DeepSeek-V3 是怎麼訓練的|深度拆解
這兩天,DeepSeek-V3 低調發佈,在國際上狠狠秀了一波肌肉:只用了 500 多萬美金的成本,帶來了不輸 Claude 3.5 的成績,並開源!
下面,讓我們以更加系統的方式,來看看這次的 DeepSeek-V3,是這麼煉成的。本文將從性能、架構、工程、預訓練和後訓練五個緯度來拆解 V3,所用到的圖表、數據源於技術報告:《DeepSeek-V3 Technical Report》。
性能
DeepSeek-V3 的性能優勢,在各項基準測試中得到了充分驗證。
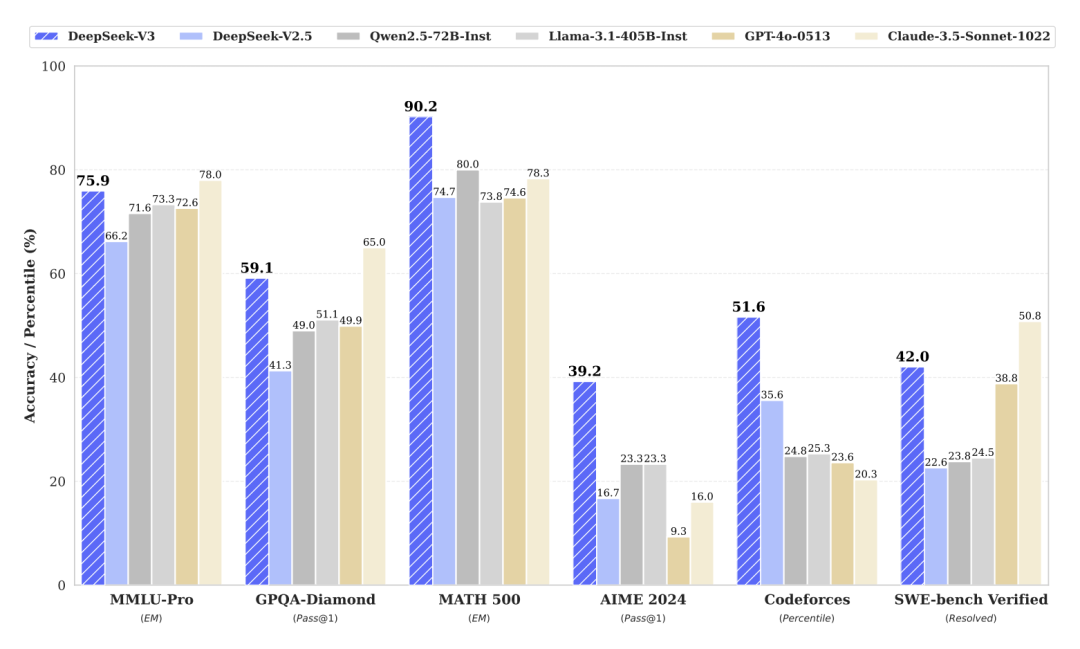
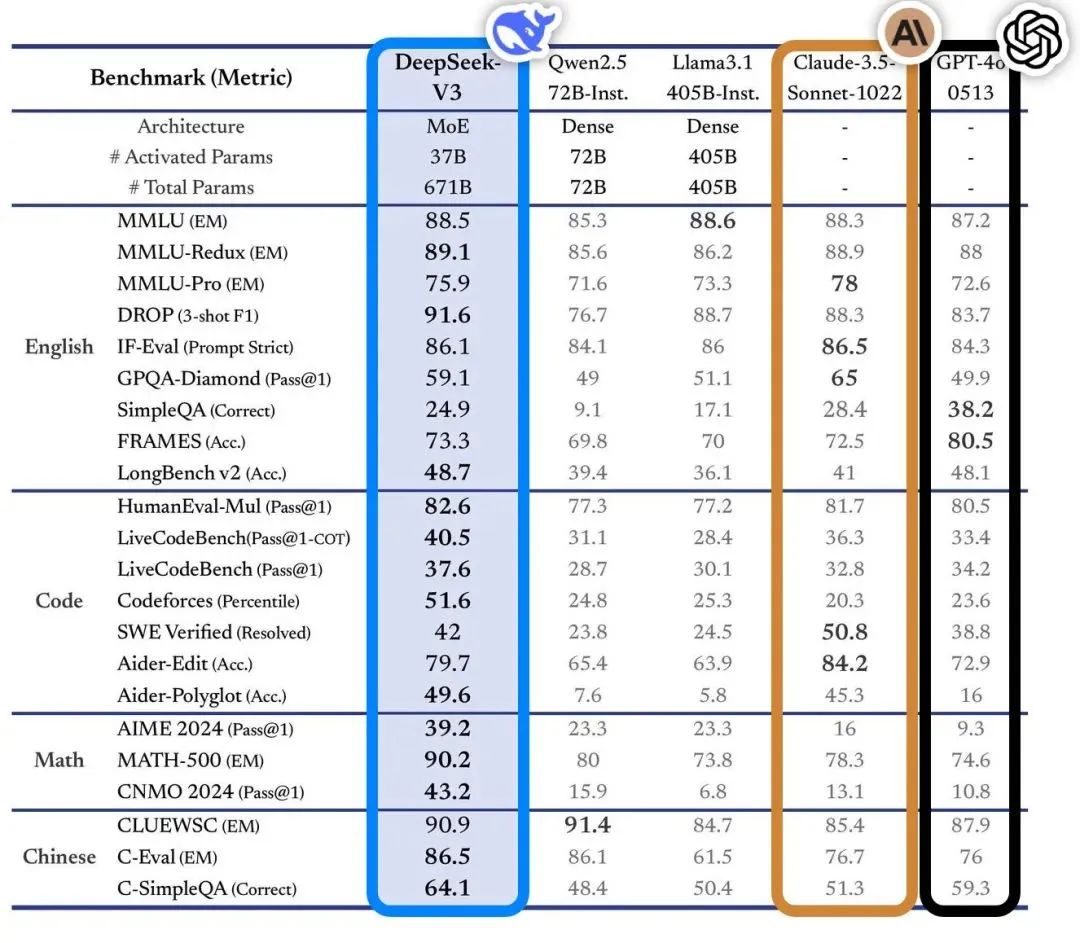
如圖,DeepSeek-V3 在 MMLU-Pro、GPQA-Diamond、MATH 500、AIME 2024、Codeforces (Percentile) 和 SWE-bench Verified 等涵蓋知識理解、邏輯推理、數學能力、代碼生成以及軟件工程能力等多個維度的權威測試集上,均展現出了領先或極具競爭力的性能。特別是在 MATH 500 和 AIME 2024 這類考察高級數學推理能力的測試中,DeepSeek-V3 的表現尤為突出,大幅超越其他模型。
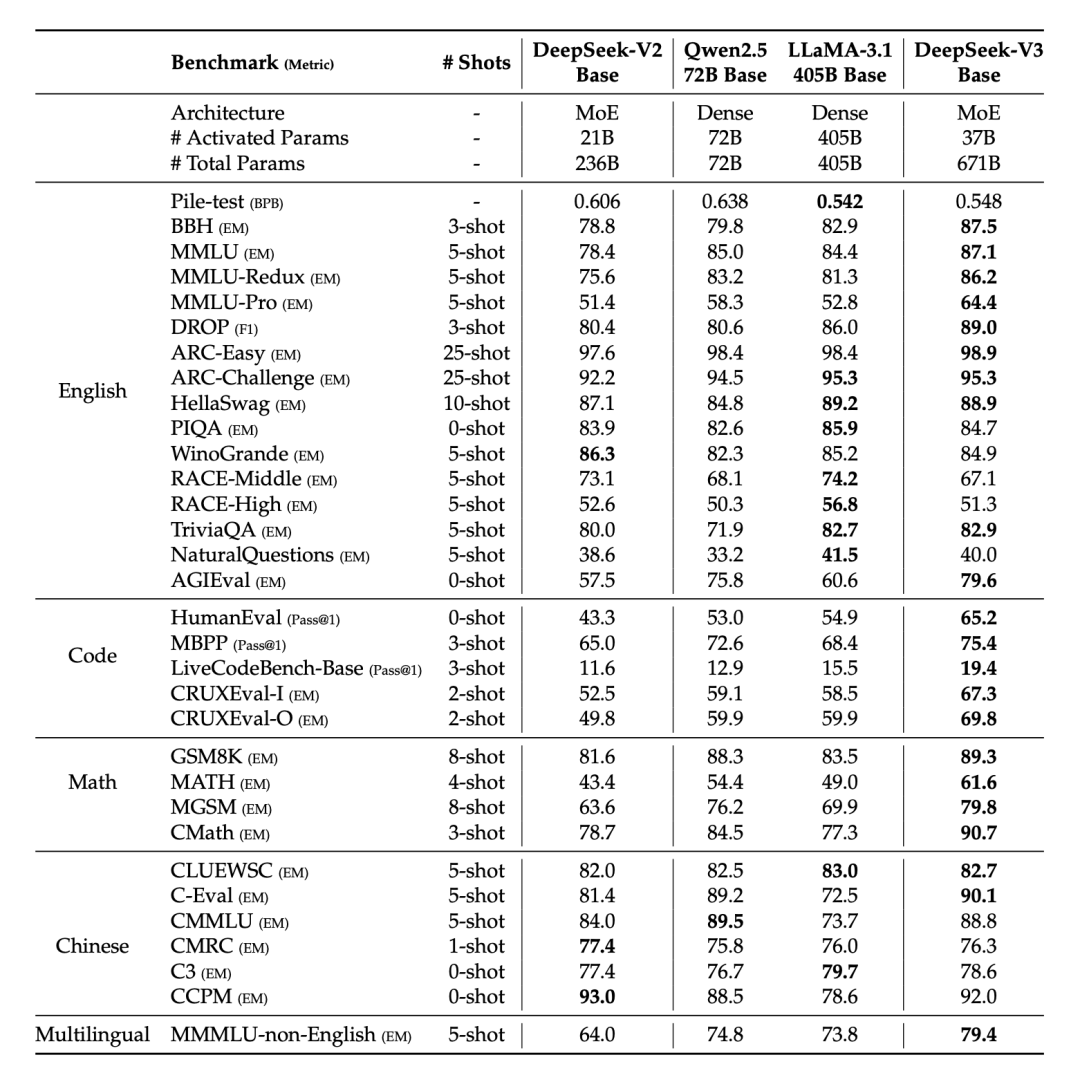
在與 DeepSeek-V2-Base、Qwen2.5 72B Base 和 LLaMA-3.1 405B Base 等開源基礎模型的對比中,DeepSeek-V3-Base 在 BBH、MMLU 系列、DROP、HumanEval、MBPP、LiveCodeBench-Base、GSM8K、MATH、MGSM、CMath 等幾乎所有任務上均取得最佳成績。
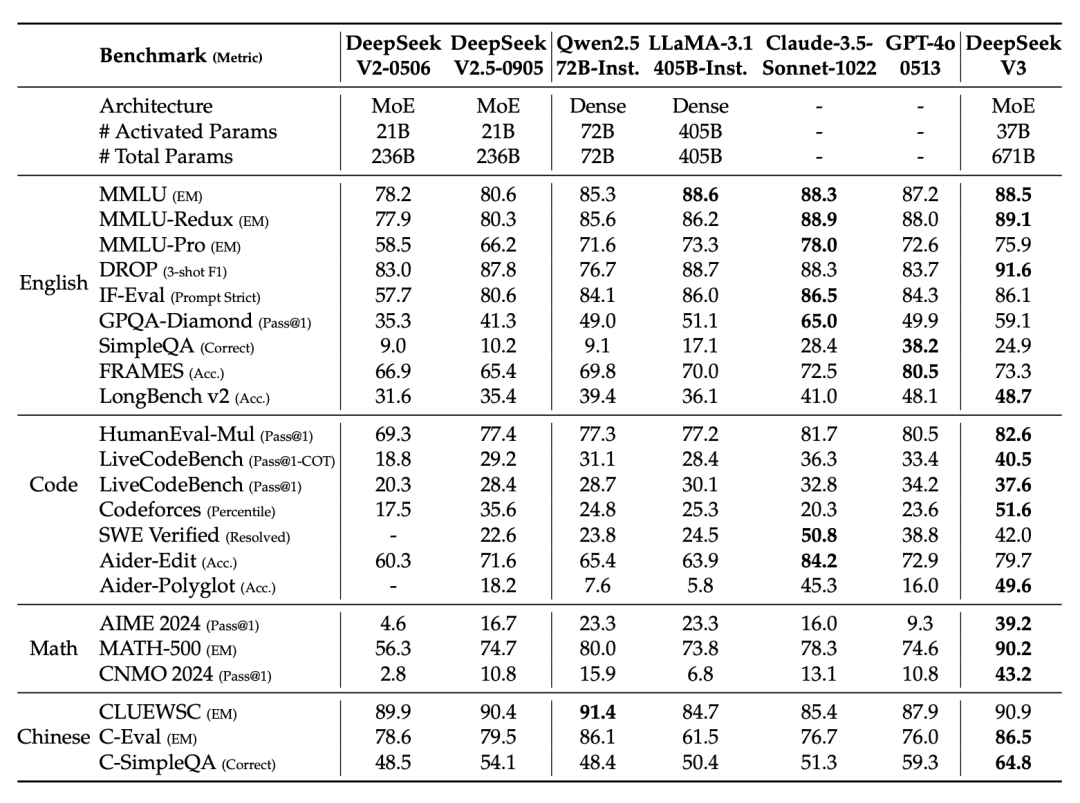
經過指令微調後,DeepSeek-V3 的性能進一步提升。在與包括 GPT-4o、Claude-3.5-Sonnet 在內的多個頂尖模型的對比中,DeepSeek-V3 在 MMLU、MMLU-Redux、DROP、GPQA-Diamond、HumanEval-Mul、LiveCodeBench、Codeforces、AIME 2024、MATH-500、CNMO 2024、CLUEWSC 等任務上,均展現出與其相當甚至更優的性能。
並且,這麼棒的數據,總成本只需要約 550 萬美金:如果是租 H800 來搞這個(但我們都知道,DeepSeek 背後的幻方,最不缺的就是卡)

架構
DeepSeek-V3 的這次發佈,伴隨三項創新:Multi-head Latent Attention (MLA)、DeepSeekMoE 架構以及無額外損耗的負載均衡策略。
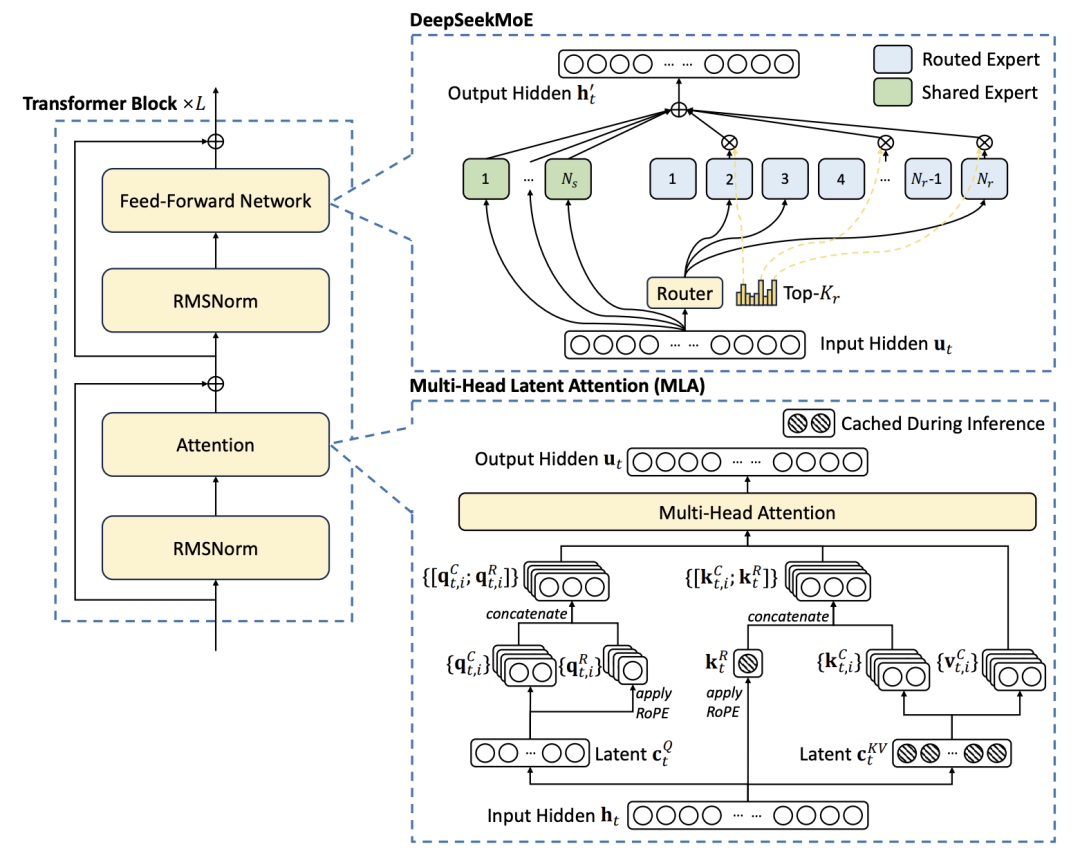
Multi-head Latent Attention (MLA):高效處理長文本
MLA 通過將 Key (K) 和 Value (V) 聯合映射至低維潛空間向量 (cKV),顯著降低了 KV Cache 的大小,從而提升了長文本推理的效率。DeepSeek-V3 中 MLA 的 KV 壓縮維度 (dc) 設置為 512,Query 壓縮維度 (d’) 設置為 1536,解耦 Key 的頭維度 (dr) 設置為 64。這種設計在保證模型性能的同時,大幅減少了顯存佔用和計算開銷。
DeepSeekMoE 架構:稀疏激活,高效擴展
DeepSeek-V3 採用的 DeepSeekMoE 架構,通過細粒度專家、共享專家和 Top-K 路由策略,實現了模型容量的高效擴展。每個 MoE 層包含 1 個共享專家和 256 個路由專家,每個 Token 選擇 8 個路由專家,最多路由至 4 個節點。這種稀疏激活的機制,使得 DeepSeek-V3 能夠在不顯著增加計算成本的情況下,擁有龐大的模型容量。
無額外損耗的負載均衡:MoE 的關鍵優化
DeepSeek-V3 提出了一種創新的無額外損耗負載均衡策略,通過引入並動態調整可學習的偏置項 (Bias Term) 來影響路由決策,避免了傳統輔助損失對模型性能的負面影響。該策略的偏置項更新速度 (γ) 在預訓練的前 14.3T 個 Token 中設置為 0.001,賸餘 500B 個 Token 中設置為 0.0;序列級平衡損失因子 (α) 設置為 0.0001。
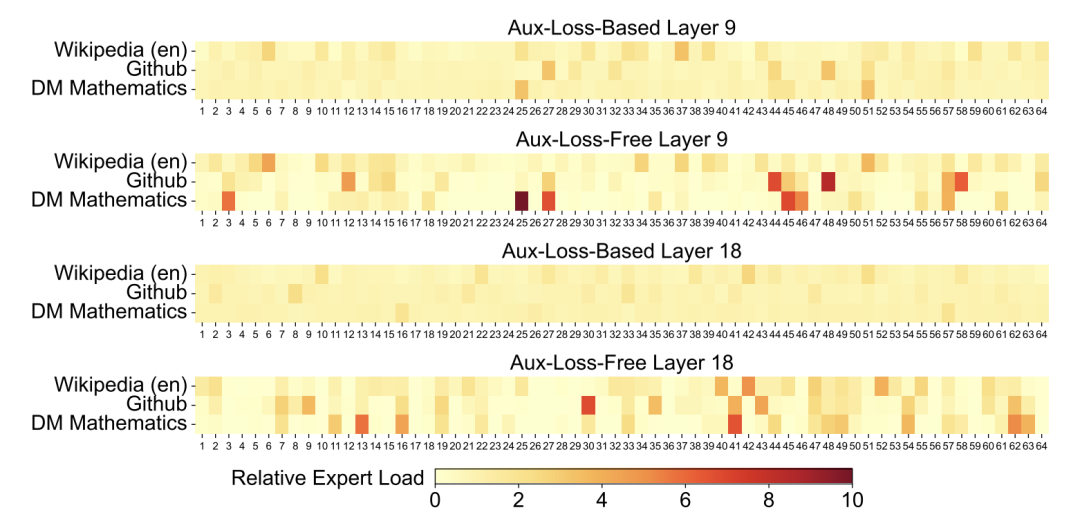
以上圖(報告第 28 頁,圖9)中的數據為例,使用了該策略的訓練模型在不同領域的專家負載情況,相比於添加了額外負載損失(Aux-Loss-Based)的模型,分工更為明確,這表明該策略能更好地釋放MoE的潛力。
工程
DeepSeek-V3 的這次發佈,伴隨多項工程優化貫穿了流水線並行、通信優化、內存管理和低精度訓練等多個方面。
DualPipe 流水線並行:雙向奔赴,消弭氣泡
DeepSeek-V3 採用了一種名為 DualPipe 的創新流水線並行策略。與傳統的單向流水線 (如 1F1B) 不同,DualPipe 採用雙向流水線設計,即同時從流水線的兩端饋送 micro-batch。這種設計可以顯著減少流水線氣泡 (Pipeline Bubble),提高 GPU 利用率。
此外,DualPipe 還將每個 micro-batch 進一步劃分為更小的 chunk,並對每個 chunk 的計算和通信進行精細的調度。通過巧妙地編排計算和通信的順序,實現了兩者的高度重疊。

單個 forward 和 backward chunk 的重疊策略(原報告第 12頁)。 如圖,如何將一個 chunk 劃分為 attention、all-to-all dispatch、MLP 和 all-to-all combine 等四個組成部分,並通過精細的調度策略,使得計算和通信可以高度重疊。其中,橙色表示 forward,綠色表示 “backward for input”,藍色表示 “backward for weights”,紫色表示 PP communication,紅色表示 barriers。

8 個 PP rank 和 20 個 micro-batch 的 DualPipe 調度示例(原報告第 13頁)。通過在 8 個 PP rank 上,20 個 micro-batch 的 DualPipe 調度情況,可以看到,通過雙向流水線的設計,以及計算和通信的重疊,流水線氣泡被顯著減少,GPU 利用率得到了極大提升。

DualPipe 在流水線氣泡數量和激活內存開銷方面均優於 1F1B 和 ZeroBubble 等現有方法。(原報告第 13頁)
通信優化:多管齊下,突破瓶頸
跨節點 MoE 訓練的一大挑戰是巨大的通信開銷。DeepSeek-V3 通過一系列精細的優化策略,有效地緩解了這一瓶頸。
-
節點限制路由 (Node-Limited Routing): 將每個 Token 最多路由到 4 個節點,有效限制了跨節點通信的範圍和規模。
-
定製化 All-to-All 通信內核: DeepSeek 團隊針對 MoE 架構的特點,定製了高效的跨節點 All-to-All 通信內核。這些內核充分利用了 IB 和 NVLink 的帶寬,並最大程度地減少了用於通信的 SM 數量。
-
Warp 專業化 (Warp Specialization): 將不同的通信任務 (例如 IB 發送、IB-to-NVLink 轉發、NVLink 接收等) 分配給不同的 Warp,並根據實際負載情況動態調整每個任務的 Warp 數量,實現了通信任務的精細化管理和優化。
-
自動調整通信塊大小: 通過自動調整通信塊的大小,減少了對 L2 緩存的依賴,降低了對其他計算內核的干擾,進一步提升了通信效率。
內存管理:精打細算,極致利用
DeepSeek-V3 在內存管理方面也做到了極致,通過多種策略最大程度地減少了內存佔用。
-
RMSNorm 和 MLA 上投影的重計算 (Recomputation): 在反向傳播過程中,DeepSeek-V3 會重新計算 RMSNorm 和 MLA 上投影的輸出,而不是將這些中間結果存儲在顯存中。這種策略雖然會略微增加計算量,但可以顯著降低顯存佔用。
-
CPU 上的 EMA (Exponential Moving Average): DeepSeek-V3 將模型參數的 EMA 存儲在 CPU 內存中,並異步更新。這種策略避免了在 GPU 上存儲 EMA 參數帶來的額外顯存開銷。
-
共享 Embedding 和 Output Head: 在 MTP 模塊中,DeepSeek-V3 將 Embedding 層和 Output Head 與主模型共享。這種設計減少了模型的參數量和內存佔用。
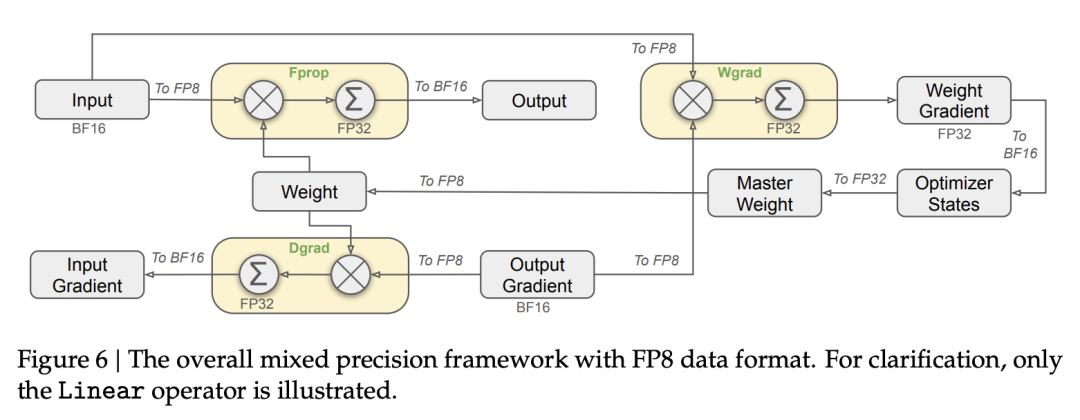
FP8 低精度訓練:精度與效率的平衡
DeepSeek-V3 通過 FP8 混合精度訓練,在保證模型精度的同時,大幅降低顯存佔用並提升訓練速度。
-
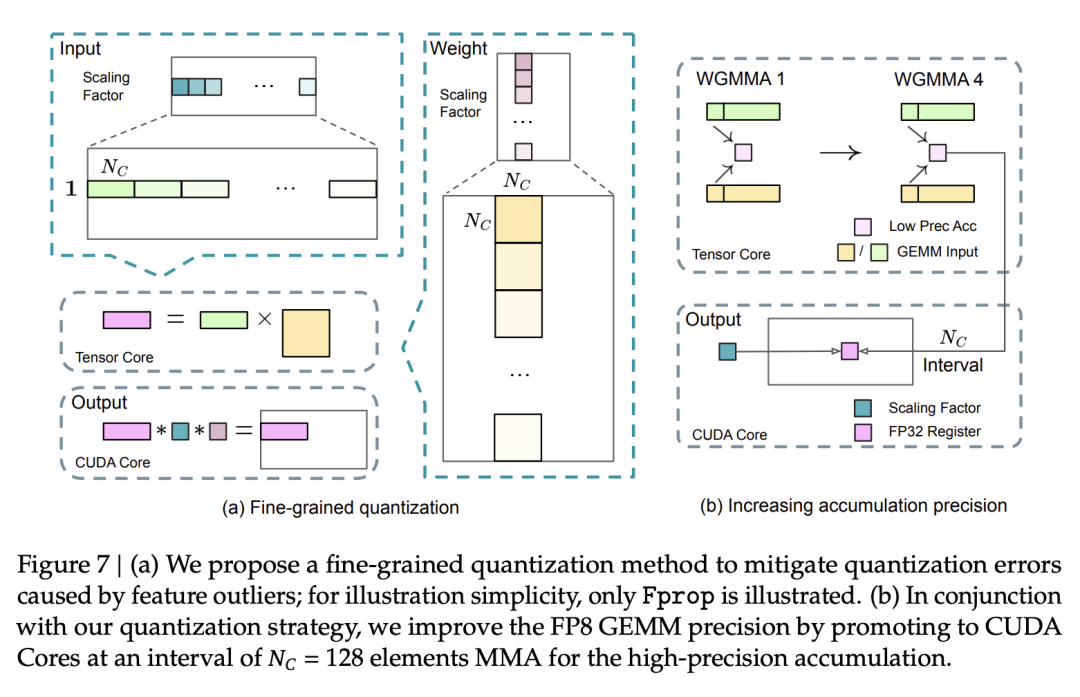
選擇性高精度: 對於模型中對精度較為敏感的組件 (例如 Embedding、Output Head、MoE Gating、Normalization、Attention 等),DeepSeek-V3 仍然採用 BF16 或 FP32 進行計算,以保證模型的性能。(圖 7,來自原報告第 15 頁)
-
細粒度量化 (Fine-Grained Quantization): DeepSeek-V3 沒有採用傳統的 per-tensor 量化,而是採用了更細粒度的量化策略:對激活值採用 1×128 tile-wise 量化,對權重採用 128×128 block-wise 量化。這種策略可以更好地適應數據的分佈,減少量化誤差。(圖 7a,來自原報告第 16 頁)
-
提高累加精度: 為了減少 FP8 計算過程中的精度損失,DeepSeek-V3 將 MMA (Matrix Multiply-Accumulate) 操作的中間結果累加到 FP32 寄存器中。(圖 7b,來自原報告第 16 頁)
-
低精度存儲和通信: 為了進一步降低顯存佔用和通信開銷,DeepSeek-V3 將激活值和優化器狀態以 FP8 或 BF16 格式進行存儲,並在通信過程中也使用這些低精度格式。(圖 10,來自原報告第 47 頁)
預訓練
DeepSeek-V3 的訓練策略涵蓋了數據構建、分詞其、超參數設置、長上下文擴展和多 Token 預測等多個方面。
數據構建
DeepSeek-V3 的預訓練語料庫規模達到了 14.8 萬億 Token,這些數據經過了嚴格的篩選和清洗,以確保其高質量和多樣性。相比於前代模型 DeepSeek-V2,新模型的數據構建策略更加精細。首先,大幅提升了數學和編程相關數據在整體數據中的佔比,這直接增強了模型在相關領域的推理能力,使其在 MATH 500、AIME 2024 等數學基準測試和 HumanEval、LiveCodeBench 等代碼基準測試中表現突出。其次,進一步擴展了多語言數據的覆蓋範圍,超越了傳統的英語和中文,提升了模型的多語言處理能力。
為了保證數據質量,DeepSeek 開發了一套完善的數據處理流程,著重於最小化數據冗餘,同時保留數據的多樣性。此外,他們還借鑒了近期研究 (https://arxiv.org/abs/2404.10830,Ding et al., 2024) 中提出的文檔級打包 (Document Packing) 方法,將多個文檔拚接成一個訓練樣本,避免了傳統方法中由於截斷導致的上下文信息丟失,確保模型能夠學習到更完整的語義信息。

針對代碼數據,DeepSeek-V3 借鑒了 DeepSeekCoder-V2 中採用的 Fill-in-Middle (FIM) 策略,以 0.1 的比例將代碼數據構造成 <|fim_begin|> pre<|fim_hole|> suf<|fim_end|> middle<|eos_token|> 的形式。這種策略通過「填空」的方式,迫使模型學習代碼的上下文關係,從而提升代碼生成和補全的準確性。
分詞器與詞表:兼顧效率與準確性
DeepSeek-V3 採用了基於字節級 BPE (Byte-level BPE) 的分詞器,並構建了一個包含 128K 個 token 的詞表。為了優化多語言的壓縮效率,DeepSeek 對預分詞器 (Pretokenizer) 和訓練數據進行了專門的調整。
與 DeepSeek-V2 相比,新的預分詞器引入了將標點符號和換行符組合成新 token 的機制。這種方法可以提高壓縮率,但也可能在處理不帶換行符的多行輸入 (例如 few-shot 學習的 prompt) 時引入 token 邊界偏差 (Token Boundary Bias) (Lundberg, 2023)。為了減輕這種偏差,DeepSeek-V3 在訓練過程中以一定概率隨機地將這些組合 token 拆分開來,從而讓模型能夠適應更多樣化的輸入形式,提升了模型的魯棒性。(下圖來自 Token Boundary Bias 的原文)

模型配置與超參數
DeepSeek-V3 的模型配置和訓練超參數都經過了精心的設計和調優,以最大化模型的性能和訓練效率。
-
模型配置:
DeepSeek-V3 的 Transformer 層數設置為 61 層,隱藏層維度為 7168。所有可學習參數均採用標準差為 0.006 的隨機初始化。在 MLA 結構中,注意力頭的數量 (nh) 設置為 128,每個注意力頭的維度 (dh) 為 128,KV 壓縮維度 (dc) 為 512,Query 壓縮維度 (d’) 為 1536,解耦的 Key 頭的維度 (dr) 為 64。除了前三層之外,其餘的 FFN 層均替換為 MoE 層。每個 MoE 層包含 1 個共享專家和 256 個路由專家,每個專家的中間隱藏層維度為 2048。每個 Token 會被路由到 8 個專家,並且最多會被路由到 4 個節點。多 Token 預測的深度 (D) 設置為 1,即除了預測當前 Token 之外,還會額外預測下一個 Token。此外,DeepSeek-V3 還在壓縮的潛變量之後添加了額外的 RMSNorm 層,並在寬度瓶頸處乘以了額外的縮放因子。
-
訓練超參數:
DeepSeek-V3 採用了 AdamW 優化器,β1 設置為 0.9,β2 設置為 0.95,權重衰減係數 (weight_decay) 設置為 0.1。最大序列長度設置為 4K。學習率方面,採用了組合式的調度策略:在前 2K 步,學習率從 0 線性增加到 2.2 × 10^-4;然後保持 2.2 × 10^-4 的學習率直到模型處理完 10T 個 Token;接下來,在 4.3T 個 Token 的過程中,學習率按照餘弦曲線 (Cosine Decay) 逐漸衰減至 2.2 × 10^-5;在最後的 500B 個 Token 中,學習率先保持 2.2 × 10^-5 不變 (333B 個 Token),然後切換到一個更小的常數學習率 7.3 × 10^-6 (167B 個 Token)。梯度裁剪的範數設置為 1.0。Batch Size 方面,採用了動態調整的策略,在前 469B 個 Token 的訓練過程中,Batch Size 從 3072 逐漸增加到 15360,並在之後的訓練中保持 15360 不變。
為了實現 MoE 架構中的負載均衡,DeepSeek-V3 採用了無額外損耗的負載均衡策略,並將偏置項的更新速度 (γ) 在預訓練的前 14.3T 個 Token 中設置為 0.001,在賸餘的 500B 個 Token 中設置為 0.0。序列級平衡損失因子 (α) 設置為 0.0001,以避免單個序列內的極端不平衡。多 Token 預測 (MTP) 損失的權重 (λ) 在前 10T 個 Token 中設置為 0.3,在賸餘的 4.8T 個 Token 中設置為 0.1。
長上下文擴展與多 Token 預測:錦上添花
為了使 DeepSeek-V3 具備處理長文本的能力,DeepSeek 採用了兩階段的訓練策略,將模型的上下文窗口從 4K 逐步擴展到 128K。他們採用了 YaRN (Peng et al., 2023a) 技術,並將其應用於解耦的共享 Key (k)。在長上下文擴展階段,DeepSeek-V3 的超參數保持不變:scale 設置為 40,β 設置為 1,ρ 設置為 32,縮放因子設置為 0.1 ln n + 1。
-
第一階段 (4K -> 32K): 序列長度設置為 32K,Batch Size 設置為 1920,學習率設置為 7.3 × 10^-6。
-
第二階段 (32K -> 128K): 序列長度設置為 128K,Batch Size 設置為 480,學習率設置為 7.3 × 10^-6。
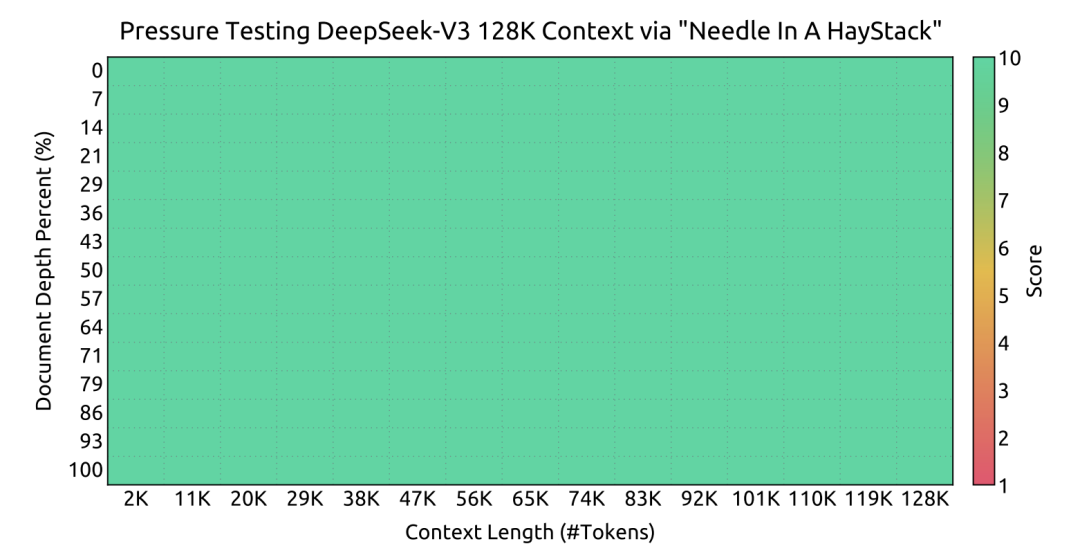
上圖(報告第 23 頁) 的 “Needle In A Haystack” (NIAH) 測試結果清晰地展示了 DeepSeek-V3 在處理長文本方面的卓越能力。
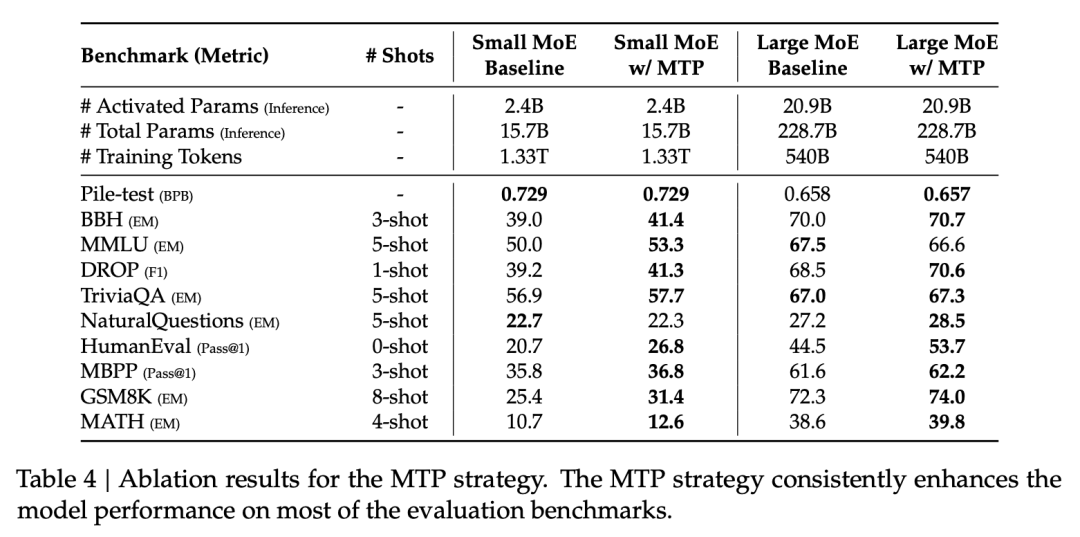
此外,DeepSeek-V3 還採用了多 Token 預測 (MTP) 策略 (2.2 節,第 10 頁),要求模型在每個位置預測未來的多個 Token,而不僅僅是下一個 Token。圖 3 (第 10 頁) 詳細展示了 MTP 的實現方式。
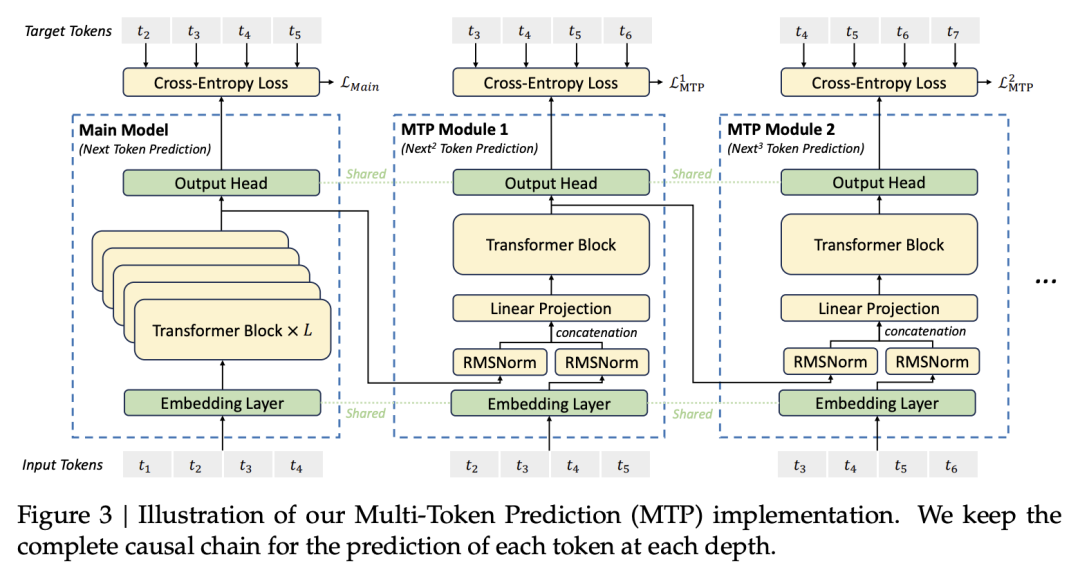
這種策略增強了模型的預見能力,並提供了更豐富的訓練信號,從而提升了訓練效率。表 4 (第 26 頁) 的消融實驗結果證明了 MTP 策略的有效性。
後訓練
DeepSeek-V3 的後訓練 (Post-Training) 階段,包括有監督微調 (Supervised Fine-Tuning, SFT) 和強化學習 (Reinforcement Learning, RL) 兩個步驟。
有監督微調 (SFT)
SFT 階段,DeepSeek-V3 在一個包含 1.5M 指令-響應對的高質量數據集上進行了微調。該數據集涵蓋了多種任務類型和領域,並採用了不同的數據構建策略,以最大程度地激發模型的潛能。
數據構建策略
-
推理數據 (Reasoning Data):對於數學、代碼、邏輯推理等需要複雜推理過程的任務,DeepSeek 採用了基於 DeepSeek-R1 模型生成的高質量推理數據。DeepSeek-R1 模型在推理任務上表現出色,但其生成的響應往往存在過度推理、格式不規範、長度過長等問題。為了兼顧 R1 模型生成數據的高準確性與標準答案的簡潔性,SFT 階段的數據構建採用了以下策略:
-
對於每個問題,生成兩種類型的 SFT 樣本:
-
在後續的 RL 階段,模型會利用高溫采樣 (High-Temperature Sampling) 生成多樣化的響應,這些響應會融合 R1 生成數據和原始數據中的模式,即使在沒有明確係統提示的情況下,也能生成高質量的響應。
-
經過數百步的 RL 訓練後,中間的 RL 模型會逐漸學會融入 R1 模型的推理模式,從而提升整體性能。
-
最後,利用訓練完成的 RL 模型進行拒絕采樣 (Rejection Sampling),生成高質量的 SFT 數據,用於最終模型的訓練。
-
<問題, 原始響應>:將問題與 R1 模型生成的原始響應直接配對。
-
<系統提示, 問題, R1 響應>:將問題與 R1 模型的響應配對,並在問題前添加一個精心設計的系統提示 (System Prompt)。該系統提示旨在引導模型生成更符合人類偏好的響應,例如更簡潔、更易懂的格式。
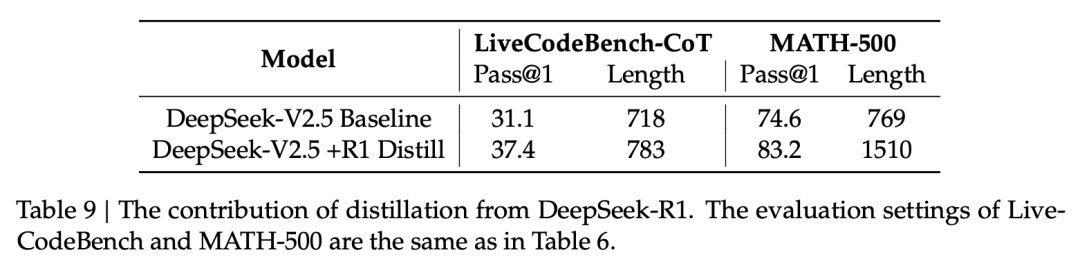
表 9 (第 34 頁) 展示了從 DeepSeek-R1 蒸餾知識對性能的提升。 可以看到,在 LiveCodeBench-CoT 和 MATH-500 任務上,經過 R1 蒸餾後,模型的 Pass@1 指標分別提升了 6.3 和 8.6 個百分點,證明了該策略的有效性。
-
非推理數據 (Non-Reasoning Data):對於創意寫作、角色扮演、簡單問答等非推理類任務,則利用 DeepSeek-V2.5 生成響應,並由人工進行標註和校驗,以確保數據的準確性和可靠性。
訓練細節
-
訓練輪數 (Epochs): 2
-
學習率調度 (Learning Rate Schedule): Cosine 衰減,從 5 × 10^-6 逐步降低至 1 × 10^-6。
-
樣本掩碼 (Sample Masking): 為了避免不同樣本之間的相互干擾,SFT 階段採用了樣本掩碼策略,確保每個樣本的訓練都是獨立的。
強化學習 (RL)
為了使 DeepSeek-V3 更好地對齊人類偏好,DeepSeek 採用了強化學習 (RL) 技術,並構建了基於規則的獎勵模型 (Rule-Based RM) 和基於模型的獎勵模型 (Model-Based RM) 相結合的獎勵機制。
-
基於規則的獎勵模型 (Rule-Based RM):對於可以通過明確規則進行判別的任務 (例如數學題、編程題),採用基於規則的獎勵模型。例如,對於數學題,可以設定規則檢查最終答案是否正確;對於編程題,可以利用編譯器進行測試用例驗證。這種方式可以提供準確且穩定的獎勵信號。
-
基於模型的獎勵模型 (Model-Based RM):對於難以通過規則進行判別的任務 (例如開放式問答、創意寫作),則採用基於模型的獎勵模型。該模型基於 DeepSeek-V3 SFT 階段的檢查點進行訓練,並採用了一種特殊的訓練數據構建方式:
-
偏好數據構建: 構建的偏好數據不僅包含最終的獎勵值,還包括了得出該獎勵值的思維鏈 (Chain-of-Thought),這有助於提升獎勵模型的可靠性,並減少特定任務上的獎勵「hack」現象。
-
模型輸入: 對於有明確答案的任務,模型輸入為問題和生成的響應;對於沒有明確答案的任務,模型僅輸入問題和對應的響應。
-
模型判斷: 對於有明確答案的任務,模型判斷響應是否與正確答案匹配;對於沒有明確答案的任務,模型根據問題和響應給出綜合評價。
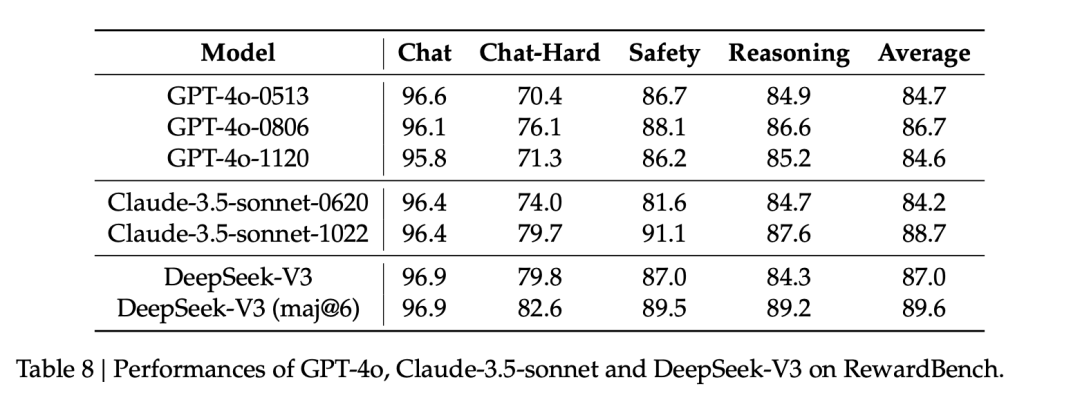
作為獎勵模型,在 RewardBench 上的表現上,DeepSeek 多個方面超越或持平 GPT-4o 和 Claude-3.5-sonnet。
RL 過程中,DeepSeek-V3 採用了 Group Relative Policy Optimization (GRPO) 算法 (原報告第 30 頁) 。與傳統的 PPO 算法不同,GRPO 不需要一個單獨的 Critic 模型來估計 Value 函數,而是通過比較一組樣本的獎勵來估計 Advantage。具體流程如下:
-
對於每個問題 q,從當前的策略模型 π_old 中采樣一組 K 個響應 {y_1, y_2, …, y_K}。
-
利用獎勵模型對每個響應進行評分,得到對應的獎勵 {r_1, r_2, …, r_K}。
-
計算每個響應的 Advantage 值:A_i = (r_i – mean(r)) / std(r),其中 mean(r) 和 std(r) 分別表示該組獎勵的均值和標準差。
-
根據以下目標函數更新策略模型 π_θ:
-
[公式 26 和 27 (第 30 頁)]
-
其中,π_ref 是參考模型 (通常是 SFT 階段的模型),β 和 ε 是超參數。
數據配比
在後訓練過程中,DeepSeek-V3 整合了多種類型的數據,數據來源和配比如下:
-
數學推理類數據: 主要來自 DeepSeek-R1 模型生成的數學題解題步驟和邏輯推理過程。這類數據在後訓練階段佔比約為 25%。
-
代碼生成類數據: 包括了從開源代碼庫中精選的代碼片段,以及利用 DeepSeek-R1 模型生成的代碼補全和代碼解釋數據。這類數據佔比約為 20%。
-
通用領域對話數據: 涵蓋了開放域問答、創意寫作、角色扮演等多種任務類型,主要利用 DeepSeek-V2.5 生成,並經過人工校驗。這類數據佔比約為 45%。
-
安全和倫理類數據: 包含了用於提升模型安全性和符合倫理規範的指令和響應數據,佔比約為 10%。
以及…