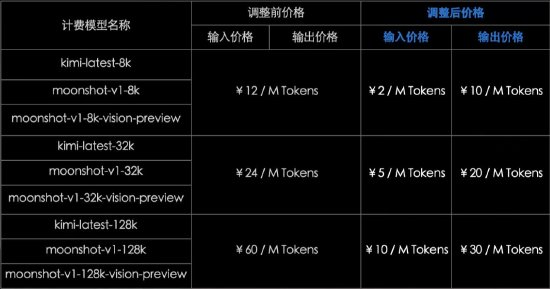
Google DeepMind 優化 AI 模型新思路,計算效率與推理能力兼得
IT之家 12 月 28 日消息,Google DeepMind 團隊最新推出了「可微緩存增強」(Differentiable Cache Augmentation)的新方法,在不明顯額外增加計算負擔的情況下,可以顯著提升大語言模型的推理性能。
項目背景
IT之家註:在語言處理、數學和推理領域,大型語言模型(LLMs)是解決複雜問題不可或缺的一部分。
計算技術的增強側重於使 LLMs 能夠更有效地處理數據,生成更準確且與上下文相關的響應,隨著這些模型變得複雜,研究人員努力開發在固定計算預算內運行而不犧牲性能的方法。
優化 LLMs 的一大挑戰是它們無法有效地跨多個任務進行推理或執行超出預訓練架構的計算。
當前提高模型性能的方法涉及在任務處理期間生成中間步驟,但代價是增加延遲和計算效率低下。這種限制阻礙了他們執行複雜推理任務的能力,特別是那些需要更長的依賴關係或更高地預測準確性的任務。
項目介紹
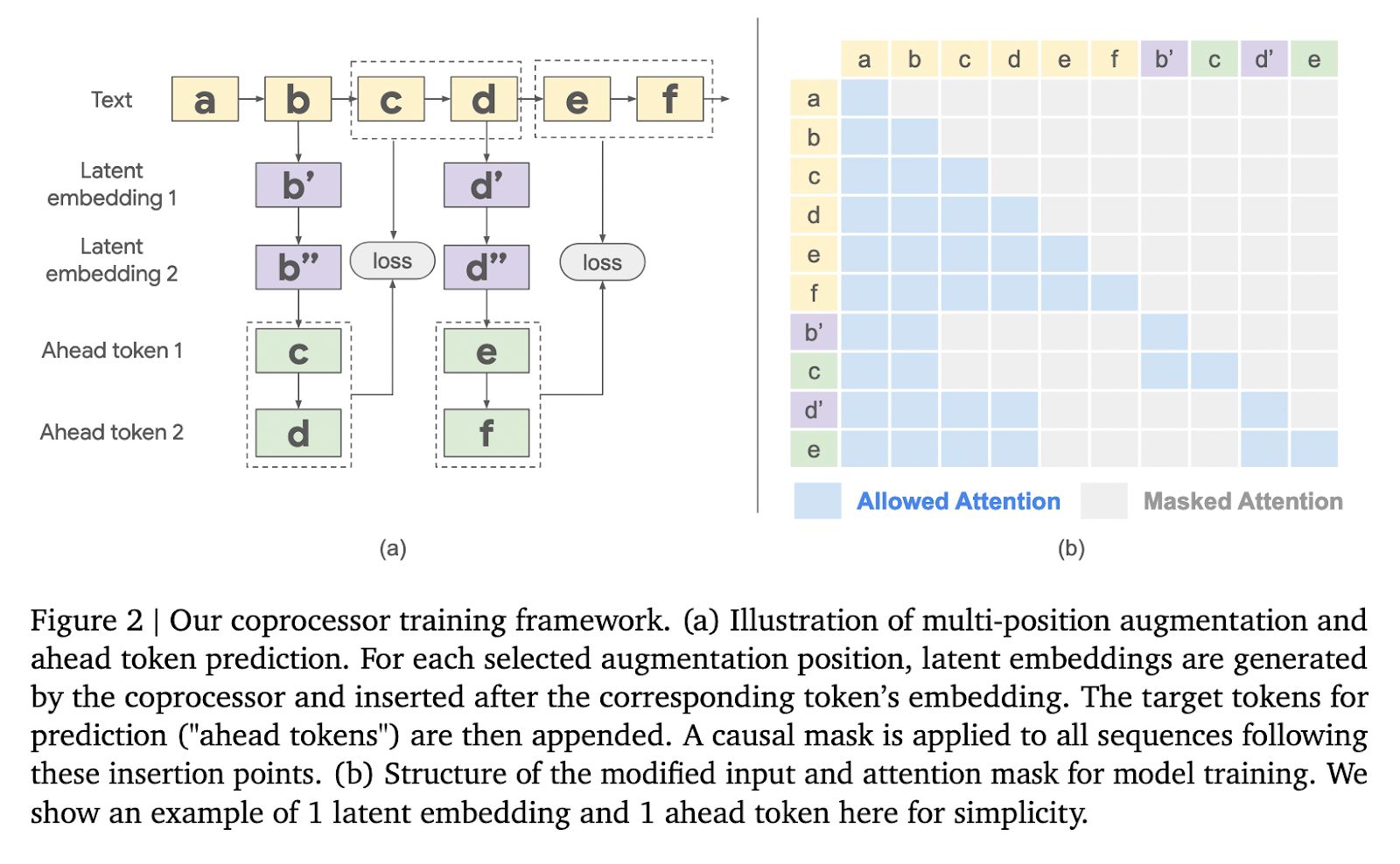
「可微緩存增強」(Differentiable Cache Augmentation)採用一個經過訓練的協處理器,通過潛在嵌入來增強 LLM 的鍵值(kv)緩存,豐富模型的內部記憶,關鍵在於保持基礎 LLM 凍結,同時訓練異步運行的協處理器。
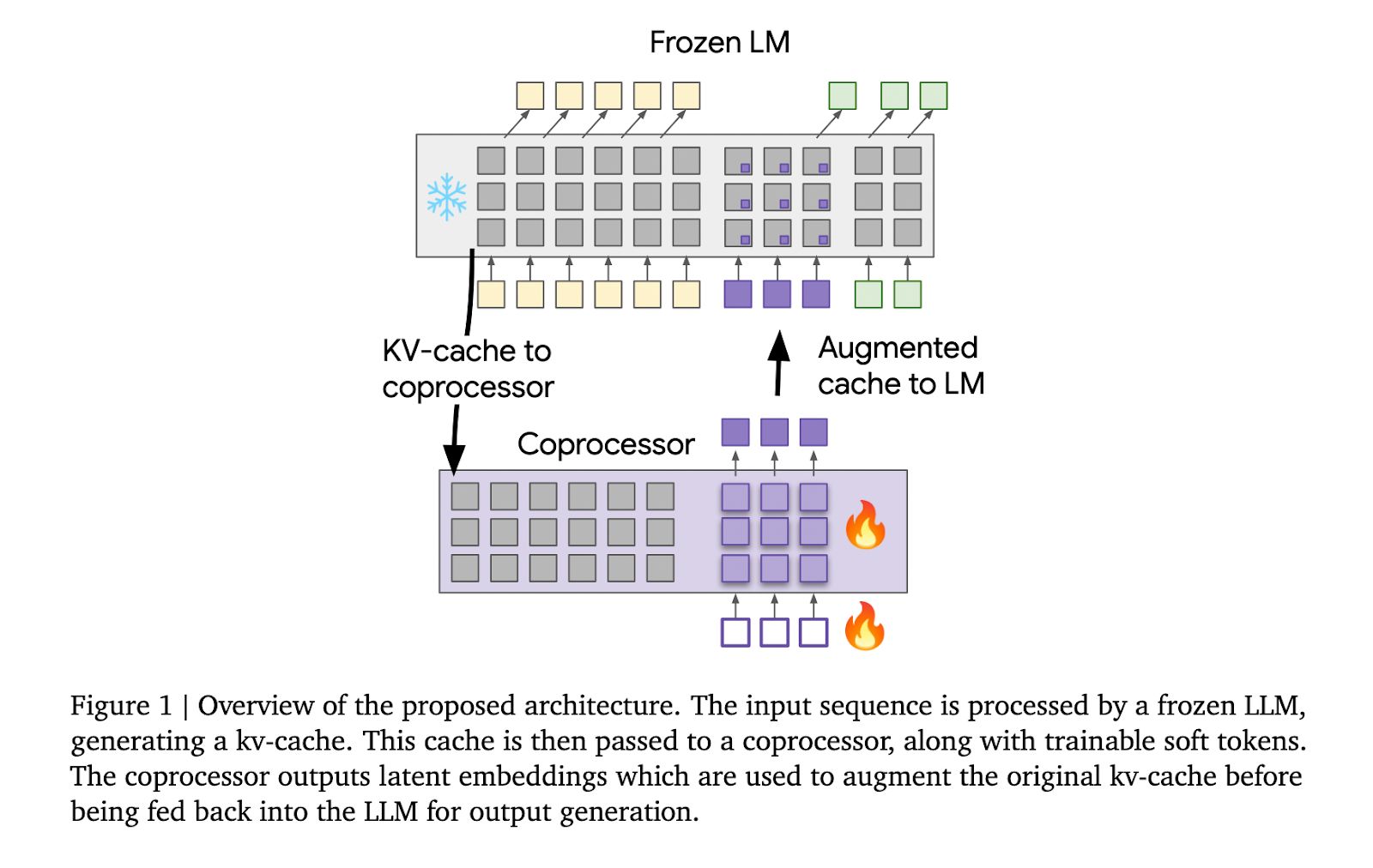
整個流程分為 3 個階段,凍結的 LLM 從輸入序列生成 kv 緩存;協處理器使用可訓練軟令牌處理 kv 緩存,生成潛在嵌入;增強的 kv 緩存反饋到 LLM,生成更豐富的輸出。
在 Gemma-2 2B 模型上進行測試,該方法在多個基準測試中取得了顯著成果。例如,在 GSM8K 數據集上,準確率提高了 10.05%;在 MMLU 上,性能提升了 4.70%。此外,該方法還降低了模型在多個標記位置的困惑度。
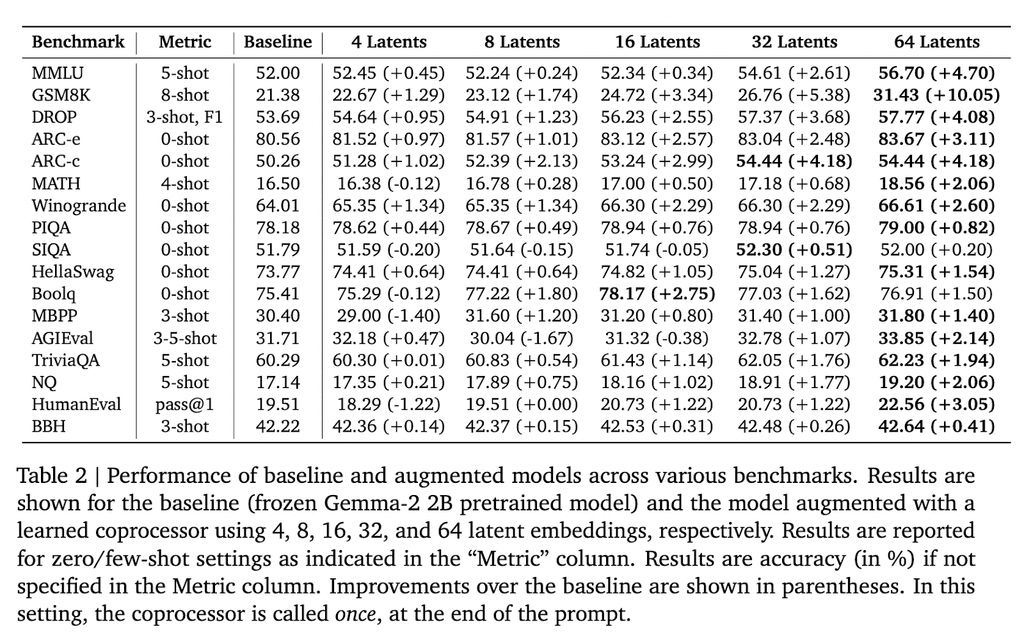
Google DeepMind 的這項研究為增強 LLMs 的推理能力提供了新的思路。通過引入外部協處理器增強 kv 緩存,研究人員在保持計算效率的同時顯著提高了模型性能,為 LLMs 處理更複雜的任務鋪平了道路。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。