獨享MRDIMM有多強?至強6性能核處理器的內存二三事
機器之心發佈
至強 6 性能核處理器在核數、內存帶寬均大幅提升的加持下,推理性能激增,進一步提升了推理的性價比。
至強 6 性能核的核心規模
在之前的文章中,有從業者預測至強 6 性能核處理器每顆計算單元芯片中的內核數量為 43,加上每個計算單元有兩組雙通道內存控製器各佔一個網格,那麼總共佔用 43+2=45 個網格,可以由 5×9 的佈局構成。但這個假設有一個問題,要構成 128 核的 6980P,三顆芯片只屏蔽 1 個內核,這良率要求比較高啊。

至今還未在公開渠道看到至強 6 性能核處理器的 Die shot 或架構圖,但英特爾發佈了晶圓照片作為宣傳素材。雖然晶圓照片並不能提供每顆芯片的清晰信息,但隱約能感覺到,網格構成更像是 5×10,而不是 5×9 或 6×8。另外,左上角和左下角疑似內存控製器的區域面積比預想的要大得多,每一側佔了三個網格。如果接受了兩組內存控製器共佔用 6 個網格的設定,那麼每個芯片中就是 50-6=44 個內核,在構成 6980P 的時候分別屏蔽一到兩個核即可,感覺就合理多了。

在獲得相對可信的內核數量後,新的疑惑就是:為什麼至強 6 性能核的內存控製器這麼佔地 —— 這個區域有其他未知功能?還是因為增加了 MRDIMM (Multiplexed Rank DIMM) 的支持?畢竟在此之前,英特爾的雙通道 DDR5、三通道 DDR4 內存控製器只佔一個網格,甚至,連信號規模更大、帶寬更高的 HBM 控製器(至強 CPU Max 處理器)也是一個網格。至強 CPU Max 處理器的 HBM2e 是工作在 3,200MT/s,那麼每個控製器帶寬是 410GB/s,整顆 CPU 有超過 2TB/s 的 HBM 帶寬。
雖然對疑似內存控製器區域所佔芯片面積的疑惑未解,還需要進一步解惑,但至少可以確定,英特爾在這一代至強的內存控製器上是下了大班錢的。至少在相當一段時間內,它是可以 「獨佔」 MRDIMM 的優勢了。
至強 6 性能核的 NUMA 與集群模式
談服務器的內存就繞不過 NUMA(Non-Uniform Memory Access,非統一內存訪問)。因為隨著 CPU 內核數量的增加,各內核的內存訪問請求衝突會迅速增加。NUMA 是一個有效的解決方案,將內核分為若干組,分別擁有相對獨立的緩存、內存空間。規模縮小後,衝突就會減少。一般來說,NUMA 劃分的原則是讓物理上臨近某內存控製器的內核為一個子集。這個子集被英特爾稱為 SUB-NUMA Clustering,簡稱 SNC。同一 SNC 的內核綁定了末級緩存(LLC)和本地內存,訪問時的時延最小。
譬如,在第三代至強可擴展處理器中,一個 CPU 內可劃分兩個 SNC 域,每個 SNC 對應一組三通道 DDR4 內存控製器。如果關閉 NUMA,那麼整個 CPU 的內存將對稱訪問。

而第四代至強可擴展處理器使用了 4 顆芯粒的封裝,可以被劃分為 2 個或 4 個 SNC 域。如果希望每個內核可以訪問所有的緩存代理和內存,可以將第四代至強可擴展處理器設置為 Hemisphere Mode 或者 Quadrant Mode,預設是後者。第五代至強可擴展處理器是 2 顆芯粒,可以劃分為兩個 SNC 域。


在至強 6 性能核中,可以將每個計算單元芯片作為一個 SNC,每個域擁有 4 個內存通道,這被稱為 SNC3 Mode。如果要通過其他芯粒的緩存代理訪問所有內存,那就是 HEX Mode。

根據英特爾提供的數據,幾種不同模式的內存訪問時延差異較大,與內核、內存控製器之間的 「距離」 直接相關。至強 6 性能核的內核規模、內存控製器數量增加之後,相應的訪問時延也會上升。例如,根據前面的觀察,至強 6 性能核內每個計算單元芯片中,內核與內存控製器的最遠距離為 10 列,而第四代 / 第五代至強可擴展處理器無 NUMA 的為 8 列。這反映在英特爾的數據上,就是至強 6900P 在 SNC3 Mode 的時延略高於上一代至強處理器的 Quad Mode。如果至強 6900P 設為 HEX Mode,那麼內核與內存控製器的最遠距離將達到 13 甚至 15 列,時延增加會比較明顯。
整體而言,由於 SNC3 Mode 時延低,其將成為至強 6 服務器的預設模式。這種模式主要是適合虛擬化 / 容器化這類常見雲應用,以及並行化程度高的計算(如編解碼)等。當然,HEX Mode 可以直接訪問更大規模的內存,這對於大型數據庫,尤其是以 OLTP 為代表的應用來說更為有利。Oracle 和 SQL 通常建議關閉 NUMA 以獲得更佳的性能。Apache Cassandra 5.0 這類引入向量搜索的數據庫也能從 HEX Mode 顯著獲益。部分科學計算也更適合 HEX Mode,譬如通過偏微分方程建模的 PETSs、分子動力學軟件 NAMD 等。
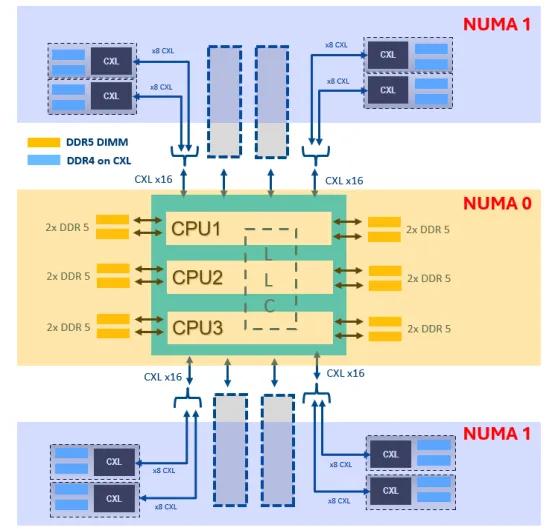
HEX Mode 的另一個典型場景是配合 CXL 內存使用。譬如英特爾在今年 12 月 11 日發佈的一篇利用 CXL 內存優化系統內存帶寬的論文中,使用了至強 6900P 搭配 12 條 64GB DDR5 6400 以及 8 個 128GB CXL 內存模塊,其中至強 6900P 本地的 768GB DDR5 內存在 HEX Mode 下配置為 NUMA0,所有的 1TB CXL 內存配置為 NUMA1,採用優化交錯配置(Interleaving Strategy)。測試表明,在內存帶寬敏感的應用中,使用 CXL 內存擴展可以提升 20%~30% 的性能。
MRDIMM 領跑者
對於至強 6 性能核處理器而言,提升內存帶寬最直接的方法莫過於 MRDIMM。這也是這款處理器相比其他同類產品比較獨佔的一項能力,近期看不到任何其他 CPU 廠商有明確支持 MRDIMM 的時間表,更不要說推出實際產品了。相對而言,內存廠商對 MRDIMM 的支持比較積極,美光、SK 海力士、威剛都推出了相應的產品,包括高尺寸(Tall formfactor,TFF)。第一代 DDR5 MRDIMM 的目標速率為 8,800 MT/s,未來會逐步提升至 12,800 MT/s、17,600 MT/s。
MRDIMM 增加了多路複用數據緩衝器(MDB),改進了寄存時鍾驅動器(MRCD)。MDB 佈置在內存金手指附近,與主機側的 CPU 內存控製器通訊。MDB 主機側的運行速度是 DRAM 側的雙倍,DRAM 側的數據接口是主機側的雙倍。MRCD 可以生成 4 個獨立的芯片選擇信號(標準的 RCD 是兩個,對應兩個 Rank)。MDB 可通過兩個數據接口將兩個 Rank 分別讀入緩衝區,再從緩衝區一次性傳輸到 CPU 的內存控製器,由此實現了帶寬翻倍。

由於 MRCD 可以支持 4 個 Rank,也意味著可以支持雙倍的內存顆粒。已經展示的 MRDIMM 普遍引入更高的板型(TFF),單條容量也由此倍增。由於至強 6900P 插座尺寸大增,導致雙路機型的內存槽數量從上一代的 32 條減少到 24 條。要能夠繼續擴展內存容量,增加內存條的面積(增加高度)確實是最簡單直接的手段。通過使用 256GB 的 MRDIMM,雙路至強 6900P 機型可以獲得 6TB 內存容量。除了更大的內存帶寬,更高的內存容量也非常有利於 AI 訓練、大型數據庫等應用的需求,進一步強化至強 6900P 在 AI 機頭領域的優勢。
與 DDR5 6,400MT/s 相比,MRDIMM 8,800MT/s 的實際運行頻率略低(4,400MT/s),導致輕量級的應用不能從內存帶寬的增加當中明顯獲益。其實類似的問題在內存代際轉換之初均會存在,能夠充分利用更大內存帶寬的主要還是計算密集的應用,譬如加密、科學計算、信號處理、AI 訓練和推理等。從目前的測試看,對 MRDIMM 受益最大的應用主要包括 HPCG(High Performance Conjugate Gradient)、AMG(Algebraic Multi-Grid)、Xcompact3d 這些科學計算類的應用,以及大語言模型推理。
內存帶寬與大模型推理
上一節有提到,並非所有應用都能充分利用 MRDIMM 的內存帶寬收益。就本節重點要談的推理應用而言,根據目前所見的測試數據,卷積神經網絡為代表的傳統推理任務在 MRDIMM 中獲得的收益就比較小,不到 10% 的水平。而在大語言模型推理當中,MRDIMM 的帶寬優勢將得到充分的發揮,性能提升在 30% 以上,因為大模型是確定性的渴求顯存 / 內存容量和帶寬的應用場景。
在這裏就得提一下英特爾至強 6 性能核處理器發佈會資料中的另一個細節:在多種工作負載的性能對比中,AI 部分的提升幅度最為明顯,而且僅用了 96 核的型號(至強 6972P)。

也就是說,至強 6972P 使用了至強 8592 + 的 1.5 倍內核,獲得了至少 2.4 倍的大語言模型推理性能。其中,右側的是 Llama3 8B,int8 精度,那麼模型將佔用約 8GB 的內存空間。以目前雙路 24 通道 MRDIMM 8,800MT/s 約 1,690GB/s 的總內存帶寬而言,可以算出來每秒 token 數理論上限是 211。而雙路 8592 + 是 16 通道 DDR5 5,600MT/s,內存總帶寬為 717GB/s,token 理論上限是接近 90。二者的理論上限正好相差大約 2.4 倍。在這個例子當中,內存帶寬的增長幅度明顯大於 CPU 內核數量的增長。也就是說,在假設算力不是瓶頸的情況下,內存或顯存容量決定了模型的規模上限,而帶寬決定了 token 輸出的上限。
一般來說,在控制模型參數量並進行低精度量化(int8 甚至 int5、int4)之後,大語言模型推理時的算力瓶頸已經不太突出,決定併發數量和 token 響應速度的,主要還是內存的容量和帶寬。通過 MRDIMM,以及 CXL 內存擴展帶寬將是提升推理性能最有效的方式。這也是目前 CPU 推理依舊受到重視的原因,除了可獲得性、資源彈性外,在內存容量及帶寬的擴展上要比 VRAM 便宜的多。
結語
隨著掌握更多的信息,至強 6 性能核處理器在內存帶寬上的優勢和潛力顯得愈發清晰了。MDRIMM 不但能夠大幅提升內存帶寬,還能使可部署的內存容量翻倍,顯著利好傳統的重負荷領域,如科學計算、大型數據庫、商業分析等,對於新興的向量數據庫也大有裨益。CXL 還能夠進一步起到錦上添花的作用。
過去幾年,增長迅猛的大模型推理需求,讓至強可擴展處理器(從第四代開始)利用 GPU 缺貨的契機證明了在 AMX 的加持下,純 CPU 推理也有不錯的性能,而且易於採購和部署。隨著應用深入,部分互聯網企業還挖掘了 CPU 推理的資源彈性,與傳統業務同構的硬件更易於進行峰穀調度。至強 6 性能核處理器在核數、內存帶寬均大幅提升的加持下,推理性能激增,進一步提升了推理的性價比。在解決了 「能或不能」 的問題之後,推理成本是大語言模型落地後最關鍵的挑戰。或許在這方面,至強 6 性能核處理器配 MRDIMM 的組合,將會帶來一些新的解題思路。



















