o3 都要來了還能做點什麼?人大&螞蟻團隊:自下而上數據合成讓大模型能夠多模態推理

此項研究成果已被 EMNLP 2024 錄用。該論文的第一作者是中國人民大學高瓴人工智能學院碩士生程傳奇,目前為螞蟻技術研究院實習生,其主要研究領域為對話系統和多模態大模型。螞蟻技術研究院副研究員關健為共同第一作者。
在滿血版o1發佈大概兩個星期之後,OpenAI又預告了其後繼模型o3的到來,讓人們對AGI的實現充滿了期待。除了強大的語言推理能力外,滿血版o1的一項重要能力是能夠進行多模態推理,即從「所見」、「所思」到「所得」。然而,在語言推理的研發已經進行得如火如荼之際,多模態推理的研究似乎正方興未艾。
多模態推理的基礎是多模態大模型,其中以視覺語言模型(Visual Language Models)最為受到關注。然而,當前的視覺語言模型在處理某些具體任務時仍面臨挑戰。例如,在識別圖像中細微物體、準確計數等場景下,即使OpenAI-o1也往往難以給出令人滿意的結果。這種局限性源於視覺信息本身的特點——與一維的文本相比,視覺信息包含了更為豐富的維度,涉及空間關係、大小比例、背景環境等多個方面。人類在處理此類視覺任務時,通常會採用細緻的觀察和逐步推理的方式,而這正是目前視覺語言模型所欠缺的能力。
更具挑戰性的是,即便研究者們認識到了推理能力對視覺語言任務的重要意義,訓練數據的匱乏仍然是一個亟待解決的問題。一方面,視覺語言模型需要從數據中學習如何結合視覺輸入和語言模型所有知識進行推理,另一方面,包含完整推理鏈路的多模態數據卻十分稀少。這一矛盾凸顯出自動化視覺推理數據合成的重要性。
針對這些問題,來自中國人民大學高瓴人工智能學院和螞蟻技術研究院的研究團隊在EMNLP 2024上提出了一套解決方案。他們基於「由淺入深」(from the least to the most)的理念,設計了一個即插即用的視覺推理框架,並配套開發了一種高效的自下而上數據合成方法。這種方法可以低成本合成高質量視覺推理鏈。目前該團隊已開源了包含百萬量級推理鏈的數據集,希望能夠推動多模態推理的研究。

論文標題:From the Least to the Most: Building a Plug-and-Play Visual Reasoner via Data Synthesis
論文地址:https://arxiv.org/pdf/2406.19934
Github:https://github.com/steven-ccq/VisualReasoner
Dataset:https://huggingface.co/datasets/orange-sk/VisualReasoner-1M
1
視覺語言模型的「致命弱點」:為什麼簡單的問題總是答不對?
儘管視覺語言模型在多項任務上展現出令人矚目的性能,但在一些對人類而言相對簡單的問題上卻常常出現錯誤判斷,這嚴重製約了這些模型在實際場景中的應用。研究團隊通過對比多個模型在不同數據上的錯誤樣例,總結出以下3點原因:
1.「老花眼」—— 人類在觀察圖像時可以自然地將注意力集中到特定區域,並能夠靈活地「放大」關注區域以獲取更多細節信息。然而,現有的視覺語言模型往往傾向於對圖像進行整體性處理,缺乏對局部細節的精確感知能力。這導致模型在需要識別小物體或分析細微特徵時表現欠佳。
2.「注意力渙散」——計數問題一直是視覺大模型的痛點,尤其在有混淆項、背景複雜或者部分遮擋的場景下,模型總是會出現多數和漏數的現象。
3.「文盲」——文字信息是視覺信息的重要組成部分,而在文字密集或者出現藝術字的情況下,模型對文字的捕捉能力較差,進而影響了其對於圖片內容的理解。
針對這些問題,學術界已有不少專門性的優化工作。但這些方案往往存在兩個顯著局限:其一是解決思路過於片面,僅針對某個具體問題進行優化;其二是實現方式較為複雜,往往需要修改模型架構或重新訓練,難以快速應用。在當前大模型蓬勃發展的背景下,一個理想的解決方案應當具備即插即用的特性,能夠在不改變原有模型架構的前提下,全面提升模型的各項能力。
2
由淺入深:即插即用的視覺推理範式
如何讓視覺語言模型具備類人的深度思考能力,從而更好地應對複雜的視覺推理任務?研究團隊提出了一種 「由淺入深」的多步視覺推理框架。該框架基於任務分解的思想,通過將複雜問題系統地拆解為一系列可控的子問題,最終通過逐步推理得出答案。
該推理範式具有3大優勢:
1.逐步拆解,降低任務難度
傳統方法往往試圖直接解決整體問題,這種做法在面對複雜場景時容易力不從心。而所提推理框架採用「分而治之」的策略,將複雜問題分解為多個明確且簡單的子任務。
2.推理鏈路透明,結果可解釋
當前主流的視覺語言模型往往採用端到端的方式直接輸出結果,這種「黑盒式」的處理方式存在兩個明顯問題:(1)難以理解模型的決策依據;(2)無法驗證推理過程的正確性。相比之下,所提框架將推理過程完全透明化,每一步推理都可被追蹤和驗證。這種設計不僅提升了模型輸出的可信度,也為後續優化提供了清晰的方向。
3.開箱即用,無需額外設置
所提框架無需修改原有模型架構,不依賴額外的訓練過程,可在任意視覺語言模型上即插即用。實驗結果表明,該框架能夠在多個主流視覺語言模型上實現顯著且穩定的性能提升。
3
「由淺入深」推理框架實現細節
1.工具定義
為了模擬人類在視覺任務中的認知過程,研究團隊設計了四種專門的工具,每種工具都對應人類處理視覺信息時的特定能力:
定位工具 (Grounding Tool) 通過接收自然語言描述,在圖像中精確定位相應的目標區域,並輸出標準化的邊界框(bounding box)。這一工具模擬了人類在視覺任務中首先鎖定關注區域的行為,為後續的細節分析提供準確的空間定位信息。
高亮工具 (Highlight Tool) 則模擬人類的選擇性注意力機制,根據文本描述在圖像中創建高亮遮罩,突出顯示需要重點關注的區域,同時有效降低其他區域帶來的干擾信息。這種選擇性注意力機制使模型能夠更專注地處理關鍵信息。
文本工具 (OCR Tool) 專門負責提取和理解圖像中的文字信息。與普通的視覺特徵不同,文字承載了更為明確和豐富的語義信息,需要特殊的處理機制。該工具能夠準確識別各種場景下的文本內容,為後續的推理過程提供關鍵的文本線索。
問答工具 (Answer Tool) 作為整個推理框架的決策中樞,基於現有的視覺語言模型構建,能夠有效整合來自其他工具的多模態信息,並生成最終答案。這一工具採用即插即用的設計理念,無需額外訓練即可與不同的視覺語言模型協同工作。

2.任務拆解
給定一個原始問題和原始圖片,所提推理範式會將複雜問題逐步分解為一系列相互關聯的子任務。每個子任務都與特定工具相對應,通過工具的調用獲得階段性結果。
值得注意的是,與一次性完成問題拆解不同,該推理範式的拆解是分多步進行的,每步之間存在依賴。這是因為動態的推理更加貼近人類解決視覺問題時的行為模式。一方面,歷史步驟得到的信息會對當前步驟產生影響,因此需要動態調整推理鏈路;另一方面,隨著推理進行,其中一些步驟涉及到圖像內容的修改(例如裁剪和放大)。在完成所有必要的推理步驟後,系統最終調用問答工具,整合全部推理結果,生成最終答案。
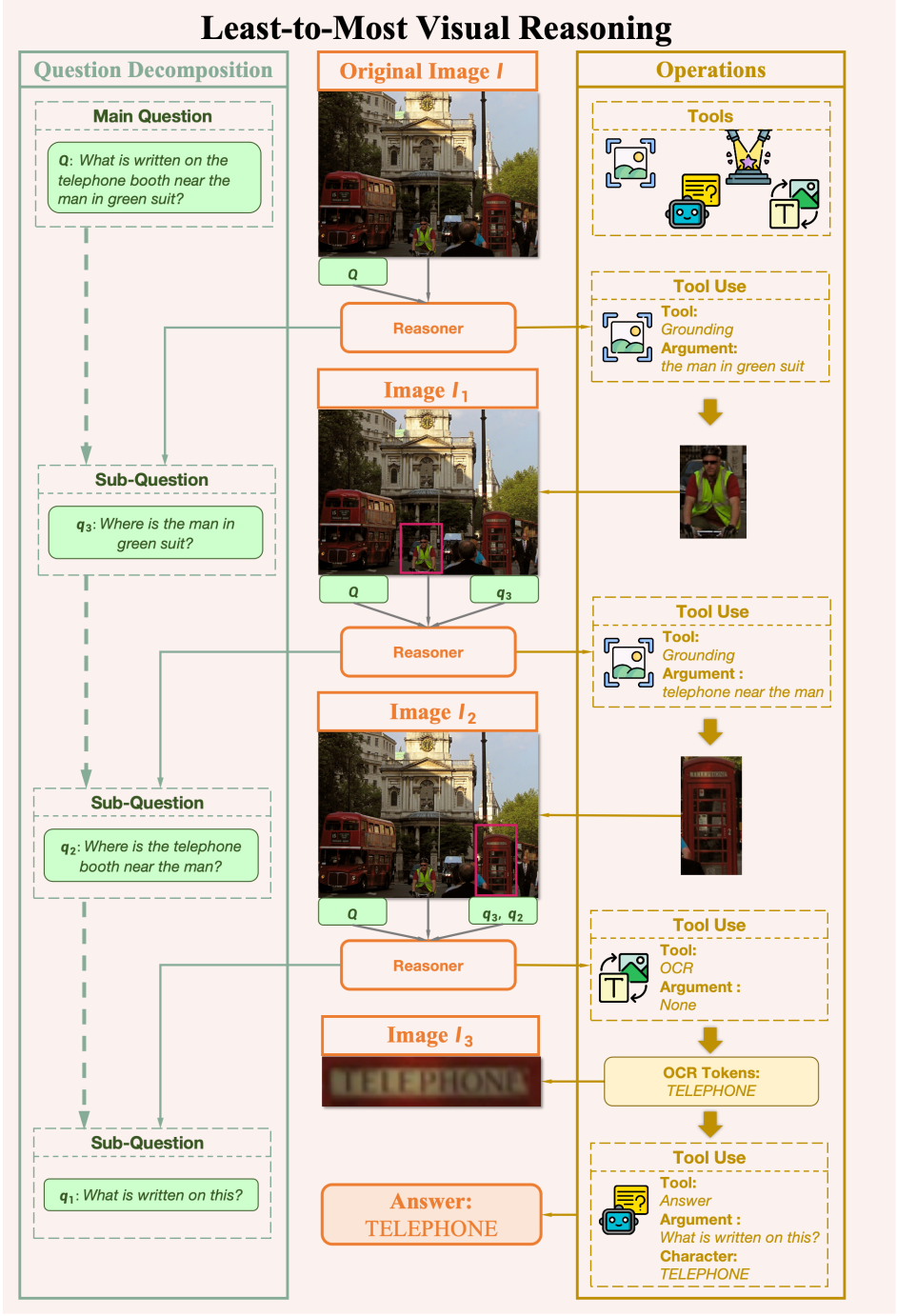 推理框架示意圖
推理框架示意圖4
自下而上的數據合成方法
視覺推理數據的匱乏一直是製約相關研究發展的關鍵瓶頸。雖然目前已有部分數據集包含推理鏈信息,但這些數據集存在兩個主要局限:一是數據規模過小,難以支撐大規模模型訓練;二是推理鏈以純文本形式呈現,更像是結果說明而非真實的推理過程。為突破這一瓶頸,研究團隊基於所提推理框架設計了一套自下而上數據合成方法。該方法能夠以低成本自動生成高質量的視覺推理鏈數據。具體來說,該方法由如下4個模塊組成:
1.實體識別
給定一張圖片,實體識別模塊從中抽取出可被識別的實體,返回實體名稱與位置信息。
 實體識別
實體識別2.多級節點構建
在完成實體抽取的基礎上,構建3類不同層次的節點。每個節點由若干實體組成,並配有不同粒度的文檔。3類節點分別是:
單個實體(Single-Entity):最低層次的節點,僅包含單個實體。該節點的文檔由多個結構化的屬性組成,包含位置、大小、顏色、文本內容等。每個屬性使用專門的工具完成標註,目的是記錄實體的詳細情況。
實體組合(Entity-Group):中間層次的節點,包含相鄰的若幹個實體。該節點的文檔為一句簡短的文本描述,目的是簡要概述節點包含的內容。
整張圖片(Whole-Image):最高層次的節點,包含整張圖片。該節點的文檔為一段詳細的描述,目的是儘可能地捕捉細節信息。
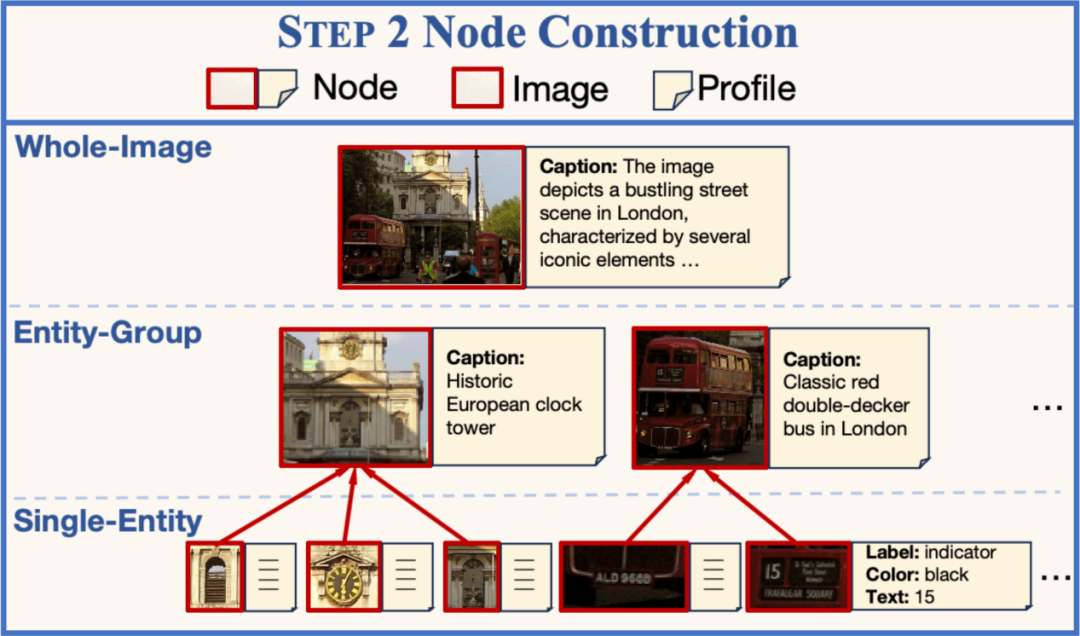 多級節點構建
多級節點構建3.子問題設計
推理過程由一系列簡單的子問題及其對應的工具調用方式組成。在推理過程合成階段,系統首先從已構建的節點集合中采樣出一個節點鏈,並通過精心設計的規則來約束相鄰節點間的連接關係。為確保推理過程的合理性,鏈的最後一個節點必須是「整張圖片」節點。對於鏈中的每一對相鄰節點,系統會利用一個稱為「Questioner」的語言模型來設計子問題。具體而言,在給定節點對應的文本描述信息以及期望使用的工具後,Questioner會生成一個針對頭節點特定屬性的子問題,同時輸出解答該問題所需的工具參數。通過反復迭代這一過程,最終可以得到一系列邏輯連貫的子問題,從而構建出完整的推理路徑。
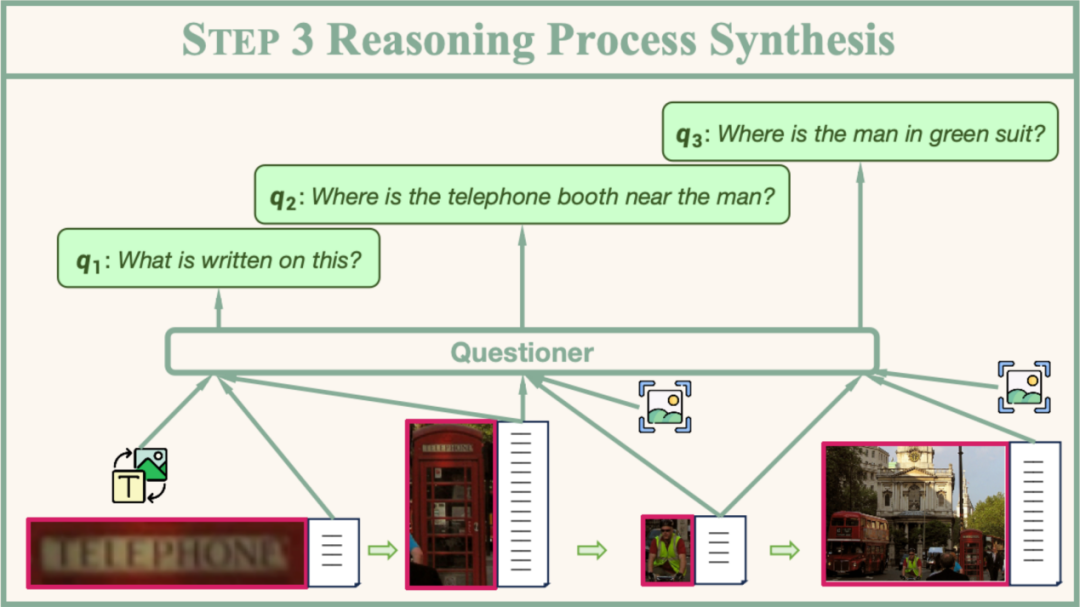 子問題設計
子問題設計4.主問題合成
給定一系列有序的節點,在完成兩兩之間的子問題生成後,接下來要進行的就是主問題的合成。主問題合成模塊會逆序遍曆節點,以迭代更新的方式逐步合成主問題。每次更新時,系統會利用一個稱為「Combiner」的語言模型接收中間態主問題Q*和當前子問題q,將q合併進入Q*。完成遍曆後即可得到主問題。
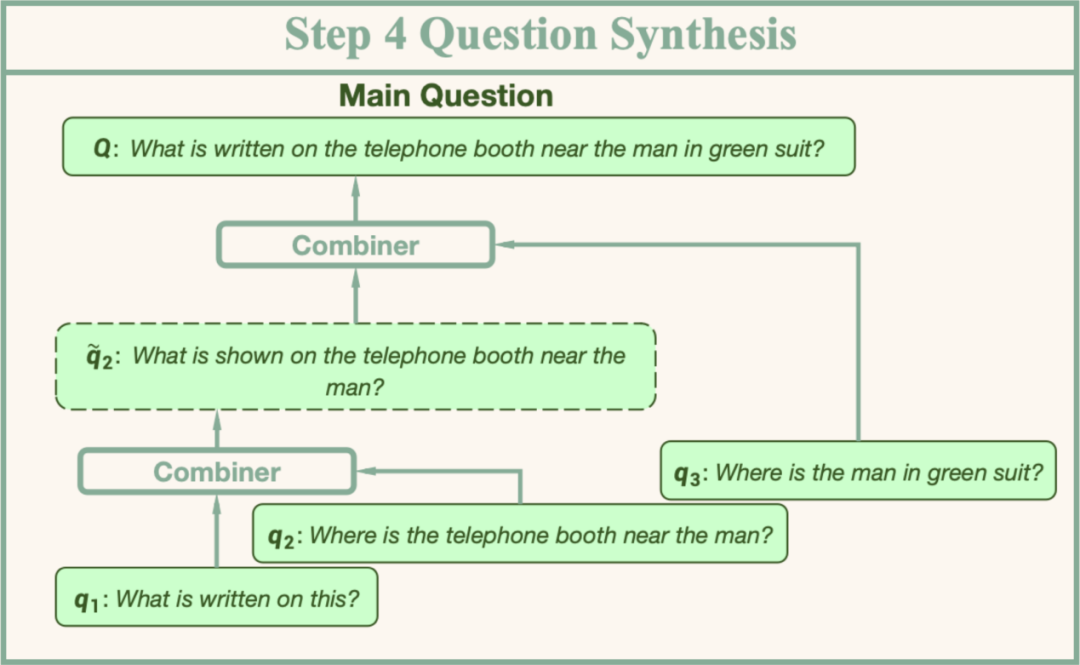 主問題合成
主問題合成該過程中涉及到的子問題設計模型Questioner和主問題合成模型Combiner均已開源。通過這種方式,研究團隊構建並開源了百萬級推理數據集。
5
實驗效果
1.多個場景,一致提升
研究團隊在四個具有代表性的基準測試集(GQA、TextVQA、ST-VQA和TallyQA)上進行了系統性評估。實驗結果展現出”由淺入深”推理框架的顯著優勢:
場景普適性:測試集覆蓋多樣化的視覺任務場景,包含一般性視覺問答、文本視覺問答和計數等典型任務,「由淺入深」推理框架在所有任務類型上均實現了顯著性能提升;
模型適應性:實驗橫向對比了不同架構的視覺語言模型,覆蓋多種模型規格,驗證結果表明「由淺入深」推理框架能夠穩定提升各類模型的性能。
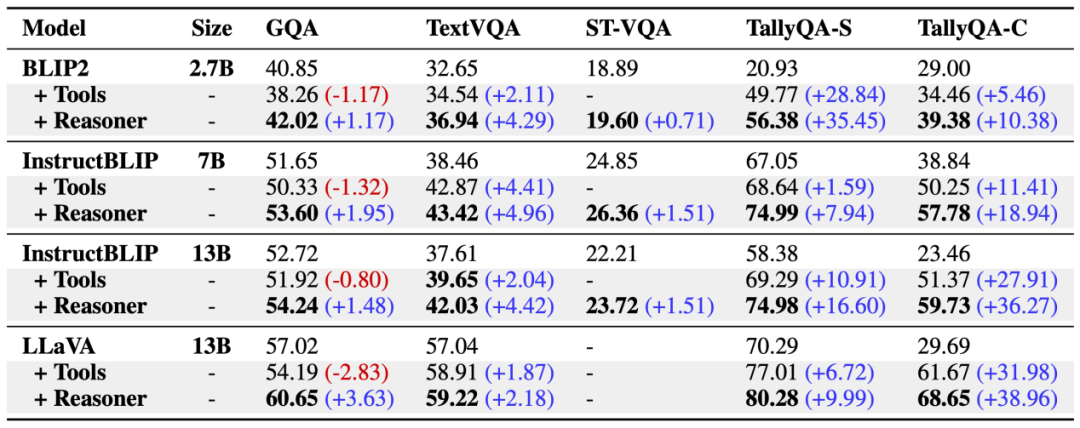 實驗結果(其中「+Reasoner」表示本文提出的推理框架)
實驗結果(其中「+Reasoner」表示本文提出的推理框架)2.更大規模,更好效果
研究團隊通過控制變量實驗,系統考察了訓練數據規模對性能的影響。結果顯示性能隨數據規模增長呈現持續上升趨勢,尚未出現明顯的性能飽和現象,仍具有較大的性能提升空間。這也證明了自動合成大規模數據的必要性。而合成同樣規模的數據,若調用閉源模型接口則花費是巨大的。使用本文提出的自動化合成框架,最低只需要一張顯卡即可完成——速度上甚至更快!
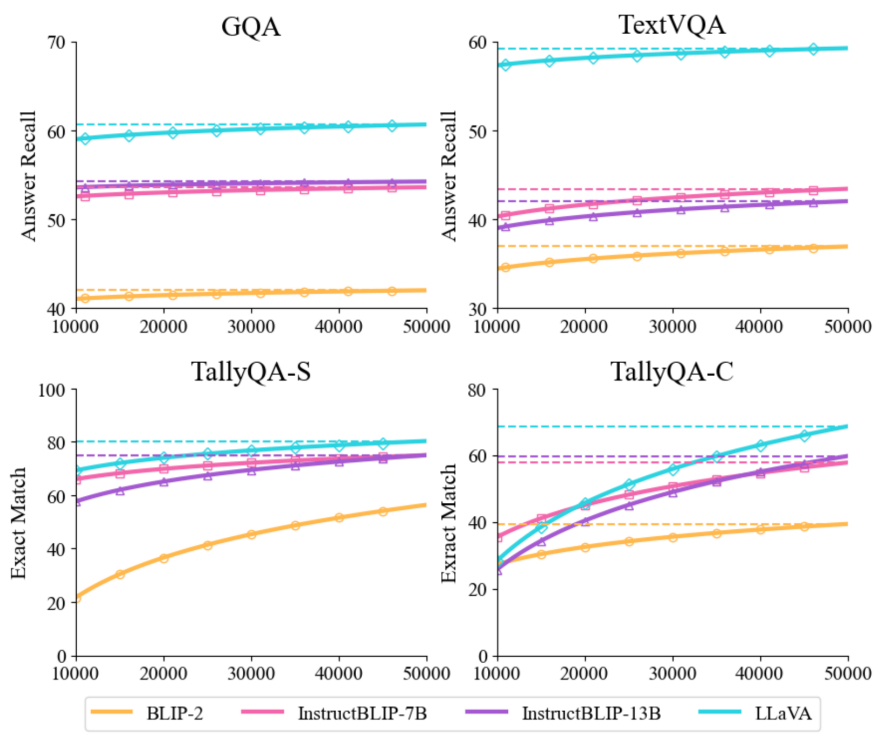 訓練數據集的增大有助於性能提升
訓練數據集的增大有助於性能提升3.在更先進的視覺語言模型上仍然提升顯著
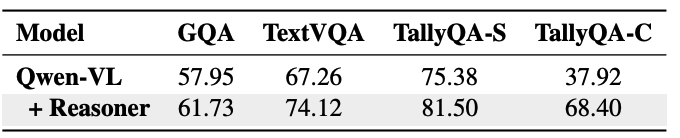
為了驗證所提框架在更先進的視覺語言模型上的效果,作者還對Qwen-VL等新一代模型進行了實驗。考慮到這類模型本身就具備感知圖像中邊界框等能力,可能已經在一定程度上繼承了外部工具的功能,作者將合成的數據集轉換為端到端格式——即按順序將每個推理步驟的輸入和輸出組合在一起,從而避免顯式調用工具帶來的計算開銷。實驗結果表明:
在端到端版本的數據集上微調後的Qwen-VL模型在所有數據集上都取得了顯著提升。
使用所提方法並沒有帶來明顯的時間開銷增加,每個樣本的處理時間僅從原始模型的1.1秒略微增加到1.4秒。
上述結果進一步證實了本文方法的實用性和高效性。
4.樣例展示


6
結語
本研究提出了一種「由淺入深」的視覺推理範式,通過將複雜的合成任務分解為一系列簡單的子任務,並利用自下而上的數據合成方法,成功地自動構建了大規模的視覺推理數據集。在多個視覺問答基準測試集上的實驗結果表明,該範式能夠顯著提升現有視覺語言模型的推理能力。這一成果為增強視覺語言模型的推理能力提供了新的範式。展望未來,我們將繼續深化這一研究方向,探索更複雜的推理模式和更廣泛的應用場景,從而實現 「像人類一樣思考,獲得真正通用的推理能力」。