國產大模型2025考研數學排行榜:僅前兩名成績破百

2024 年就要結束了,在這一年里,大模型的智力水平究竟長進了多少?
上週日,2025考研初試剛剛結束,我們趁熱拿考研數學卷子,去測測主流的幾家國產大模型,看看他們的真實智商水平如何。
5位國產大模型考生名單:
大廠巨頭代表隊:字節豆包、阿裡通義
創業公司代表隊:智譜、Kimi
私募巨頭代表隊:DeepSeek
記得6月份高考的時候,很多媒體做了大模型高考成績評測,結果發現大家的語文成績都能考100分以上,但數學成績基本都慘不忍睹,低的只有37分,高的也不過60多分,沒有一家能及格。要知道高考數學的滿分是150,只有考到90分以上才算及格。
這也側面說明,起碼在自然語言理解這一塊,大模型基本已經「及格」,但在人類與其他物種拉開差距的「邏輯思維」能力上,哪怕還需要繼續進化。
不過,2024年下半年,尤其是9月份Open AI的o1推理模型出來之後,在新的強化學習技術範式下,大模型似乎找到了破解數理化等領域難題和複雜任務的鑰匙。Kimi、DeepSeek、通義等公司,也相繼推出了自己的支持思維鏈(Chain of Thought)的推理模型,數理化水平上了一個新台階。
廢話少說,直接開測!
我們選取了難度適中的2025考研數學三作為參考試卷,每個題目各家模型有兩次作答機會,得分取兩次的平均值。
為了確保測試的公平,我們都採用各家產品的最新版本 (豆包和通義不能選擇模型,採用了預設模式;Kimi採用新推出的視覺思考版;DeepSeek打開「深度思考」開關,智譜清言採用 GLM-4-Plus模型),上傳完全一樣的 22 道題目截圖,輸入給大模型的文字提示(Prompt)也基本一樣,模擬真實場景,「解答這道題」、「這道題選什麼」、「解一下這道題」「這個題答案是什麼」。
一、2025考研數學:兩家成績破百
真實水平如何?讓我們直接看成績:
從最終的測試結果來看,本次考研數學初試數學成績,有兩家模型破百,其中 Kimi 視覺思考版的得分為 133分,DeepSeek 103.5分。通義90分,及格了。豆包和智譜都獲得88.5分,接近及格。相比6月份的高考數學成績,大家都進步了不少。Kimi 和 DeepSeek 進步尤其快。
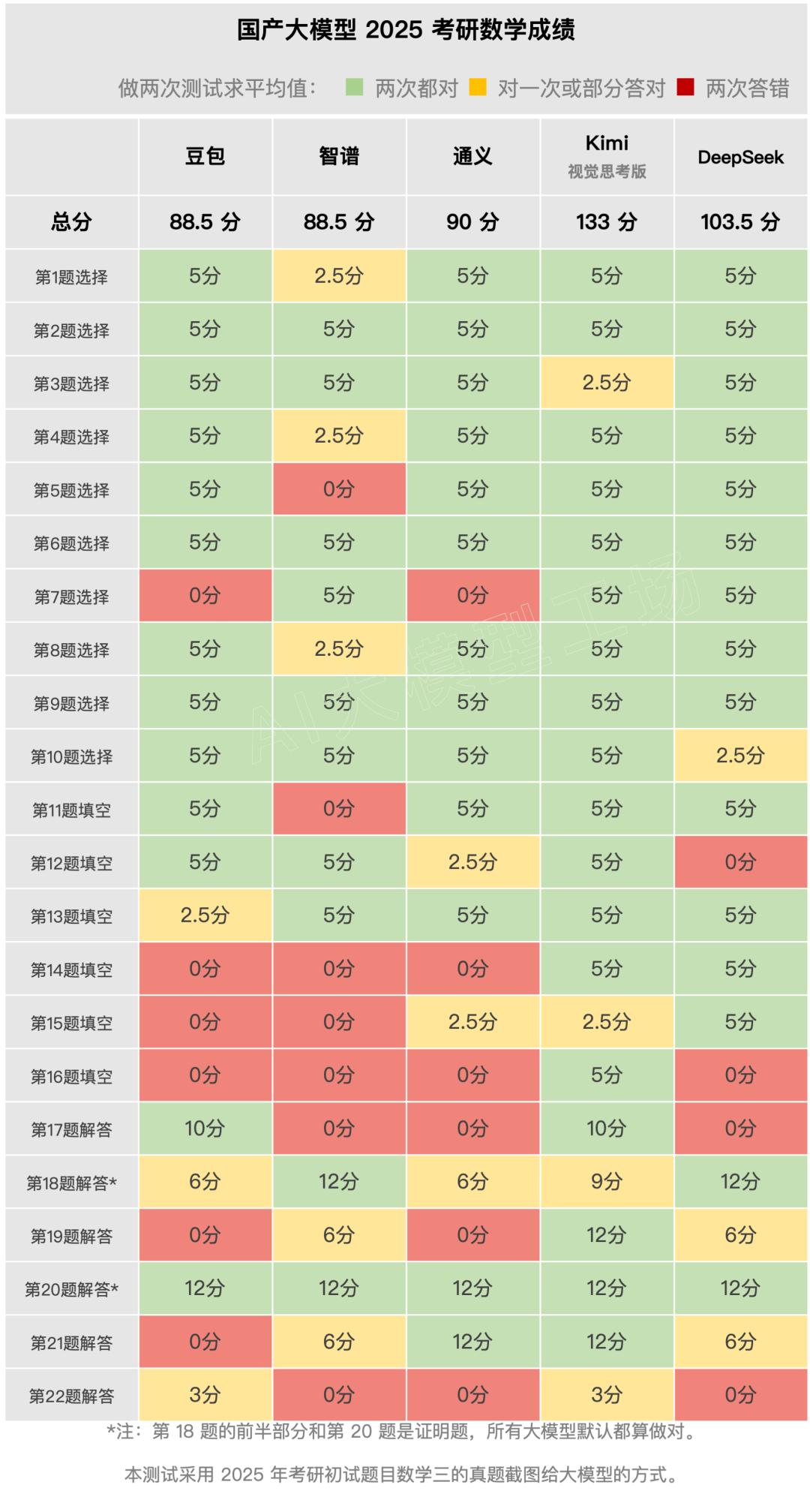
以往做小學數學題都能跌跌撞撞的國產大模型,如今做研究生級別的數學題,居然有幾家已經遊刃有餘,這挺讓我們感到意外的。不過,從最後一道題的成功率,還有一些進步空間。
二、解題過程兩種風格:給答案 vs 給思路+答案
僅僅按分數來算,誰更有可能最後上岸,其實一目瞭然。
不過做這套考研數學真題的成績,也並不能完整展現這些模型的全部能力,但對於一些備考的學生黨來說,在面對同樣的題目時,誰的解題思路更完整,推導步驟更豐富,誰的參考性和實用性自然就越大。
先來看一道代數方面的三角函數選擇題。

這道題的正確答案是C,但不同模型得到C的過程很有意思。
先來看豆包的解題過程

豆包同樣給出了正確答案,但解題過程相對簡略,更像考研參考書上的一些標準答案,如果要知道更詳細的解題過程,尚需購買對應的考研名師課程作為輔助。
智譜清言的解答過程相對尷尬一些。因為這道題它沒做對,第一遍測試選B,第二遍測試選了A。
第一遍測試B:

第二遍測試A:

不過,即便做錯,也給出了相對完整的思考過程,「錯」有可原。
再來看Kimi視覺思考版。

可以看到,Kimi視覺思考版在給出正確答案之餘,也會給出完整的推導過程和解題思路。對於一些考研黨來說,具有較高的參考價值,有助於檢查錯題和舉一反三。
阿裡通義和Deepseek的回答與豆包類似,相對而言,這兩家模型展現的步驟會簡略一些。
通義千問

Deepseek

再來看一道填空題。

這是它的標準答案:漸進線方程為y=3和y=-3
可以看到,跟前述選擇題一樣,Kimi思考版的解題過程較為翔實,推導細節很多,並最終給出了正確答案。

豆包的推導過程相對簡略一些,但也可以看到明顯的推導過程,也具備不錯的可參考性。阿裡通義和deepseek類似過程略簡單,但給出了正確答案。

遺憾的是智譜在這道題上,兩次結果都是錯誤的。

但在下面這道定積分的題上,各家模型差距就較為明顯了。
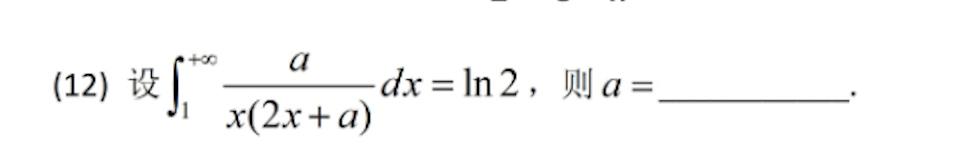
首先放正確答案:a=2
Kimi思考版的表現較為穩定,在給出足夠多的推導步驟之後,還有一次驗算,最後輸出了a=2的正確結果。

豆包表現也較為穩定。不過推導步驟一如既往地簡潔。

智譜清言在解決這個問題的時候,第一遍回答正確,但問題在於沒有使用自然語言,使用的是代碼,對普通學習者參考價值有限,第二遍測試則直接沒有給答案,並且認為題目設置有問題。


通義的表現尚算正常,第一次的回答錯誤,第二次給出正確答案。但Deepseek就比較尷尬,第一次它無法回答。

第二次則陷入死循環,回答超過3分鐘還在寫答案。
如果是一些更難的題目,有些模型就難以cover住了。
譬如下面這道。
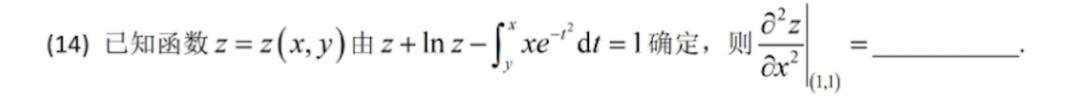
照例先來正確答案。

kimi的回答如下 ,雖然最終結果跟標準答案長得不太一樣,只是不同的寫法,結果依然正確。

豆包在兩次測試中,給出了兩次回答,但都是錯的,這是第一次。
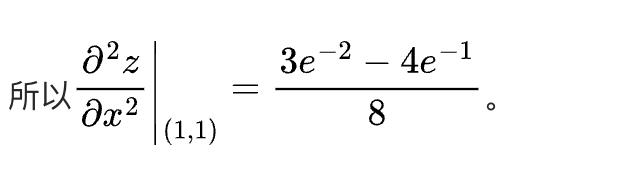
第二次:

智譜清言的兩次回答過程,均出現了無法回答的情況。

通義算是能寫完過程的,給出的兩次回答也不一樣,但很遺憾,還是錯的。

Deepseek表現出乎意料,跟kimi一樣雖然寫法不一樣,但結果正確。

結語
但在僅僅幾個月前,大模型廠商還在滿足於寫高考滿分作文,相比以往,它的邏輯思維和綜合能力,早已不可同日而語。
須知,無分文理,一旦拔高到科研的高度,以數理化為代表的邏輯能力是大模型可用,堪用、好用的基石,而數理化解題能力的高低,則是大模型智力的直接體現。
隨著大模型能力的不斷增強,在人類探索更前沿的科技領域時,以往尚且「雞肋」的大模型,如今已經能成為不少研究者的助手。或許未來,當AI的能力真的達到人類的TOP 1%各領域專家水平,甚至超過人類水平,在AI的幫助下,我們對宇宙的認識真的有機會達到人類此前不曾達到的新高度。希望那時候,AI 還是人類的好朋友。
本文來自微信公眾號「AI大模型工場」,作者:參商,36氪經授權發佈。



















