一道題燒幾千美元,OpenAI新模型o3:這34道題我真不會
機器之心報導
編輯:佳琪、蛋醬
翻車,但微翻,翻了 12.5% 吧。
前幾天,OpenAI 已經完成了 12 連更的最後一更 —— 如外界所料,是新的推理系列模型 o3 和 o3-mini 。
從 o1 開始,OpenAI 所指出的推理 Scaling Law 似乎帶來了全新的實現 AGI 的希望。此次被用來驗證 o3 推理能力的基準是 ARC-AGI,這項基準已經提出了 5 年時間,但一直未被攻克。
而新模型 o3 是首個突破 ARC-AGI 基準的 AI 模型:最低性能可達 75.7%,如果讓其使用更多計算資源思考更長時間,甚至可以達到 87.5% 的水平。
對於 o1 來說,此前在這項基準中能達到的準確率僅在 25% 到 32% 之間。

在 ARC-AGI 基準中,AI 需要根據配對的「輸入 – 輸出」示例尋找規律,然後再基於一個輸入預測輸出。ARC-AGI 發起者、Keras 之父 François Chollet 在測試報告中表示,雖然成本高昂,但仍然表明新任務的性能確實隨著計算量的增加而提高。o3 在低計算量模式下每個任務需要 17-20 美元,高計算量模式下每個任務數千美元。但這些數字不僅僅是將暴力計算應用於基準測試的結果。OpenAI 的新 o3 模型代表了人工智能適應新任務的能力的重大飛躍。
「這不僅僅是漸進式的改進,而是真正的突破,標誌著與 LLM 之前的局限性相比,人工智能能力發生了質的轉變。o3 能夠適應以前從未遇到過的任務,可以說在 ARC-AGI 領域接近人類水平的表現。」
比如,對於同一道題,Llama 系列的模型就會因為參數量的提高,從而推測出更加準確的答案。

但大家也注意到了,在 ARC-AGI 的 400 個任務中,還有 34 個任務是 o3 無法解決的,即使思考了 16 小時也沒能給出正確答案。正如 François Chollet 所說:「事實上,我認為 o3 還不是 AGI。o3 在一些非常簡單的任務上仍然失敗,這表明其與人類智能存在根本差異。」
這些任務是什麼,難點又在哪裡,接下來讓我們一起看看。
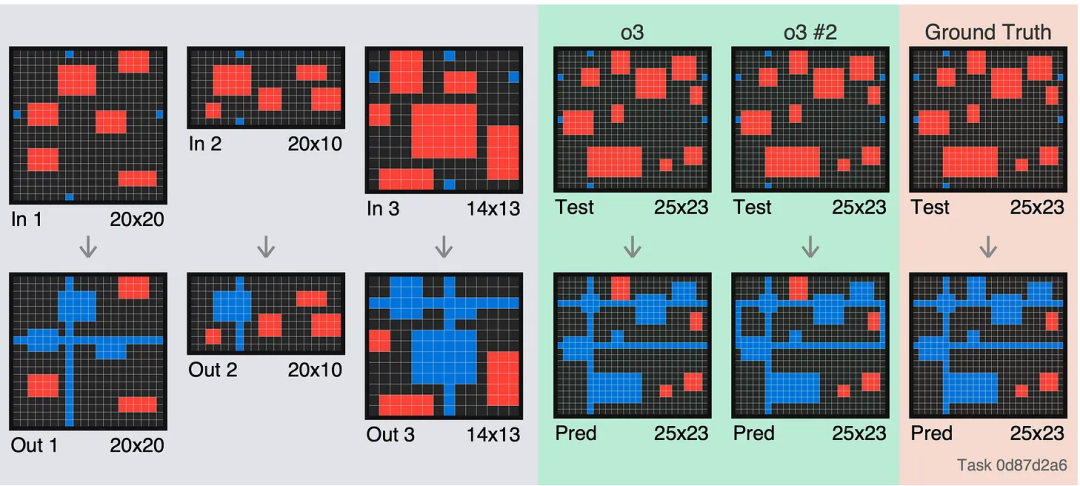
人們驚訝於 o3 無法解決它(沒有看到嘗試)。實際上,這些樣本可能沒有詳細說明,並且 o3 的第一個解決方案是正確的。
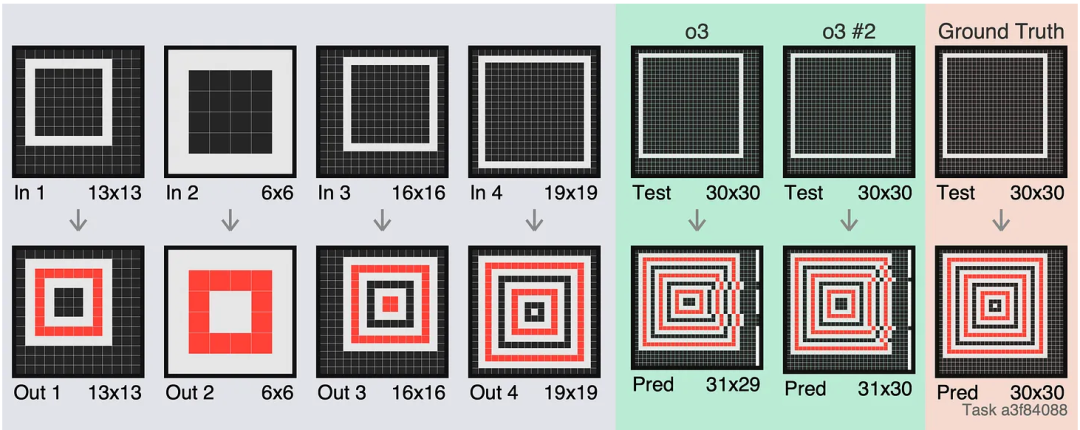
這個任務是整個數據集中唯一一個模型無法輸出網格的樣本 —— 在某些列上添加了錯誤的額外方塊。在 ARC 上,使用較小的 LLM 時經常會看到這種情況。

這個題目看似簡單,其實很有挑戰性。
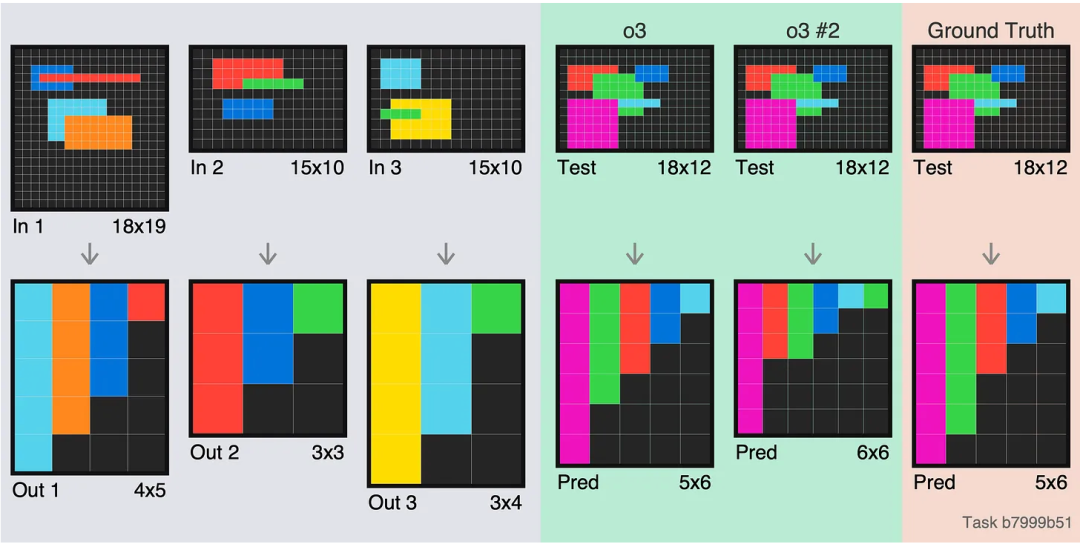

o3 的第一次嘗試就是完全照搬了輸入,什麼都沒改,相當於在答題卡上照抄了一遍題干。
這也能理解,對於一個只能一維思考的模型來說,識別二維物體確實很難。François Chollet 表示,之前就發現過一維推理的局限性,有意思的是,如果在第二次嘗試時給大語言模型看旋轉或翻轉後的題目,它們的表現會明顯提升。



這道題主要考驗空間思維能力,不像其他題目那樣需要對網格做複雜的改動,不過也不影響最後做錯的結果……

這次算是一個不錯的嘗試 —— 雖然還是出了點問題。有意思的是,在輸出第二個答案時,o3 雖然做了一堆推理,最後卻只是簡單畫了幾條重覆的線(這明顯不對)。說實話,感覺它就像是「算了算了,我不玩了!」

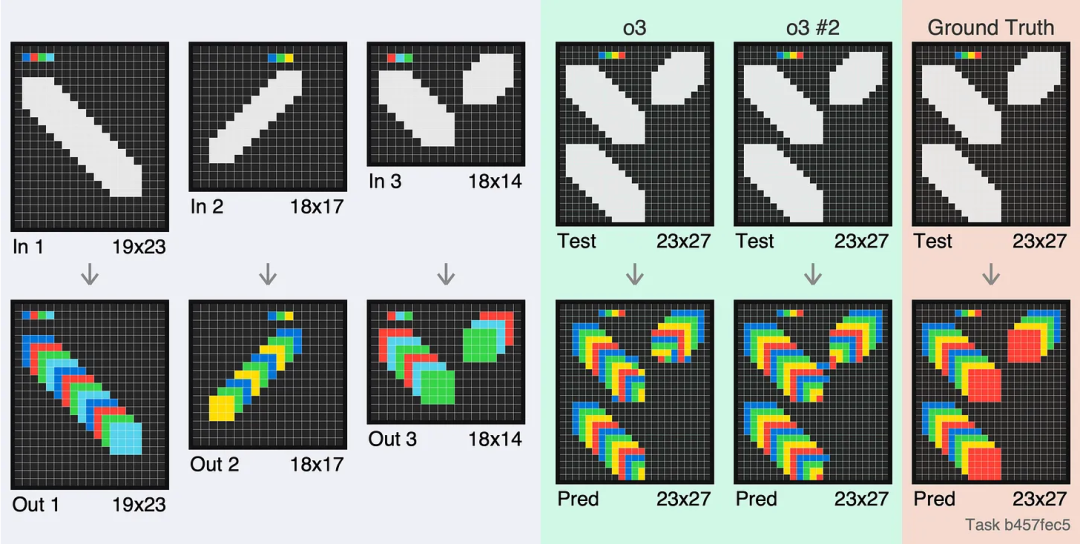
 測試樣本比訓練樣本大得多,這一點很有意思。
測試樣本比訓練樣本大得多,這一點很有意思。 可以看到,和標準答案相比,o3 的結果不僅一點邊都沒沾上,第二次還直接「擺爛了」,交了白卷。
可以看到,和標準答案相比,o3 的結果不僅一點邊都沒沾上,第二次還直接「擺爛了」,交了白卷。François Chollet 指出:「這恐怕是最不理想的一次測試案例。模型的表現難以解釋,o3 似乎在這裏直接放棄了嘗試。不過還不確定這是否是因為第一次模型已經意識到自己的錯誤,從而觸發了 OpenAI 預設的某種機制。」




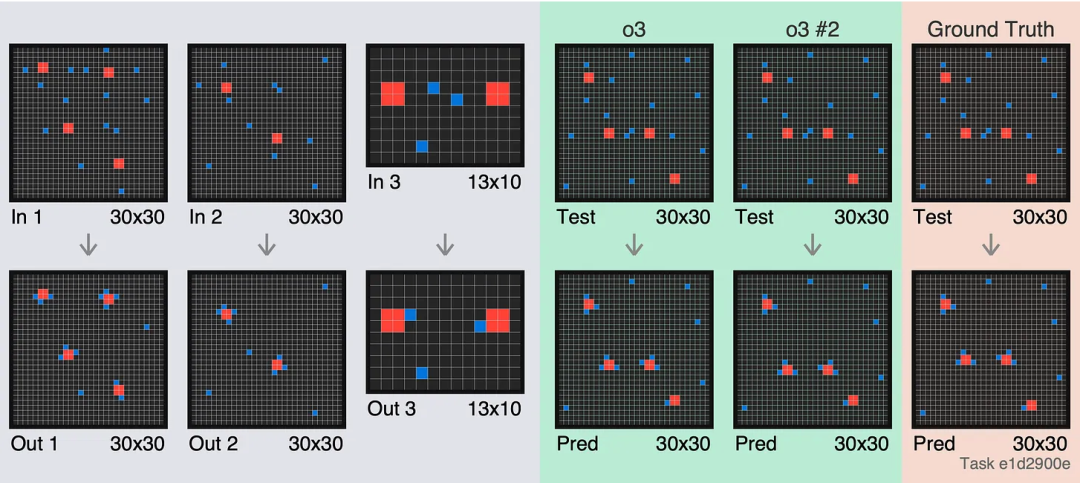
每一行都是正確的,但在整個網格上卻錯位了。

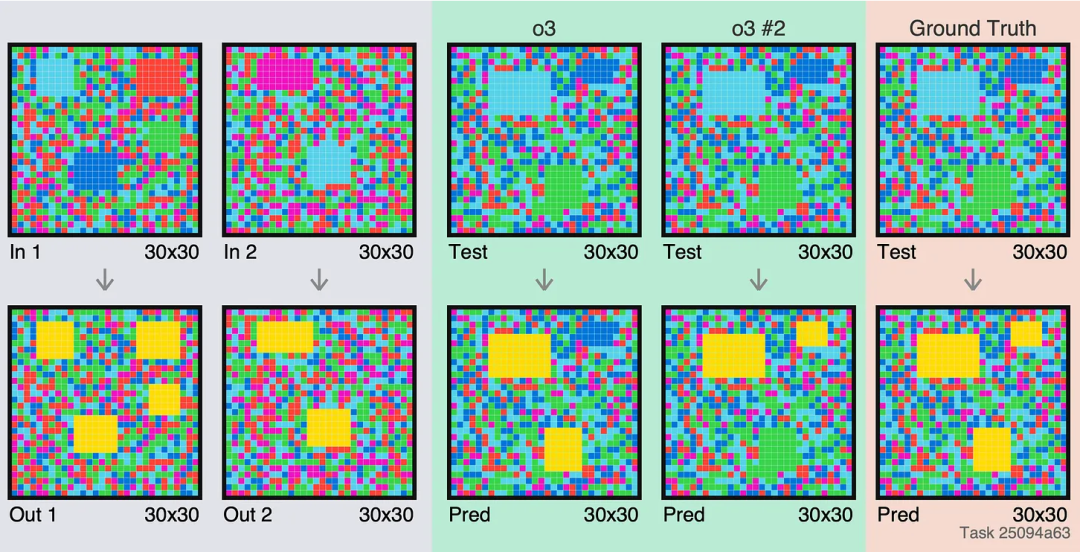


o3 在兩個答案中都漏了一些行、列。
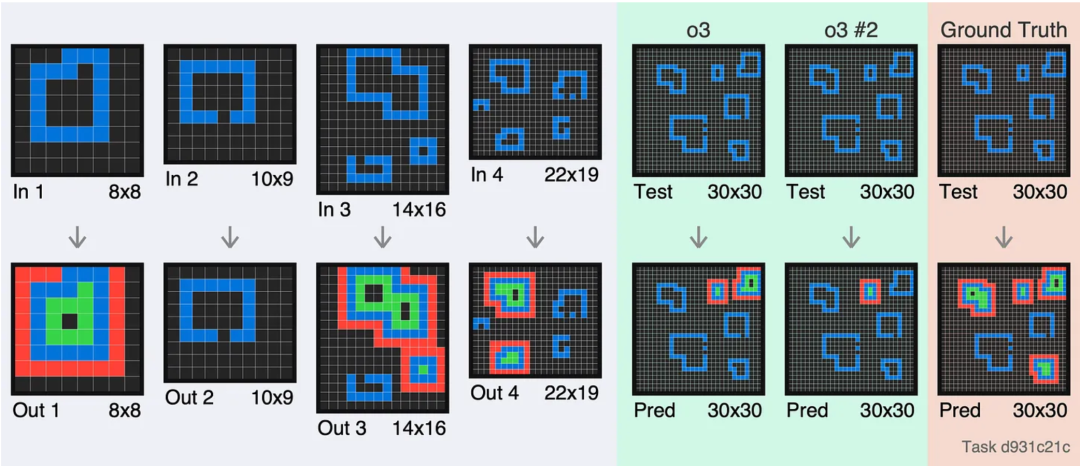





o3 對俄羅斯方塊類型的題完全沒招,我們可以在前面的任務 [1acc24af] 中看到同樣的情況。





這兩次,o3 都在答案中少生成了一行。看來,它很難記住還有多少相同重覆的行要輸出。
 參考鏈接:https://x.com/mikb0b/status/1870622741029941545
參考鏈接:https://x.com/mikb0b/status/1870622741029941545https://anokas.substack.com/p/o3-and-arc-agi-the-unsolved-tasks