Howard是這項工作的作者之一。
ModernBERT的三位核心作者是:
Benjamin Warner、Antoine Chaffin、Benjamin ClaviéOn。

Jeremy Howard透露,項目最初是由Benjamin Clavié在七個月前啟動的,隨後Benjamin Warner、Antoine Chaffin加入共同成為項目負責人。

Benjamin ClaviéOn、Benjamin Warner,同Jeremy Howard一樣,來自Answer.AI。Answer.AI打造了一款能AI解題、概念闡釋、記憶和複盤測試的教育應用,在北美較為流行。
Antoine Chaffin則來自LightOn,也是一家做生成式AI的公司。
團隊表示BERT雖然看起來大家談論的少了,但其實至今仍在被廣泛使用:
目前在HuggingFace平台上每月下載次數超6800萬。正是因為它的encoder-only架構非常適合解決日常出現檢索(例如用於RAG)、分類(例如內容審核)和實體提取任務。
Jeremy Howard表示明年將訓練這個模型的更大版本。
 Blog:https://huggingface.co/blog/modernbert
Blog:https://huggingface.co/blog/modernbertModernBERT-Base:https://huggingface.co/answerdotai/ModernBERT-base
ModernBERT-Large:https://huggingface.co/answerdotai/ModernBERT-large
論文:https://arxiv.org/pdf/2412.13663
參考鏈接:https://x.com/jeremyphoward/status/1869786023963832509