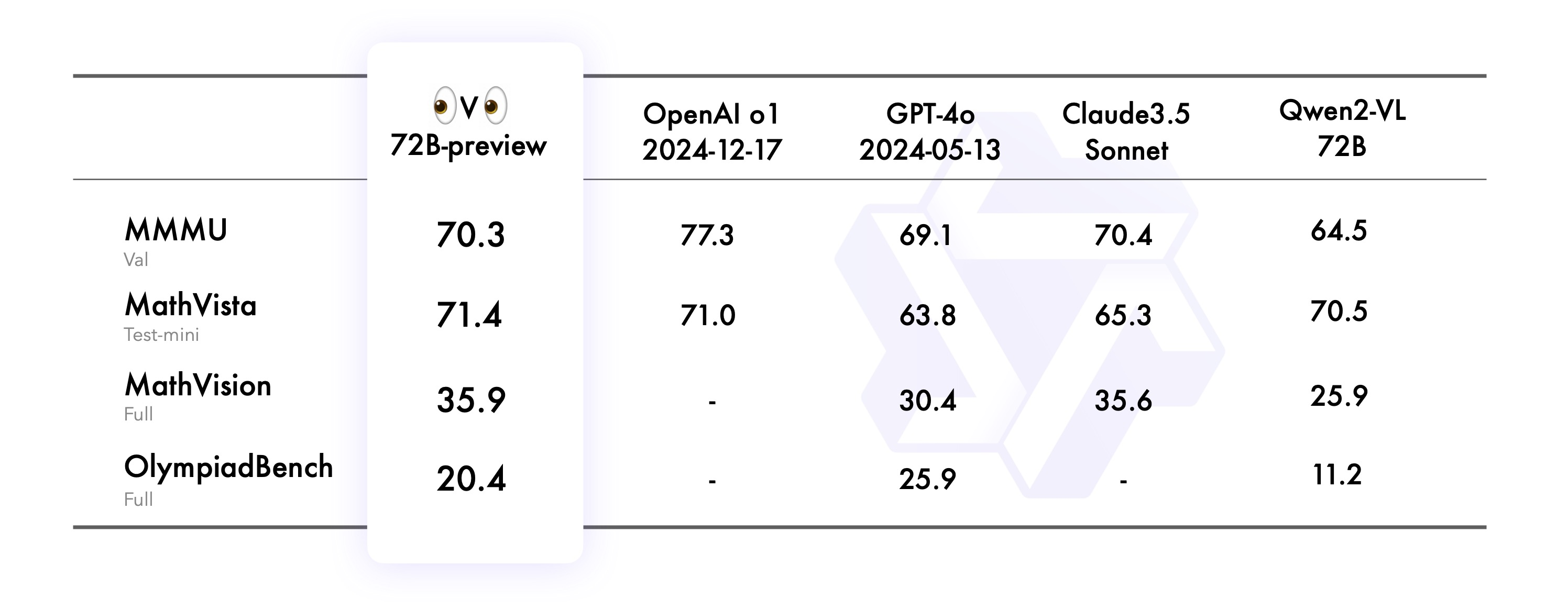
哈佛、史丹福最新研究:AI診斷準確率高達78.3%,AI看病能否又便宜又好?清華專家:難度仍大,醫生有經驗和直覺優勢
人工智能看病就要來了!?哈佛大學、史丹福大學、微軟等頂尖學府和機構的多名醫學、AI專家日前聯合開展了一項研究,該研究顯示,OpenAI旗下o1-preview模型在鑒別診斷中的準確率高達78.3%。
該模型在醫學推理多項任務中表現出卓越的能力,在鑒別診斷生成(判斷「這是什麼病」)、診斷臨床推理(判斷「這最可能是什麼病」)和管理推理(判斷「應該如何治療」)方面,甚至達到了超人類水平。AI看病比醫生強?清華大學電子工程系長聘教授、清華大學精準醫學研究院臨床大數據中心共同主任吳及告訴記者,醫療本質上是人對人的服務,這一過程非常複雜,醫學診療不僅包含理論和科學,還涉及大量經驗,很多時候依賴專家的直覺。「AI在醫療領域的應用難度較大,但會逐步滲透到一些典型場景中。」
據市場研究機構Global Market Insights的統計,2023年,醫療保健領域的AI市場規模價值為187億美元,預計到2032年將達到3171億美元,2024年至2032年的復合年增長率為37.1%。
哈佛大學、史丹福大學、微軟等頂尖學府和機構的多名醫學、AI專家日前聯合開展了一項研究,對OpenAI旗下o1-preview模型在醫學推理任務的表現進行了綜合評估。
結果顯示,o1-preview模型在多項任務中表現出卓越的能力,在鑒別診斷生成(判斷「這是什麼病」)、診斷臨床推理(判斷「這最可能是什麼病」)和管理推理(判斷「應該如何治療」)方面,甚至達到了超人類水平。
目前,AI技術在一些醫院已初步展開應用,覆蓋了分診導診、預先問診、病曆生成等多種場景。
清華大學電子工程系長聘教授、清華大學精準醫學研究院臨床大數據中心共同主任吳及告訴《每日經濟新聞》記者,「AI在醫療領域的應用難度較大,但會逐步滲透到一些典型場景中。」
 圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》
圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》o1-preview診斷準確率高達近80%
該研究通過五個實驗對o1-preview模型進行了綜合能力評估,包括鑒別診斷生成、診斷推理、分診鑒別診斷、概率推理和管理推理能力。
這些實驗由醫學專家使用經過驗證的心理測量方法進行評估,旨在將o1-preview的性能與以前的人類對照組和早期大型語言模型基準進行比較。結果表明,與醫生、已有的大語言模型相比,o1-preview在鑒別診斷、診斷臨床推理和管理推理的質量都有明顯提高。
在評估o1-preview鑒別診斷生成的能力時,研究人員使用了發表在國際頂級醫學期刊《新英格蘭醫學雜誌》(NEJM)上的臨床病理會議(CPC)病例。結果表明,o1-preview在鑒別診斷中的準確率高達78.3%。
 圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》
圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》值得注意的是,o1-preview在88.6%的病例中得出了準確或非常接近準確的診斷結果,而GPT-4只有72.9%。
 圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》
圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》此外,在87.5%的病例中,o1-preview選擇了恰當的檢查項目;另在11%的病例中,兩位醫生均認為該模型所選檢查方案是有效的;而在僅有的1.5%的病例中,其檢查方案被兩位醫生認為是無效的。
 圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》
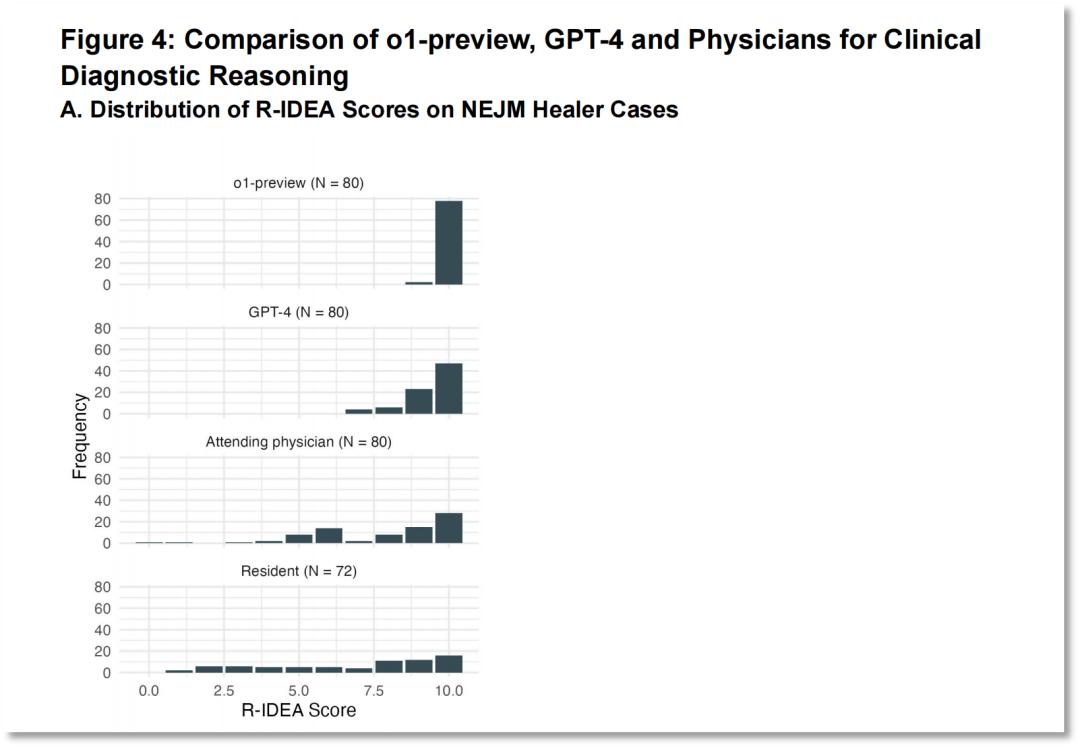
圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》為了進一步評估o1-preview的臨床推理能力,研究人員使用了NEJM Healer(一款在線工具,學習者可以通過與虛擬患者的互動來提升他們的臨床推理和診斷技能)中的20個臨床病例。
結果表明,o1-preview的表現明顯優於GPT-4、主治醫師和住院醫師。在80例病例中,有78例獲得了完美的R-IDEA評分。R-IDEA評分是一個10分製量表,用於評估臨床推理能力。
 圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》
圖片來源:論文《大型語言模型在醫學推理任務中的超人表現》此外,研究人員還通過灰質管理案例和標誌性診斷案例評估了o1-preview的管理和診斷推理能力。
在灰質管理案例中,o1-preview得分明顯高於GPT-4、使用GPT-4的醫生和使用傳統資源的醫生。在標誌性診斷案例中,o1-preview的性能與GPT-4相當,但優於使用GPT-4或傳統資源的醫生。
研究仍有局限性
研究表明,大語言模型如o1-preview在輔助醫生進行診斷決策方面具有巨大潛力。然而,該項研究也具有部分局限性。
首先,o1-preview有「囉嗦」傾向,而這種特性可能會讓其在試驗中取得更高分。
其次,目前的研究只反映了模型性能,但現實中離不開人機交互。人機交互對開發臨床決策輔助工具至關重要,下一步應該確定大語言模型(如o1-preview)能否增強人機交互。人類與計算機之間的交互或許是不可預測的,表現良好的模型與人類交互中甚至可能出現能力退化的情況。
第三,研究只考察了臨床推理的五個方面,但目前已知有幾十個其它任務可能對實際的臨床護理有更大影響。
第四,研究案例集中在內科,並不能代表所有醫療實踐。此外,研究在設計上也未將診斷類型、患者個體差異以及就醫地點的不同等因素納入考量。
研究人員強調,醫學領域診斷推理的基準正迅速接近飽和狀態,因此亟需開發更具挑戰性和貼近實際應用的評估手段。他們呼籲在真實的臨床環境中測試這些技術,並為臨床醫生與人工智能的合作創新做好準備。
專家:AI將逐步滲透醫療典型場景
目前,AI技術在一些醫院已初步展開應用,覆蓋了分診導診、預先問診和病曆生成等多種場景。
美國耶魯大學教授威廉·基西克(WiliamKissick)提出了著名的「醫療不可能三角」理論。這個理論指出,在既定的約束條件下,一個國家的醫療系統很難同時實現提高醫療服務質量、增加醫療服務可及性和降低醫療服務的價格。現實中的醫療困境,如「看病難、看病貴」以及不斷出現的醫患矛盾,正是傳統醫療體系「醫療不可能三角」的具體表現。
 圖片來源:甲子光年智庫
圖片來源:甲子光年智庫而醫療AI的興起可能為解決這一難題提供新的答案。AI賦能下的醫療服務可以大規模接待患者,實現隨時隨地的無限供應,並且其水平會隨著持續訓練迅速提升,已經達到了具有10至15年臨床經驗醫生的水準,且每月還在不斷進步。
清華大學電子工程系長聘教授、清華大學精準醫學研究院臨床大數據中心共同主任吳及在接受《每日經濟新聞》記者採訪時指出,相比自動化、智能設備等場景,AI在醫療場景的應用更為複雜。
吳及提到,醫療本質上是人對人的服務,這一過程非常複雜,醫學診療不僅包含理論和科學,還涉及大量經驗,很多時候依賴專家的直覺。因此,「AI在醫療領域的應用難度較大,但會逐步滲透到一些典型場景中。」
據市場研究機構Global Market Insights的統計,2023年,醫療保健領域的AI市場規模價值為187億美元,預計到2032年將達到3171億美元,2024年至2032年的復合年增長率為37.1%。
本文來自微信公眾號「每經頭條」,作者:每經記者,36氪經授權發佈。