智譜開源 GLM-PC 基座模型 CogAgent-9B,讓 AI 智能體「看懂」屏幕
IT之家 12 月 27 日消息,智譜技術團隊公眾號昨日(12 月 26 日)發佈博文,宣佈開源 GLM-PC 的基座模型 CogAgent-9B-20241220,基於 GLM-4V-9B 訓練,專用於智能體(Agent)任務。
IT之家註:該模型僅需屏幕截圖作為輸入(無需 HTML 等文本表徵),便能根據用戶指定的任意任務,結合歷史操作,預測下一步的 GUI 操作。
得益於屏幕截圖和 GUI 操作的普適性,CogAgent 可廣泛應用於各類基於 GUI 交互的場景,如個人電腦、手機、車機設備等。

相較於 2023 年 12 月開源的第一版 CogAgent 模型,CogAgent-9B-20241220 在 GUI 感知、推理預測準確性、動作空間完善性、任務普適性和泛化性等方面均實現了顯著提升,並支持中英文雙語的屏幕截圖和語言交互。
CogAgent 的輸入僅包含三部分:用戶的自然語言指令、已執行歷史動作記錄和 GUI 截圖,無需任何文本形式表徵的佈局信息或附加元素標籤(set of marks)信息。
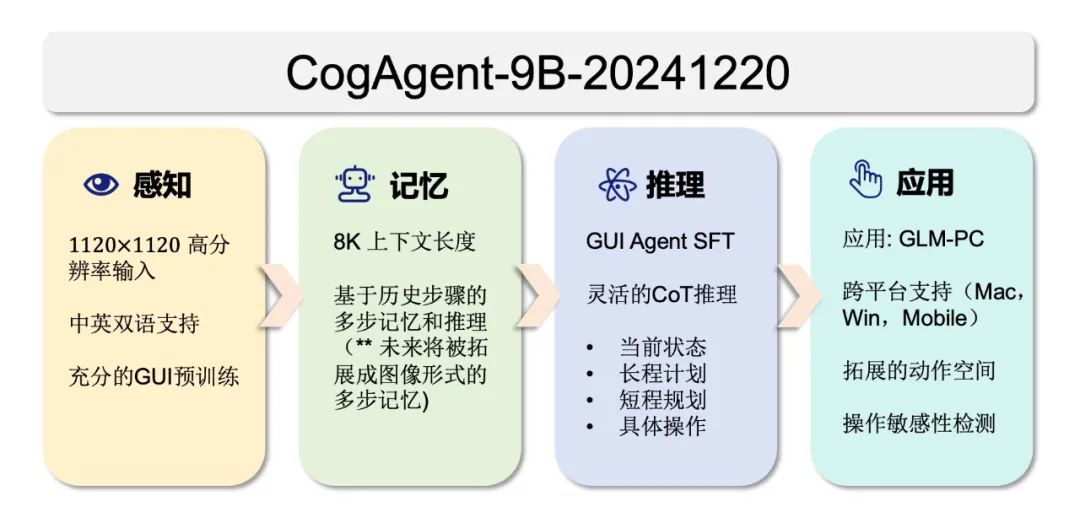
其輸出涵蓋以下四個方面:
-
思考過程(Status & Plan): CogAgent 顯式輸出理解 GUI 截圖和決定下一步操作的思考過程,包括狀態(Status)和計劃(Plan)兩部分,輸出內容可通過參數控制。
-
下一步動作的自然語言描述(Action):自然語言形式的動作描述將被加入歷史操作記錄,便於模型理解已執行的動作步驟。
-
下一步動作的結構化描述(Grounded Operation): CogAgent 以類似函數調用的形式,結構化地描述下一步操作及其參數,便於端側應用解析並執行模型輸出。其動作空間包含 GUI 操作(基礎動作,如左鍵單擊、文本輸入等)和擬人行為(高級動作,如應用啟動、調用語言模型等)兩類。
-
下一步動作的敏感性判斷:動作分為「一般操作」和「敏感操作」兩類,後者指可能帶來難以挽回後果的動作,例如在「發送郵件」任務中點擊「發送」按鈕。
CogAgent-9B-20241220 在 Screenspot、OmniAct、CogAgentBench-basic-cn 和 OSWorld 等數據集上進行了測試,並與 GPT-4o-20240806、Claude-3.5-Sonnet、Qwen2-VL、ShowUI、SeeClick 等模型進行了比較。

結果顯示,CogAgent 在多個數據集上取得了領先的結果,證明了其在 GUI Agent 領域強大的性能。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。