引入長思維鏈!微信基於阿里千問大模型搞出個翻譯版o1
機器之心報導
編輯:蛋醬、陳陳
最近,類 o1 模型的出現,驗證了長思維鏈 (CoT) 在數學和編碼等推理任務中的有效性。在長思考(long thought)的幫助下,LLM 傾向於探索、反思和自我改進推理過程,以獲得更準確的答案。
在最近的一項研究中,微信 AI 研究團隊提出了 DRT-o1,將長 CoT 的成功引入神經機器翻譯 (MT)。實現這一目標有兩個關鍵點:
-
一是適合在機器翻譯中使用長思考的翻譯場景:並不是所有的場景都需要在翻譯過程中進行長思考。例如,對於簡單的表達,直譯就可以滿足大多數需求,而長思考的翻譯可能沒有必要;
-
二是一種能夠合成具有長思考能力的機器翻譯數據的方法。
展開來說,文學書籍中可能會涉及明喻和隱喻,由於文化差異,將這些文本翻譯成目標語言在實踐中是非常困難的。在這種情況下,直譯往往無法有效地傳達預期的含義。即使是專業的人工翻譯,也必須在整個翻譯過程中仔細考慮如何保留語義。
為了在 MT 中模擬 LLM 的長思考能力,本文首先從現有文學書籍中挖掘包含明喻或隱喻的句子,然後開發出了一個多智能體框架通過長思考來翻譯這些句子。
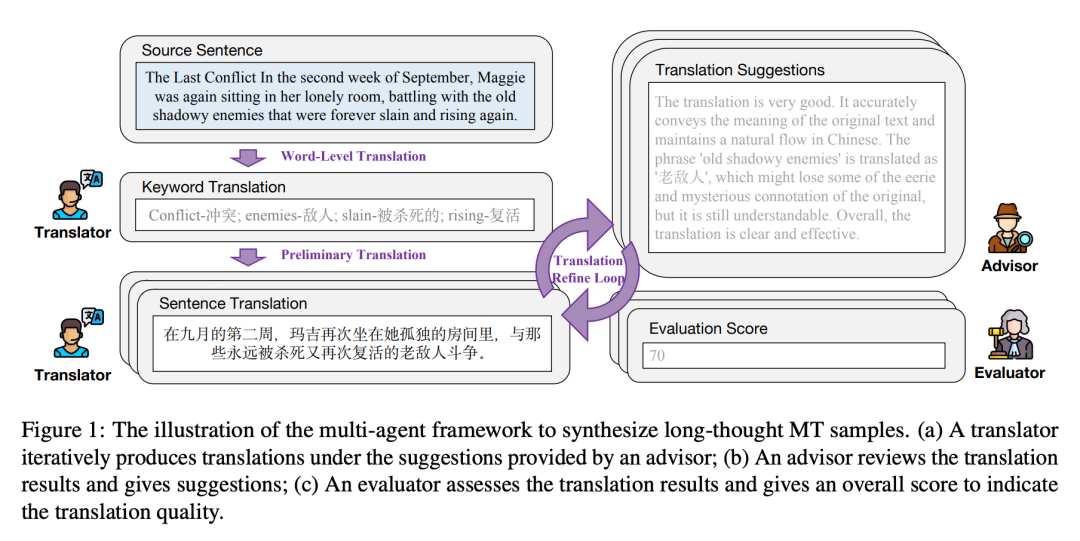
該框架有三個智能體,即翻譯者(translator)、顧問(advisor)和評估者(evaluator)。數據合成過程是迭代的,每次迭代包括以下三個步驟:
(1)翻譯者根據前一步的翻譯和顧問的相應改進建議生成新的翻譯;
(2)顧問評估當前翻譯並提供詳細反饋;
(3)評估者評估當前翻譯並使用預定義的評分標準給出評估分數。一旦評估者提供的翻譯分數達到預定義的閾值或迭代次數達到最大值,迭代將停止。
此後,每一步中的翻譯和建議都可以形成長思考的機器翻譯樣本。為了提高長思考數據的可讀性和流暢性,本文使用 GPT-4o 來重新表述長思考的內容。
基於收集的長思考機器翻譯樣本,本文分別使用 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作為主幹模型,對 DRT-o1-7B 和 DRT-o1-14B 進行訓練(SFT)。在文學翻譯上的實驗結果證明了 DRT-o1 的有效性。例如,DRT-o1-7B 的表現比 Qwen2.5-7B-Instruct 高出 8.26 BLEU、1.31 CometKiwi 和 3.36 CometScore。它的表現也比 QwQ32B-Preview 高出 7.82 BLEU 和 1.46 CometScore。
本文貢獻主要包括:
-
提出 DRT-o1,旨在構建具有長思考機器翻譯能力的 LLM。為了實現這一目標,本文挖掘了帶有明喻或隱喻的文學句子,並收集具有長思考過程的機器翻譯樣本;
-
為了合成長思考機器翻譯樣本,本文提出了一個多智能體框架,其中包括翻譯者、顧問和評估者。這三個智能體以迭代方式協作,在機器翻譯過程中產生長思考。最後,使用 GPT4o 進一步提高合成長思考機器翻譯樣本的質量;
-
在文學翻譯上的實驗結果驗證了 DRT-o1 的有效性,通過長思考,LLM 可以在機器翻譯過程中學會思考。

-
論文標題:DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought
-
論文鏈接:https://arxiv.org/pdf/2412.17498
-
項目地址:https://github.com/krystalan/DRT-o1
DRT-o1 數據
論文以英譯漢為研究對象,在本節中通過三個步驟介紹如何收集 DRT-o1 訓練數據:
(1)收集在翻譯過程中往往需要長時間思考的英語句子(§ 2.1);
(2)通過設計的多智能體框架對收集到的句子進行長時間思考翻譯過程的合成(§ 2.2);
(3)改進長時間思考內容的可讀性和流暢性,形成最終的長時間思考 MT 樣本(§ 2.3)。
最後,對收集到的數據進行統計,加深理解(§ 2.4)。
文學圖書挖掘
研究者利用了古騰堡計劃公共領域書籍庫中的文學書籍,這些書籍通常有 50 多年的歷史,其版權已過期。他們利用了大約 400 本英文書籍來挖掘含有比喻或隱喻的句子。
首先,從這些書籍中提取所有句子,並過濾掉太短或太長的句子,即少於 10 個單詞或多於 100 個單詞的句子,最終得到 577.6K 個文學句子。
其次,對於每個句子,使用 Qwen2.5-72B-Instruct 來判斷該句子是否包含比喻或隱喻,並捨棄不包含比喻或隱喻的句子。
第三,對於剩下的句子,讓 Qwen2.5-72B-Instruct 將其直譯為中文,然後判斷譯文是否符合母語為中文的人的習慣。如果答案是否定的,則保留相應的句子,將其視為「適合長思考翻譯」。
這樣,最終從 577.6K 個涉及比喻或隱喻的文學句子中收集了 63K 個直譯也有缺陷的句子,稱為預收集句子。
多智能體框架
對於每個預先收集的句子(用 s 表示),研究者設計了一個多智能體框架,通過長時間的思考將其從英文翻譯成中文。如圖 1 所示,框架包括三個智能體:翻譯者、顧問和評估者。合成過程如下:
(1) 詞語級翻譯。
(2) 初步翻譯。
(3) 翻譯完善循環。
長思考重配方
經過多智能體協作,得到了一個漫長的思考過程:
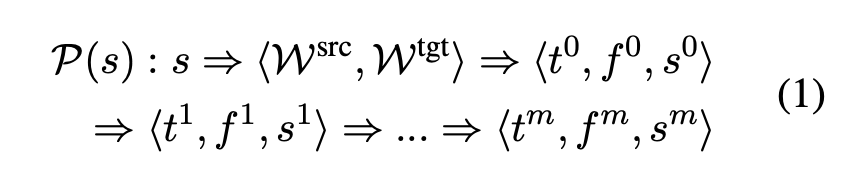
其中,P (s) 表示 s 的多智能體思考過程,m 為迭代步數。為了強調有效的思維過程,沒有分數變化的翻譯將被刪除。也就是說,如果 s^i 等於 s^(i-1)(i = 1,2,…,m),研究者將捨棄 P (s) 中的⟨t^i , f^i , s^i ⟩,結果為:
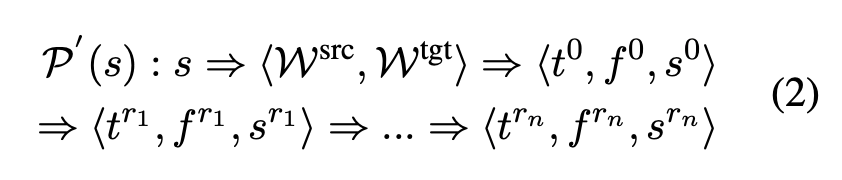
其中 1≤r_1 < r_2 < … < r_n ≤ m,n 為賸餘步數。如果 n < 3,將放棄整個樣本,即 P (s) / P′ (s)。
對於其餘樣本,研究者效仿 Qin et al. (2024) 的做法,利用 GPT-4o 將 P ′ (s) 修改並打磨為自我反思描述。最後,獲得了 22264 個帶有長思考的機器翻譯樣本。圖 2 舉例說明了合成結果。

數據統計
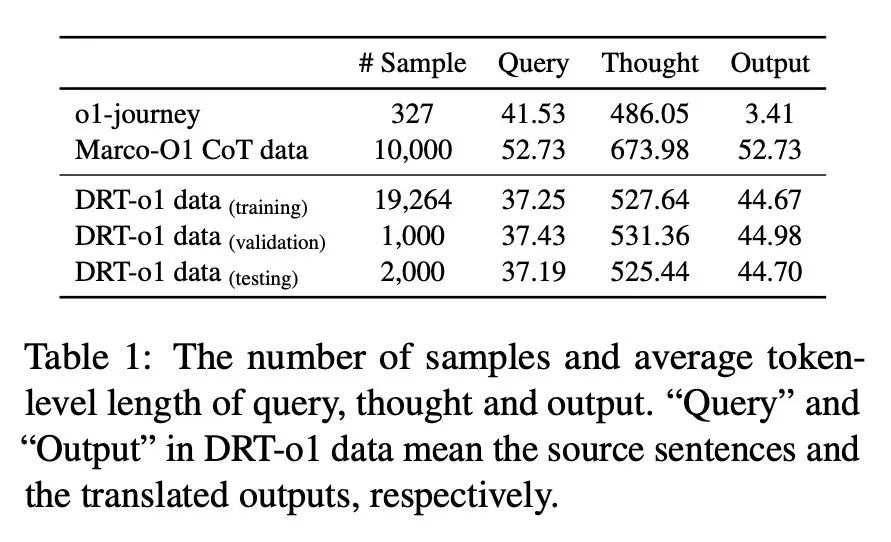
研究者將收集到的 22264 個樣本分為訓練集、驗證集和測試集,樣本數分別為 19264、1000 和 2000。表 1 列出了 DRT-o1 數據和以往類似 O1 數據的數據統計。對於 Marco-O1 CoT 數據,由於其尚未完全發佈,此處使用其演示數據來計算數據統計。可以看到,合成的思考中的平均 token 數達到了 500 多個,這與之前面向數學的 O1 類 CoT 數據相似。
實驗
為了計算 CometKiwi 和 CometScore,研究者使用了官方代碼和官方模型。為了計算 BLEU 分數,使用 sacrebleu 工具包計算語料庫級別的 BLEU。此處,研究者採用 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作為 DRT-o1 的骨幹。
下表 2 顯示了文獻翻譯的結果。研究者將 DRT-o1-7B 和 DRT-o1- 14B 與之前的 Qwen2.5-7B-Instruct、Qwen2.5- 14B-Instruct、QwQ-32B-preview 和 Marco-o1- 7B 進行了比較。根據收集到的數據進行指令調整後,DRT-o1-7B 的 BLEU、CometKiwi 和 CometScore 分別為 8.26、1.31 和 3.36,優於 Qwen2.5-7B-Instruct。DRT-o1-14B 在 7.33 BLEU、0.15 CometKiwi 和 1.66 CometScore 方面優於 Qwen2.5-14B-Instruct。此外,DRT-o1-14B 在所有指標方面都取得了最佳結果,顯示了長思考在機器翻譯中的有效性。

圖 3 顯示了 DRT-o1-14B 的一個示例。可以看到,該模型學習了收集的數據的思維過程。DRT-o1-14B 首先執行詞級翻譯,然後嘗試初步翻譯。接下來,它會不斷改進翻譯,直到它認為翻譯足夠好為止。

更多研究細節,可參考原論文。



















