中國MoE一夜爆火!大模型新王暴打GPT-4o,訓練成本僅600萬美元

新智元報導
編輯:桃子 好睏
【新智元導讀】600萬美金訓出擊敗GPT-4o大模型,竟被中國團隊實現了!今天,DeepSeek-V3在全網掀起巨大風暴,僅憑671B參數在數學代碼性能上,堪比國外大模型Claude 3.5 Sonnet。
一夜之間,來自中國的大模型刷屏全網。

DeepSeek-V3,一個擁有671B參數的MoE模型,吞吐量每秒高達60 token,比上一代V2直接飆升3倍。
在多項基準測試中,V3性能直接與Claude 3.5 Sonnet、GPT-4o相匹敵。
在數學代碼方面,DeepSeek-V3完全碾壓GPT-4o。尤其是中文能力,全面領先國外的領先大模型。

就看這閃電般的推理速度,就知道模型有多強了。

值得一提的是,DeepSeek-V3在14.8T高質量token上完成了訓練,模型和論文100%開源。

論文地址:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
新模型驚豔出世,徹底掀翻了整個AI圈。業界多位AI大佬,紛紛對此表示震驚,將重點轉向其訓練成本GPU之上。
論文中,明確提出了DeepSeek-V3僅使用2048塊GPU訓練了2個月,並且只花費了557.6萬美金。

Karpathy驚歎道,「作為參考,要達到這種級別的能力,通常需要約1.6萬個GPU的計算集群。不僅如此,當前業界正在部署的集群規模甚至已經達到了10萬個GPU。
比如,Llama 3 405B消耗了3080萬GPU小時,而看起來更強大的DeepSeek-V3卻只用了280萬GPU小時(計算量減少了約11倍)。
到目前為止,模型在實際應用中的表現相當出色——不僅在LLM競技場名列前茅,而且從Karpathy本人的快速測試來看,結果也都很不錯。
這說明,即便是在資源受限情況下,模型也能展現出令人印象深刻的研究和工程能力。
這是否意味著前沿LLM不需要大型GPU集群?不是的,但這表明,你必須確保不浪費已有的資源,這個案例很好地證明了在數據和算法方面還有很大的優化空間」。

另外,賈揚清針對推理提出了幾點自己的思考:
-
首先最重要的是,我們正式進入了分佈式推理時代。一台單GPU機器(80×8=640G)的顯存已經無法容納所有參數。雖然更新大顯存機器確實可以裝下模型,但不論如何,都需要分佈式推理來保證性能和未來擴展。
-
即使在單個模型中,也需要關注MoE的負載均衡,因為每次推理只有大約5%的參數激活。
-
論文中特別提到引入「redundantexpert」概念,正是為瞭解決這個問題。這已經不再是「一個模型多個副本」的問題、而是「每個模型子模塊都有多個副本」,然後獨立擴縮容。
-
輸入token很容易實現盈利。根據個人專業判斷,需要大量優化才能使輸出token盈利或實現收支平衡。但如果我們相信「軟件摩亞定律」,這就不是問題:每18個月單token成本減半。
-
需要進行分塊(tile)或塊(block)級別的量化。
-
等硬件支持FP4以後,肯定還有不少可以玩的花樣冷知識:FP4乘法實際上就是個16×16的table lookup等等……

中國模型一夜擊敗GPT-4o,100%開源
DeepSeek-V3不俗表現,是在上一代V2進一步升級和迭代。
在基準測試中,數學領域MATH 500上,DeepSeek-V3拿下了90.2高分,比Claude 3.5 Sonnet、GPT-4o超出10分還要多。
同理,在AIME 2024測試中,DeepSeek-V3也取得了領先優勢,飆升近20分。
在代碼Codeforces基準上,新模型以51.6分刷新SOTA,比國外大模型高出30分左右。
在軟件工程SWE-bench Verified基準上,DeepSeek-V3略顯遜色,Claude 3.5 Sonnet以50.8分碾壓所有模型。
另外,在多語言能力(MMLU-Pro)方面,V3提升並不明顯。知識問答基準(GPQA-Diamond)上,V3也是僅次於Claude 3.5 Sonnet。

如下這張圖表,更詳細地展示了DeepSeek-V3在各種基準測試中的結果。

53頁技術報告中,特比強調了V3的訓練成本取得了最大的突破。
團隊特意強調了,新模型的完整訓練僅需要2.788M個GPU小時。即便如此,它在訓練過程中非常穩定,沒有遇到過任何不可恢復的loss突增,也沒有執行任何rollback操作。
DeepSeek-V3訓練成本如下表1所示,這是背後團隊通過優化算法、框架、硬件協同設計最終實現的。
在預訓練階段,模型每訓練1萬億token僅需要180K個GPU小時,即在配備2048個GPU的集群上只需3.7天。
因此,DeepSeek-V3預訓練階段耗時不到2個月就完成了,總共消耗2664K個GPU小時。
另外,再加上上下文長度scaling所需的119K GPU小時和後訓練的5K GPU小時,由此V3完整訓練僅消耗2.788M個GPU小時。
團隊表示,假設GPU的租用價格為2美元/每GPU小時,DeepSeek-V3總訓練成本僅為557.6萬美元。

那麼,究竟是怎樣的技術突破,使得DeepSeek-V3實現了質的飛昇?
訓練細節
正如開頭所述,DeepSeek-V3是一個強大的混合專家模型(MoE),總參數量為為671B,每個token激活37B參數。
它繼續採用了多頭潛在注意力(MLA)來實現高效推理,以及DeepSeekMoE實現低成本訓練。
這兩種架構的優勢,已經在上一代V2中得到了驗證。
除了基本框架之外,研究人員還採用了兩個額外的策略,來進一步增強模型的能力:
-
採用無輔助損失(auxiliary-loss-free)方法來實現負載均衡,目的是最小化負載均衡對V3性能造成的不利影響。
-
採用多token預測訓練目標,結果證明能夠提升V3在評估基準上的整體性能。
 DeepSeek-V3框架
DeepSeek-V3框架為了實現高效訓練,團隊採用了「FP8混合精度訓練」,並對訓練框架進行了全面優化。
通過支持FP8計算和存儲,實現了訓練加速和GPU內存使用的減少。
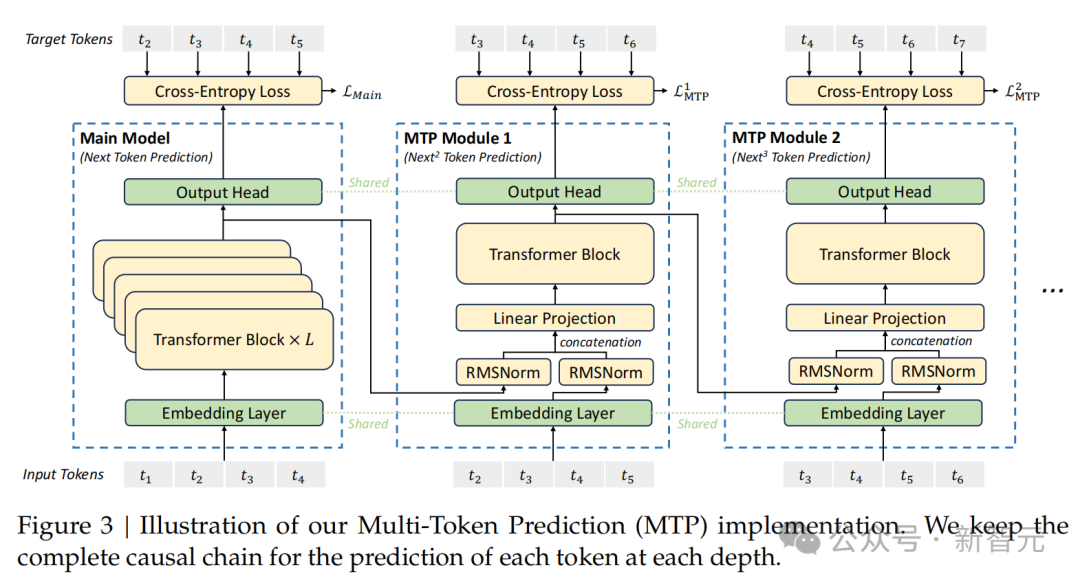
在預訓練階段,DeepSeek-V3在14.8T高質量且多樣化的token完成了訓練,然後又對模型進行了監督微調、強化學習階段。
由此,我們才看了DeepSeek-V3在如上評測中,性能超過了其他開源模型,並達到了與領先閉源模型相當的性能水平。
網民炸鍋了
DeepSeek-V3現在已經在官方平台上直接可以測試,而且代碼全部開源可以直接下載。
國外AI發燒友們紛紛開啟了測試,有人直接將4/8個M4 Mac mini堆疊在一起來運行DeepSeek-V3了…

一位開發者驚訝地表示,DeepSeek-V3無需我解釋就能如此準確地理解一切,這種感覺真讓人毛骨悚然。就好像機器里真的住著一個幽靈似的。

另有開發者通過DeepSeek-V3創建了一個用AI公司logo製作的小行星遊戲,分分鐘就完成了。


還有的人對用如此低成本,訓練出一個強大得模型,難以置信。
Stability AI前CEO表示,以每秒60個token(相當於人類閱讀速度5倍)的速度全天候運行DeepSeek v3,每天僅需要2美元。
那麼,你是要選擇一杯拿鐵咖啡,還是一個AI助手呢?
 參考資料:
參考資料:https://x.com/karpathy/status/1872362712958906460
https://x.com/jiayq/status/1872382450216915186



















