o3挑戰ARC-AGI,遇見大網格就懵圈?英國工程師:ARC-AGI不適合大模型
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
o3在超難推理任務ARC-AGI上的成績,屬實給人類帶來了不少震撼。
但有人專門研究了它不會做的題之後,有了更有趣的發現——
o3之所以不會做這些題,原因可能不是因為太難,而是題目的規模太大了。
來自英國的ML工程師Mikel Bober-Irizar(不妨叫他米哥),對ARC題目進行了細緻觀察。
結果米哥發現,題目中的網格規模越大,大模型的表現也就越差。
而且不僅是o3,o1和o1 mini,還有隔壁的Claude,都出現了這樣的現象。
米哥的這項研究,引起了人們對大模型工作機制的許多討論。
世界首位全職提示詞工程師Riley Goodside看到後,也認為這是一項很好的研究。

大模型被困在了網格規模上
還是先簡單回顧一下ARC挑戰,題目帶有色塊的網格陣列(以文本形式表述,用數字代表顏色),大模型需要觀察每道題目中3個輸入-輸出示例,然後根據規律填充新的空白網格。
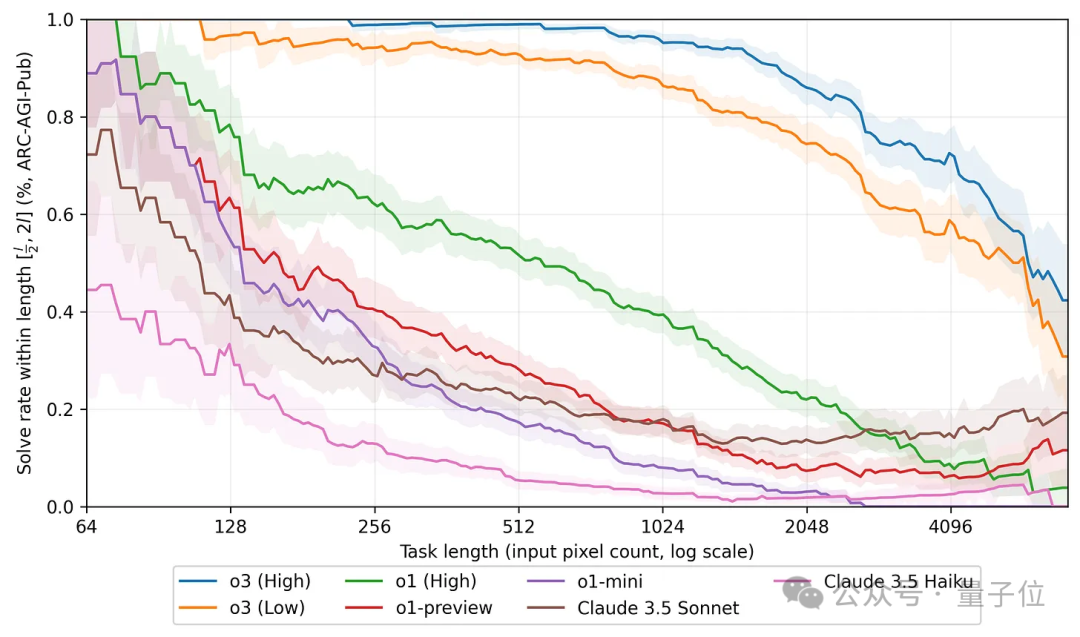
米哥發現,在ARC挑戰中,規模越大,也就是網格的數量越多,大模型的表現也就越差。
o3也逃不過這樣的魔咒,但相比於其他模型,o3表現的明顯下降出現得更晚,大約在網格數量達到1024個之後(請記住這個位置,後面還會講到)。
為了進一步驗證這個發現,米哥還用o1-mini進行了實際測試。
下圖當中,左右兩欄的題目乍一看上去好像沒什麼區別,但在右邊,米哥對網格進行了細粒度的切割,原來的一個格子被切成了4(2×2)個。
結果原來能做對的題,切成小塊之後,o1-mini還真就不靈了。

進一步地,米哥還對ARC數據集中的規模分佈進行了統計,結果剛好是規模在1024個像素的題目數量最多。
還記得前面o3成績下降趨勢突然變大的位置吧,剛好就是在1024附近。
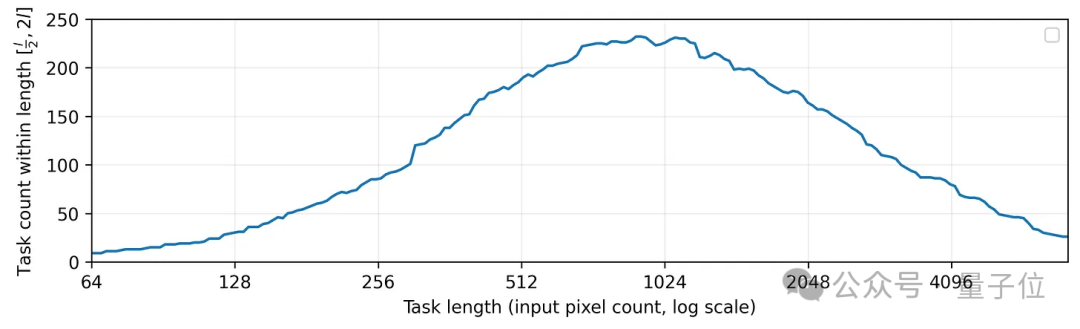
米哥認為,這就是o3在ARC挑戰上取得優異成績的重要因素,而其他模型成績不佳,是因為對應的小規模試題佔比較少。
所以在米哥看來,ARC挑戰並不能完全反映大模型真實的推理能力——有不少模型都被低估,o3則是被高估了。
ARC挑戰不適合大模型?
那麼,為什麼題目中網格數量一多,大模型的表現就不好了呢?
先來看米哥的分析。
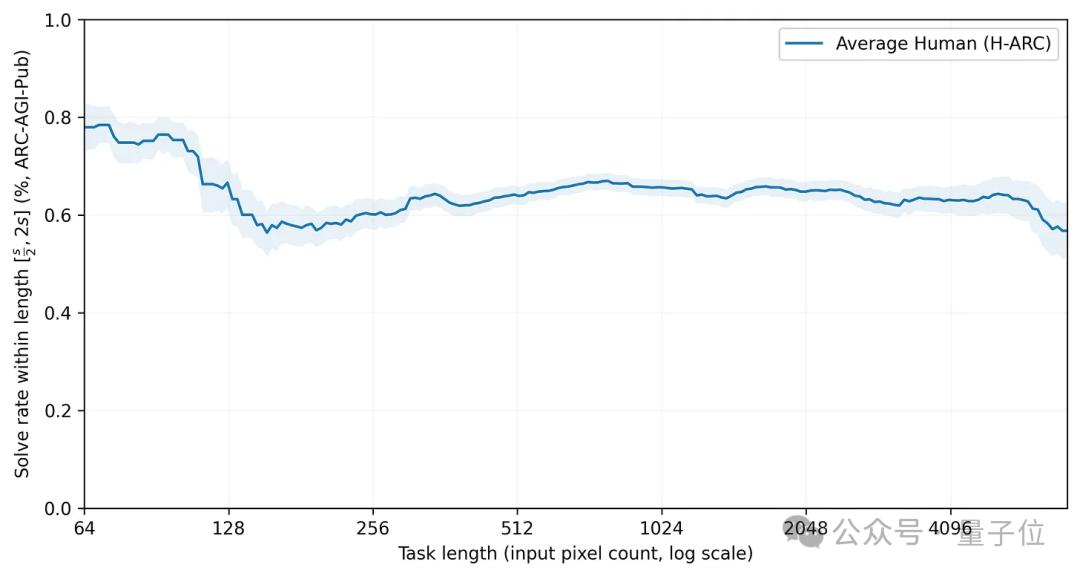
米哥引用了紐約大學的一項研究結果(arXiv:2409.01374),這項研究發現人類在挑戰這樣的問題時並不會出現這種現象。
如果在人類和模型之間做個比較,那麼在規模較小時o3的表現可以說完勝人類,但規模較大時優勝方就變成了人類。
這說明,大模型在解決此類問題時,思考方式和人類依然存在差別。
當然,大模型在挑戰ARC時看到的不是圖像,而是用數字代表的矩陣,這是顯而易見的,但差別還不止於此。
人類在面對ARC問題時,即使是用這種數字矩陣來表示,也能夠看出視覺信息,理解其中的位置關係。

在空間中,ARC是一個二維問題,需要跨行和列進行推理,但大模型在處理token時是以一維格式進行的。
這意味著,大模型進行跨列推理時,需要組合較長的上下文信息。
而隨著網格變得更大,模型需要對更長的上下文進行推理,並且必須對相距較遠的數字進行組合和推理。
米哥之前曾經和劍橋大學高級研究員Soumya Banerjee此前進行的一項研究(arXiv:2402.03507)表明,通過對矩陣進行90度旋轉,讓模型分別基於行和列進行推理,比直接做題成績提高了一倍。

所以米哥認為,是觀察問題的維度影響了大模型的成績,ARC這種任務並不適合大模型。
他還表示在NeurIPS上聽到了一個很好的類比——
將二維的ARC任務交給大模型,就像期望人類在四維空間中進行推理。
同時網民們還指出,雖然本質上涉及了維度差異,但視覺依然是一個重要因素。
想像一下,如果人沒有視覺能力,單純依靠聽或其他方式獲得關於其中網格的信息,也很難直接構建出二維的矩陣。
不過說到這,即便模型擁有「視覺」能力,也是將視覺信息轉換為Token,和人類的視覺也未必相同。
網民認為,真正的視覺需要能夠處理並行輸入的信息,而不是逐個Token的串行輸入,二進製IO數據流或許是一種解決方案。
One More Thing
根據ARC挑戰官方的說法,ARC-AGI的下一代ARC-AGI-2即將推出。
早期測試表明,其將對o3構成重大挑戰——
即使在高計算量模式下,o3的得分也可能會降低到30%以下(而聰明人仍然能夠得分超過95%)。



















