超越Claude 3.5緊追o1!DeepSeek-V3-Base開源,編程能力暴增近31%
機器之心報導
編輯:杜偉、小舟
在 2024 年底,探索通用人工智能(AGI)本質的 DeepSeek AI 公司開源了最新的混合專家(MoE)語言模型 DeepSeek-V3-Base。不過,目前沒有放出詳細的模型卡。

-
HuggingFace 下載地址:https://huggingface.co/DeepSeek-ai/DeepSeek-V3-Base/tree/main
具體來講,DeepSeek-V3-Base 採用了 685B 參數的 MoE 架構,包含 256 個專家,使用了 sigmoid 路由方式,每次選取前 8 個專家(topk=8)。

圖源:X@arankomatsuzaki
該模型利用了大量專家,但對於任何給定的輸入,只有一小部分專家是活躍的,模型具有很高的稀疏性。

圖源:X@Rohan Paul
從一些網民的反饋來看,API 顯示已經是 DeepSeek-V3 模型。

圖源:X@ruben_kostard
同樣地,聊天(chat)界面也變成了 DeepSeek-v3。
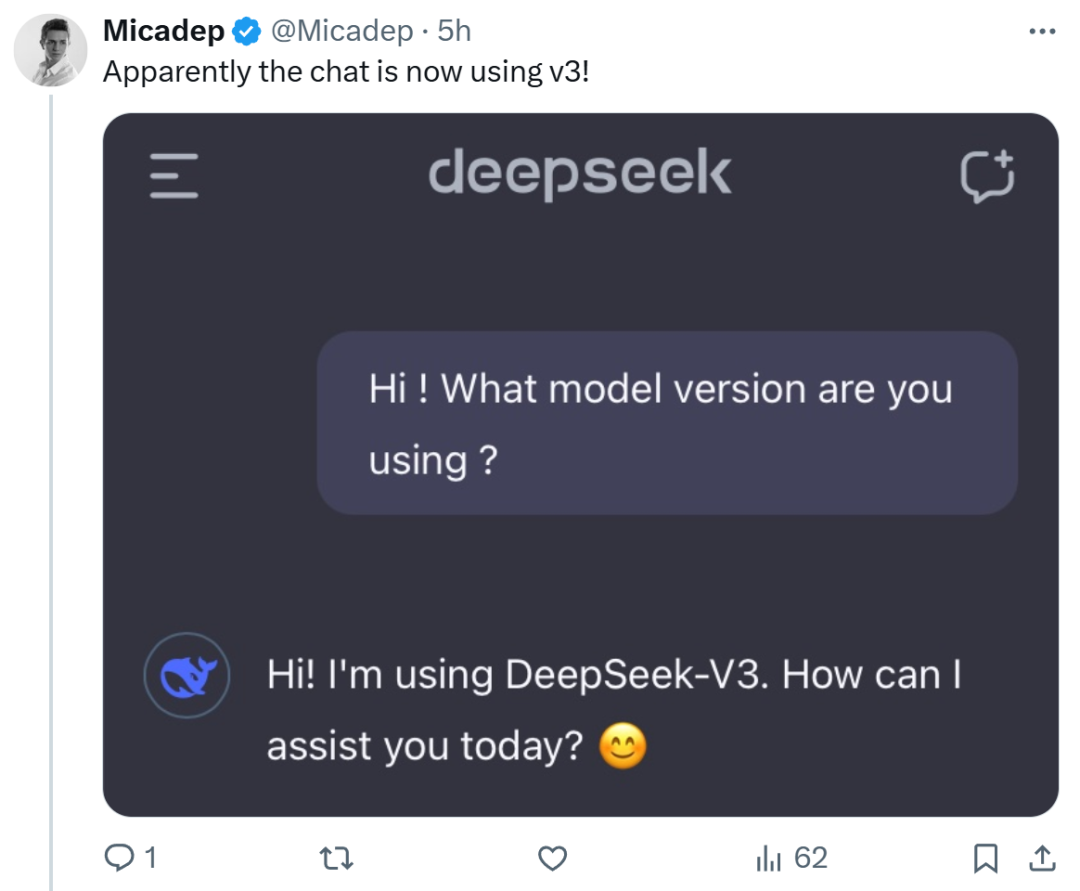
圖源:X@Micadep
那麼,DeepSeek-V3-Base 性能怎麼樣呢?Aider 多語言編程測評結果給了我們答案。
先來瞭解一下 Aider 多語言基準,它要求大語言模型(LLM)編輯源文件來完成 225 道出自 Exercism 的編程題,覆蓋了 C++、Go、Java、JavaScript、Python 和 Rust 等諸多編程語言。這 225 道精心挑選的最難的編程題給 LLM 帶來了很大的編程能力挑戰。
該基準衡量了 LLM 在流行編程語言中的編碼能力,以及是否有能力編寫可以集成到現有代碼的全新代碼。
從下表各模型比較結果來看,DeepSeek-V3-Base 僅次於 OpenAI o1-2024-12-17 (high),一舉超越了 claude-3.5-sonnet-20241022、Gemini-Exp-1206、o1-mini-2024-09-12、gemini-2.0-flash-exp 等競品模型以及前代 DeepSeek Chat V2.5。
其中與 V2.5(17.8%)相比,V3 編程性能暴增到了 48.4%,整整提升了近 31%。


另外,DeepSeek-V3 的 LiveBench 基準測試結果也疑似流出。我們可以看到,該模型的整體、推理、編程、數學、數據分析、語言和 IF 評分都非常具有競爭力,整體性能超越 gemini-2.0-flash-exp 和 Claude 3.5 Sonnet 等模型。

圖源:reddit@homeworkkun
HuggingFace 負責 GPU Poor 數據科學家 Vaibhav (VB) Srivastav 總結了 DeepSeek v3 與 v2 版本的差異:
根據配置文件,v2 與 v3 的關鍵區別包括:
-
vocab_size:v2: 102400 v3: 129280
-
hidden_size:v2: 4096 v3: 7168
-
intermediate_size:v2: 11008 v3: 18432
-
隱藏層數量:v2:30 v3:61
-
注意力頭數量:v2:32 v3:128
-
最大位置嵌入:v2:2048 v3:4096
v3 看起來像是 v2 的放大版本。

圖源:X@reach_vb
值得注意的是,在模型評分函數方面,v3 採用 sigmoid 函數,而 v2 採用的是 softmax 函數。
網民熱評:開源模型逼近 SOTA
眾多紛紛網民表示,Claude 終於迎來了真正強勁的對手,甚至在一定程度上 DeepSeek-V3 可以取代 Claude 3.5。


還有人感歎道,開源模型繼續以驚人的速度追趕 SOTA,沒有放緩的跡象。2025 年將成為 AI 最重要的一年。

參考鏈接:
https://aider.chat/docs/leaderboards/
https://www.reddit.com/r/LocalLLaMA/comments/1hm4959/benchmark_results_deepseek_v3_on_livebench/



















