英偉達年終大禮,最強AI GPU曝光!全新B300讓o1/o3推理性能上天算力爆表

新智元報導
編輯:編輯部 HYZ
【新智元導讀】英偉達的聖誕大禮包曝光,最強B300、GB300算力和顯存直接提高50%,模型推理訓練性能史詩級提升,同時還打破了利潤率下降的魔咒。
多虧了老黃,聖誕節如期而至。
儘管Blackwell GPU多次因矽片、封裝和底板問題而推遲發佈,但這並不能阻擋他們前進的腳步。
距離GB200和B200的發佈才剛剛過去幾個月,英偉達便推出了全新一代的AI GPU——GB300和B300。
更為有趣的是,這次看似普通的更新背後,實則內含玄機。其中最為突出的,便是模型的推理和訓練性能得到了大幅增強。
而隨著B300的推出,整個供應鏈正在進行重組和轉型,贏家將從中獲益(獲得禮物),而輸家則處境不妙(收到煤炭)。
 這正是英偉達送給所有超大規模雲計算供應商、特定供應鏈合作夥伴、內存供應商以及投資者的特別「聖誕禮物」
這正是英偉達送給所有超大規模雲計算供應商、特定供應鏈合作夥伴、內存供應商以及投資者的特別「聖誕禮物」不過就在上週,天風國際分析師郭明錤卻在研報中曝出,B300/GB300的DrMOS存在嚴重的過熱問題!
而這,很可能會影響B300/GB300的量產進度。

具體分析如下——
 這已經不是Blackwell第一次被曝出存在設計問題了
這已經不是Blackwell第一次被曝出存在設計問題了B300和GB300:絕不僅是一次小升級
根據SemiAnalysis的最新爆料,B300 GPU對計算芯片的設計進行了優化,並採用了全新的TSMC 4NP工藝節點進行流片。
相比於B200,其性能的提升主要在以下兩個方面:
1. 算力
-
FLOPS性能提升50%
-
功耗增加200W(GB300和B300 HGX的TDP分別達到1.4KW和1.2KW;前代則為1.2KW和1KW)
-
架構改進和系統級增強,例如CPU和GPU之間的動態功率分配(power sloshing)
2. 內存
-
HBM容量增加50%,從192GB提升至288GB
-
堆疊方案從8層HBM3E升級為12層
-
針腳速率保持不變,帶寬仍為8TB/s
專為「推理模型」優化
序列長度的增加,導致KV Cache也隨之擴大,從而限制了關鍵批處理大小和延遲。
因此,顯存的改進對於OpenAI o3這類大模型的訓練和推理至關重要。
下圖展示了英偉達H100和H200在處理1,000個輸入token和19,000個輸出token時的效能提升,這與OpenAI的o1和o3模型中的思維鏈(CoT)模式相似。
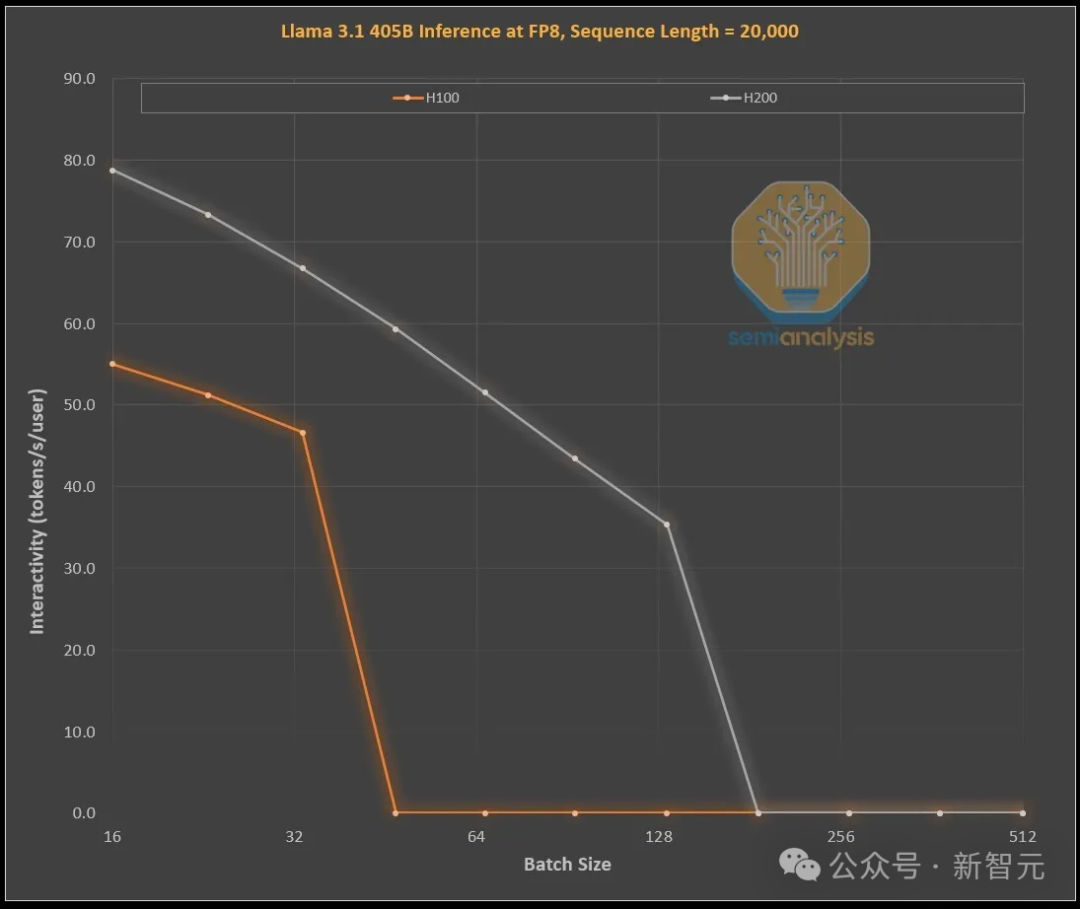 H100和H200的Roofline模擬,通過FP8精度的Llama 405B模型完成
H100和H200的Roofline模擬,通過FP8精度的Llama 405B模型完成H100到H200的升級,主要在於更大、更快的顯存:
更高的帶寬使交互性能普遍提升了43%(H200為4.8TB/s,而H100為3.35TB/s)
更大的批處理規模,使每秒token生成量提升了3倍,進而使成本也降低了約3倍
而對運營商而言,這H100和H200之間的性能與經濟差異,遠遠超過技術參數的數字那麼簡單。
首先,此前的推理模型時常因請求響應時間長而影響體驗,而現在有了更快的推理速度後,用戶的使用意願和付費傾向都將顯著提高。
其次,成本降低3倍的效益,可是極為可觀的。僅通過中期顯存升級,硬件就能實現3倍性能提升,這種突破性進展遠遠超過了摩亞定律、黃氏定律或任何已知的硬件進步速度。
最後,性能最頂尖、具有顯著差異化優勢的模型,能因此獲得更高溢價。
SOTA模型的毛利率已經超過70%,而面臨開源競爭的次級模型利潤率僅有20%以下。推理模型可突破單一思維鏈限制,通過擴展搜索功能提升性能(如o1 Pro和o3),從而使模型更智能地解決問題,提高GPU收益。
當然,英偉達並非唯一能提供大容量顯存的廠商。
ASIC和AMD都具備這樣的能力。而AMD更是憑藉更大的顯存容量(MI300X:192GB、MI325X:256GB、MI350X:288GB)佔據了優勢地位。
不過,老黃手裡還有一張「絕對王牌」——NVLink。
NVL72在推理領域的核心優勢在於,它能讓72個GPU以超低延遲協同工作、共享顯存。
而這也是全球唯一具備全連接交換(all-to-all switched connectivity)和全規約運算(all reduce)能力的加速器系統。
英偉達的GB200 NVL72和GB300 NVL72,對以下這些關鍵能力的實現極其重要——
更高交互性,實現更低思維鏈延遲
72個GPU分散KV Cache,支持更長思維鏈,提升智能水平
相比傳統8 GPU服務器,具備更優批處理擴展性
支持更多樣本並行搜索,提升準確性和模型性能
總體而言,NVL72可以在經濟效益上實現10倍以上提升,尤其是在長推理鏈場景中。
而且,NVL72還是目前唯一能在高批處理下,將推理長度擴展至10萬以上token的解決方案。
供應鏈重構
此前GB200時期,英偉達提供完整的Bianca主板(包含Blackwell GPU、Grace CPU、512GB LPDDR5X內存以及集成在同一PCB上的電壓調節模塊VRM),同時還提供交換機托盤和銅質背板。
但隨著GB300的推出,供應鏈的結構和產品內容,將發生重大調整。
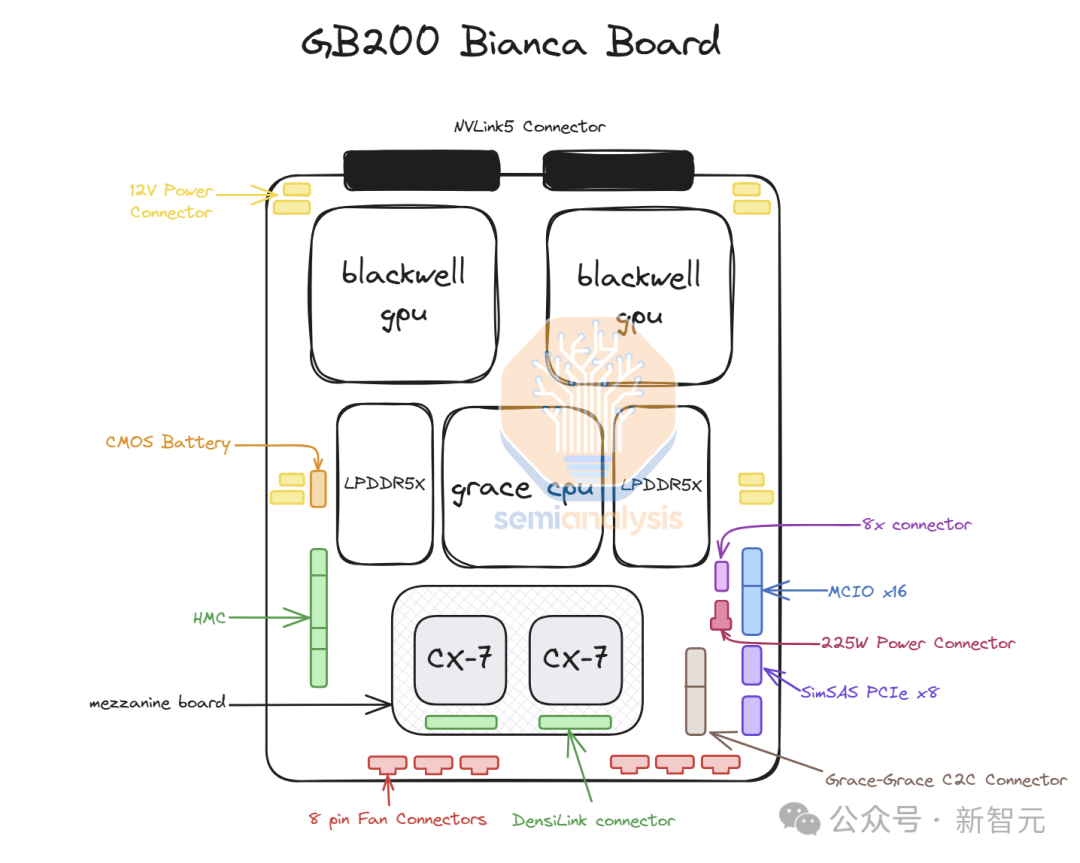
在新方案GB300中行,英偉達只提供三個核心組件的供應:
-
搭載在「SXM Puck」模塊上的B300
-
BGA封裝的Grace CPU
-
由美國初創企業Axiado提供的基板管理控製器(HMC),取代了原有的Aspeed方案
終端客戶將需要直接採購計算板上的其他組件。同時,第二級內存方案,從銲接式LPDDR5X改為可更換的LPCAMM模塊,主要由美光供應。交換機托盤和銅質背板仍由英偉達全權負責。

相比此前僅有緯創和富士康工業互聯網(FII)能夠製造Bianca計算板的局面,SXM Puck方案打破了原有的市場格局。
它的採用為更多OEM和ODM廠商參與計算托盤製造創造了機會:
-
緯創在ODM領域受影響最大,Bianca主板份額顯著下降
-
富士康工業互聯網通過獨家生產SXM Puck及其插座,抵消了Bianca主板業務的損失
-
英偉達正在尋求Puck和插座的其他供應商,但目前尚未確定新訂單
其次,是VRM供應鏈。
儘管SXM Puck上仍保留部分VRM組件,但主要的板載VRM將由超大規模數據中心運營商和OEM直接從供應商採購:
-
Monolithic Power Systems的市場份額將因商業模式轉變而下降
-
市場格局重塑為新供應商創造了更多的機會
第三,英偉達在互聯技術也取得了突破。
GB300平台搭載了800G ConnectX-8網絡接口卡,可在InfiniBand和以太網上提供雙倍的擴展帶寬。
相較於上一代ConnectX-7,ConnectX-8具有多項顯著優勢:
-
帶寬提升100%
-
PCIe通道數從32增至48,支持空冷MGX B300A等創新性架構設計
-
原生支持SpectrumX,無需借助效率較低的Bluefield 3 DPU(此前400G產品的方案)
對超算中心的影響
在2024年第三季度,受GB200和GB300發佈延遲影響,大量訂單轉向了英偉達價格更高的新一代GPU。
截至上週,所有超算中心均已決定採用GB300方案。這一決策基於兩個因素:
-
GB300提供更高的FLOPS算力和更大的顯存容量
-
客戶擁有更多系統定製自主權
此前,由於上市時間壓力以及機架、散熱和供電密度的重大調整,超算中心此前難以對GB200服務器進行深度定製。
這迫使Meta完全放棄了同時向博通和英偉達採購網絡接口卡的計劃,轉而完全依賴英偉達。類似地,Google也放棄了自研網絡接口卡方案,轉而採用英偉達的解決方案。
對於那些一向精於優化從處理器到網絡設備,甚至到螺絲和鈑金等各個環節成本的超算中心數千人研發團隊來說,為其帶去了極大的困擾。
另外,亞馬遜的案例最具代表性。他們選擇了一個次優配置,導致總擁有成本(TCO)超過了參考設計。
由於使用PCIe交換機和需要風冷的低效200G彈性網絡適配器,亞馬遜無法像Meta、Google、微軟、甲骨文、xAI和Coreweave那樣部署NVL72機架。
受限於其內部網卡方案,亞馬遜被迫採用NVL36架構,卻因更高的背板和交換機成本推高了每個GPU的支出。
總體而言,因定製化受限,導致亞馬遜的配置方案並不理想。
GB300的推出,為超算中提供了更大自主權,比如可以自主定製主板、散熱系統等。
這使得亞馬遜能夠開發自己的定製主板,將此前需要風冷的組件(如Astera Labs PCIe交換機)整合進水冷系統。
隨著更多組件採用水冷設計,加上K2V6 400G網卡將在2025年第三季度實現規模化量產,亞馬遜有望重返NVL72架構,顯著提升TCO效率。
然而這也帶來了一個顯著挑戰:超算中心需要投入更多資源進行設計、驗證和確認工作。
這無疑是超算中心面臨的最複雜系統設計項目(除GoogleTPU外)。部分超算中心能夠快速完成設計,但設計團隊較慢的機構則明顯落後。
儘管市場傳聞有公司取消訂單,但SemiAnalysis觀察到由於設計進度較慢,微軟可能是最晚部署GB300的機構之一,他們在第四季度仍在採購GB200。
隨著部分組件從英偉達轉移到原始設計製造商(ODM),客戶的總採購成本出現較大差異。
這不僅影響了ODM的收入,更重要的是導致英偉達全年的毛利率產生波動。下面將更詳細分析這些變動對英偉達利潤產生的影響。
值得一提的是,三星在未來至少9個月內,都無法進入GB200或GB300的供應鏈。
對英偉達利潤的影響
懷著「聖誕精神」的英偉達,在新的定價策略上也頗有看點——這將直接影響Blackwell系列的利潤。
隨著顯存方案從SK海力士和美光的8層HBM3E堆棧升級至12層HBM3E堆棧,顯存容量獲得了顯著提升。
這一升級,直接導致英偉達芯片級物料清單(BOM)成本增加約2,500美元。
成本的增加主要來自——
-
更高的容量
-
堆棧層數增加帶來的每GB顯存溢價
-
封裝良率下降帶來的額外成本
第三點也反映出高帶寬顯存(HBM)在物料成本中的主導地位(隨著推理模型對顯存容量和帶寬需求增加,這一趨勢將持續加強)。
總體而言,GB300的平均售價較GB200提高約4,000美元,其中HBM成本增加約2,500美元,而增量利潤率不足40%,而GB200整體的利潤率維持在70%的中低水平。
然而,由於前述內容變化,英偉達減少了整體供應內容,轉由超算中心自行採購,由此,英偉達實現了成本平衡。
首先,英偉達不再提供每個Grace CPU配套的512GB LPDDR5X內存,這抵消了大部分額外的HBM成本支出。
其次,PCB的成本節省最為顯著。
綜合各項因素,在平均銷售價格提升4,000美元的同時,英偉達的物料成本僅增加略超1,000美元。
GB300相對於GB200的增量毛利率達到73%,這意味著在良率保持穩定的情況下,該產品的利潤水平基本持平。
這一結果雖然看似平常,但值得注意的是,HBM升級週期通常會導致利潤率下降(例如H200、MI325X的情況),而這次這一慣例被打破了。
此外,隨著各項工程技術問題的逐步解決,良率將會提升,在度過Blackwell初期的產能爬升期後,利潤率預計會在年內逐步改善。
 參考資料:
參考資料:Nvidia’s Christmas Present: GB300 & B300 – Reasoning Inference, Amazon, Memory, Supply Chain



















