南大周誌華:百萬模型進入學件基座系統,很多我們沒預期過的事也有可能實現 | MEET 2025
編輯部 發自 凹非寺
量子位 | 公眾號 QbitAI
大模型時代,全世界AI從業者追趕OpenAI GPT系列的腳步仍未停歇,但也有人,堅持深耕在國產原創的另一條大模型之路上。
南京大學副校長、國際人工智能聯合會理事會主席周誌華教授,就是其中代表。他提出的「學件範式」,旨在從數據隱私角度著手,通過模型+規約的方式構建基座系統,讓用戶的需求能被自動匹配到合適的模型、模型組合上,安全、可靠地複用他人開發的模型工具。
用戶只需要提出需求,學件基座系統就會根據需求,從無數學件中去找出一個或者若幹個學件,甚至把它們組裝起來解決問題。
在MEET 2025智能未來大會上,周誌華教授從宏觀角度和技術角度詳細為我們分享了學件範式的最新進展。

為了完整體現周誌華教授的觀點,在不改變原意的基礎上,量子位對演講內容進行了編輯整理,希望能給你帶來更多啟發。
MEET 2025智能未來大會是由量子位主辦的行業峰會,20餘位產業代表與會討論。線下參會觀眾1000+,線上直播觀眾320萬+,獲得了主流媒體的廣泛關注與報導。
核心觀點
-
學件=模型+規約。規約通過對模型進行刻畫,可以使模型在不知道開發者數據的情況下被複用。
-
用戶只需要提出需求,學件基座系統就會根據需求,從無數學件中去找出一個或者若幹個學件,甚至把它們組裝起來解決問題。
-
學件基座系統可以看作異構大模型,隨著更多的模型被提交,它會長大、重組,未來提供服務的時候一定程度還提供了可解釋性,和現在常見的大模型不同。
(以下為周誌華教授演講全文)
學件=模型+規約
大家好,很高興跟大家做交流,我的題目叫作《學件和異構大模型》。
大模型大家都很清楚是什麼,那麼學件是什麼?
我們知道計算機里有硬件,有軟件。大概在9年前,那時候還沒有大模型,深度神經網絡也剛剛開始被大家注意,那時候我們發表了一個東西,向大家公開我們的預期,說機器學習這樣發展下去會不會產生一種形態,我們命名為學件(Learnware)。學件從這個詞從概念,再到研究體系,都是我們完全原創的。
我今天主要跟大家介紹一下這條路線在做什麼事。
因為考慮到今天這個場合大家主要需要一些宏觀理解,而不是技術細節,所以我們先思考這幾個問題。
第一個問題:未來機器學習解決世界上的問題,是會用一個模型解決一切,還是用很多模型協作?我想大家都會有自己的回答,我們的回答是B——可能我們需要很多模型協作。
第二個問題:這些模型是會由一位開發者開發,還是很多開發者各自開發?我們認為這個答案應該也是B。
第三個問題:這麼多來自世界各地的開發者,他們開發的模型都有自己的數據,他們會把數據都公開嗎?我們認為答案很可能是不公開。
第四個問題:數以百萬計的模型,是不是能一次性全部產生,還是陸陸續續的,今天有一些,明天有一些,後天有一些?我想這個答案肯定是B。
第五個問題:對未來某位人工智能用戶,全世界數以百萬計的模型都對他有用嗎?還是只有少量甚至個別模型有用?答案還是B。
第六個問題:對於用戶來說,這些已經存在的模型中,一定有某個模型能解決他的任務嗎?還是未必有?說不定我們可以通過組裝一些模型來解決這個任務。我們認為答案還是B。
有了這麼多問題之後,歸結起來就是這麼一個問題:在拿不到開發者的訓練數據,甚至用戶也不願意公開自己數據的情況下,我們如何知道數以百萬計、全世界各個開發者開發的模型中,哪個或者哪些經過組裝之後對用戶是有幫助的?我們如何能夠對來自不同的開發者、針對不同任務的模型進行組裝複用,或者就像大家都在談的,大小模型協同。
學件這條路線就是在往這個方向努力。
學件是什麼呢?學件=模型+規約。為了便於理解,我們舉一個類比,假設現在世界上有很多開發者做出他們的模型,他們願意分享他們的模型,在這個圖上,每一把刀、每一個錘子、每一把斧頭都是一個機器學習模型。
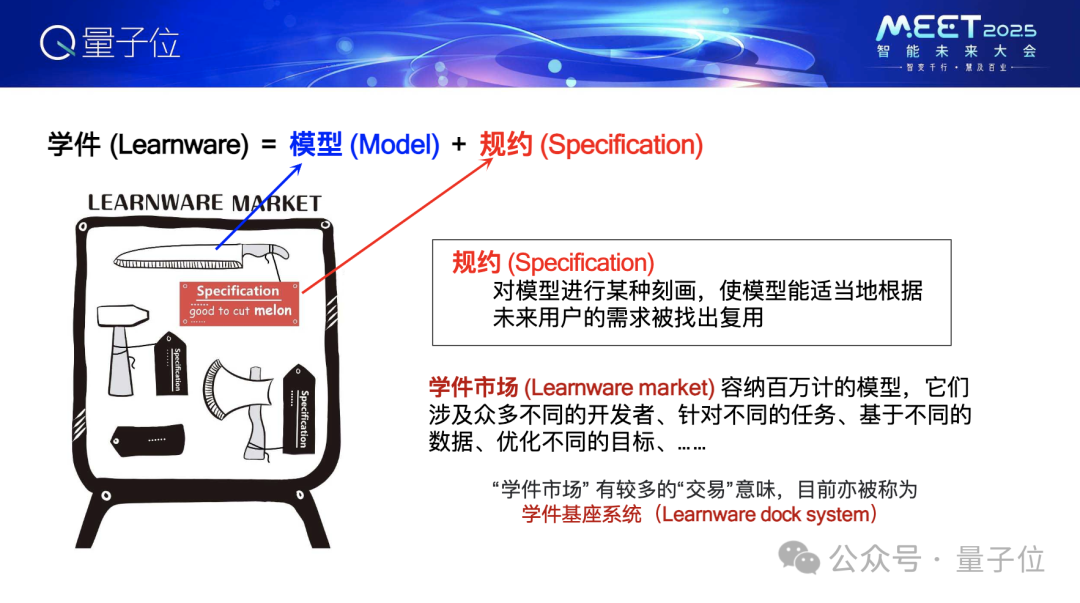
模型大家都清楚,規約是什麼?就是對模型進行某種刻畫,使得系統在不知道開發者數據的情況,能夠根據未來用戶的需求被找出來複用。
容納這些模型的地方,一開始我們把它叫作「學件市場」,好比一個超市。後來有專家跟我們討論,說「市場」給大家感覺是要做交易。其實未來確實是可以做交易,比方說被用得很多的學件,可以收費,收費之後再回報給開發者。但在現在,我們主要關注其中的科學技術問題,所以我們現在也把它叫學件基座系統。
有了這個基座系統之後,未來用戶想要開發自己的AI任務,就不需要從頭開始。今天當我們要做一個自己的機器學習應用的時候,我們要蒐集數據,要訓練模型,要調參數,但是在別的領域不是這樣的,比如說要買一把切肉的刀,我絕對不會說自己再去採礦炒籃,我會到超市上看一看,有沒有這樣的刀。就算沒有,我找一把西瓜刀拿回家,用我自己的數據打磨打磨,說不定就能用了。
所以我們希望未來的用戶只需要提出需求,然後學件基座系統根據用戶需求,在學件基座系統所容納的無數學件中去找出一個或者若幹個,甚至組裝起來解決你的問題。注意,在整個過程中,開發者的數據不披露給學件基座系統,甚至用戶的數據也不需要披露給學件基座系統。
這個事情2016年發表了第一篇論文提出這件事,後來的七年時間裡面,我們沒有發表論文,一直在解決這裡面的關鍵科學技術問題,目前這些問題有了初步的解決方案。在講技術方案之前,我們先宏觀地來看,和以往有什麼不同。
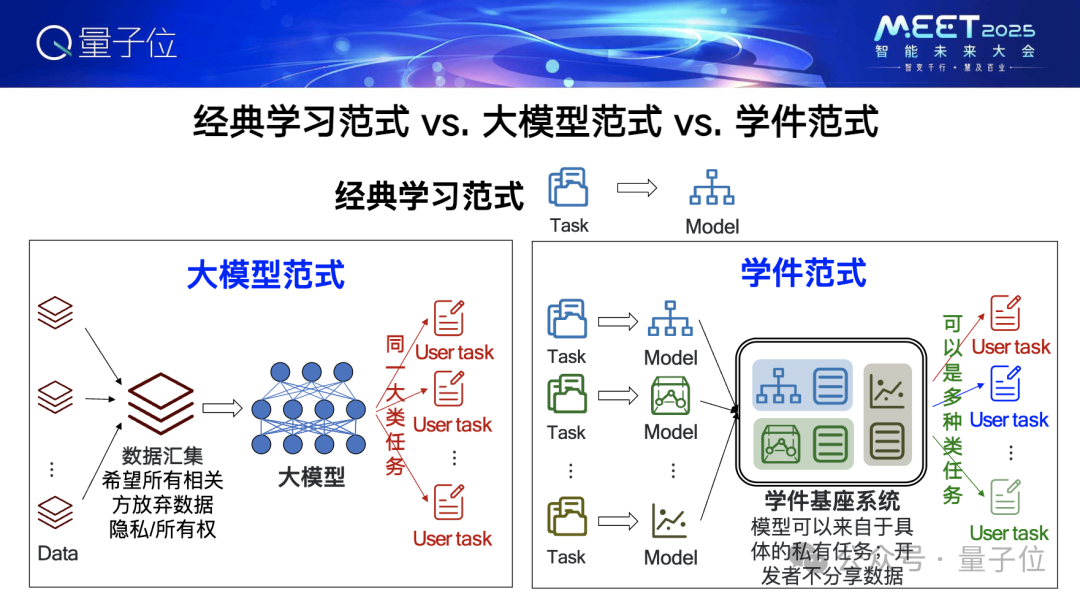
經典的機器學習範式,是針對某個任務做一個模型解決它。
大模型範式,是彙集很多數據去訓練一個模型。彙集數據的過程實際上是希望數據相關方要放棄隱私和擁有權,這對對話、影片這樣的任務是比較容易做到的,但對生產生活中的很多任務其實不太容易。比方說,哪怕是同一個類型的企業,往往也不願意把數據分享出來給你收集起來訓練模型,許多企業認為,一旦把數據分享出去,通過大模型,就等於技術優勢分享給同行了。但如果只能用企業內部數據,往往又不夠大模型訓練。
學件這個範式的關鍵,是不收集你的數據,只是彙集起不同的模型。這些模型可以是為很私有的任務開發的,你不需要披露你的訓練數據。另外,模型的黑箱性一般認為是個壞事,而在這裏卻能夠起到正面作用。有了這些模型之後,大家容易想到,可以為未來的很多任務提供服務,它們不必須是同一大類的。這很容易理解,比如有天氣預報的模型,以後當然可以做天氣預報,有地震預測模型,以後當然可以做地震預測。但是需要認識到,對某些我們從來沒有考慮過的任務,也有可能通過把若幹個模型拚裝起來解決它。
舉個例子,假設我們要考慮A和D分類,從來沒有開發者做過這種模型,但有人做過A和B,有人做過B和C,有人做過C和D,就有可能把它們組裝起來解決A和D的分類任務。
所以這是一條和一般大模型不同的路。第一假設所有模型都潛在有用,即便對開發者不太好的模型,對別的用戶說不定是有用的。第二可能很多小模型彙集在一起之後,能夠做一些今天我們認為只有大模型才能做的事,當然大小模型協作都可以在其中完成,而且不存在災難性遺忘,因為一個模型只要放在基座系統中,除非它的能力被完全替代,否則就一直在哪裡,天然在進行終身學習,而且不必披露開發者和用戶數據。另外,開發者提交的模型,在未來適用的時候可能超越開發者原本的意圖,用於解決他完全沒考慮過的任務。
從哲學方法論上來說,如果說大模型是幾個大英雄打天下的話,學件則是認為「力量蘊藏在人民群眾」中。我們預期,學件基座系統容納了數以百萬計的模型之後,這條路線的力量會更加湧現出來,很多我們原來沒想過的事都有可能做。
學件基座系統可視作異構大模型
回到技術問題上。
規約是什麼?它需要對模型進行適當刻畫。大概是什麼做法,涉及到兩方面,一個是學件基座系統,一個是模型開發者。
首先學件基座系統給開發者發送兩個信息k和n,k是某個函數,n是規約大小。模型開發者用自己的數據訓練模型,基於基座系統提供的k和n生成規約。他提交模型的時候,把規約和模型一起提交。

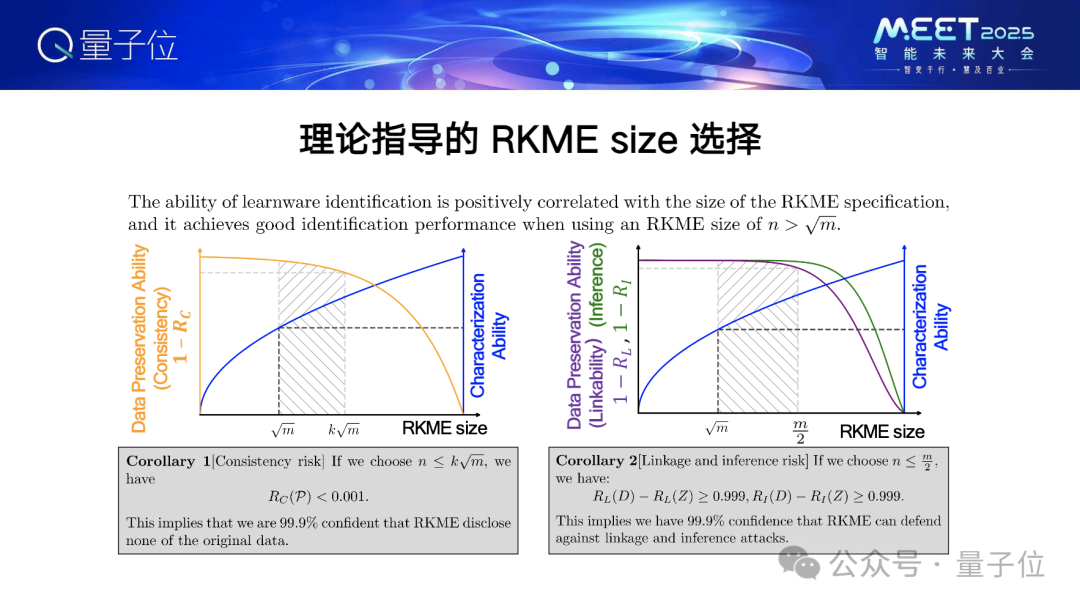
我們可以看到,所有的訓練數據一直在模型開發者手上,基座系統是不接觸數據的,碰到的只有提交的模型和規約。大家要問了,這個規約是基於你給我的k和n生成的,你有沒有可能根據這個把我的訓練數據破解出來?
我們最近做了一個理論證明,首先,規約不會包含開發者訓練數據,第二,即便對信息安全中強大的推斷攻擊和鏈接攻擊,並且是針對確定性算法最強的暴力搜索這樣的攻擊,仍然可以有效地保護開發者的數據。而且有了這個結果之後,我們就可以得到關於規約大小設置的理論指導,通過設置為合適的大小,既能起到數據保護作用,還能支持模型複用。
為用戶提供服務的時候,學件基座系統有可能是反饋最好的某個模型,也可能是多個模型的結合,例如簡單的集成,或者加權結合,其實最近大模型經常用的MoE就是加權結合的特例,學件還可以做鏈式結合、樹形結合等等很多種模型的結合方式。這裡面還有很多探索空間。
進一步來說,隨著學件基座系統中容納的學件不斷增長,學件規約能否成長,使其能容納越來越多的模型,且對模型的刻畫能力有所增強?
另外,我們還研究了如何使得規約能夠成長,以及學件基座系統如何隨著收到更多的模型而成長,這裏用到了規約索引樹、稀疏哈希等技術,有很多模型不斷接收進來,多到一定程度之後,內部會重新組織,這樣得到一個可成長、可演化的基座系統。
從這個角度可以看到,如果把整個學件基座系統看做一個異構大模型,它和現在各種大模型不太一樣,是一個可成長可演化的大模型,宏觀上可以理解為人民群眾組成集體是超級大模型。
我們最近開源了北冥塢學件基座系統,歡迎大家來使用,這是一個科研原型系統。現在許多老師同學感覺,大模型時代,在高校院所裡面因為算力不夠,難以開展科研工作了。大家可以跟企業合作開展大模型方面的研究,另一方面,學件這條路線的研究目前還不需要多大算力,並且我們目前做的都是非常粗淺的解決方案,對學件這條路線感興趣的老師同學,如果要做研究,要做實驗,那麼就可以在這個基座系統中做實驗,大家應該能做出更聰明的解決方案。
另一方面,這個基座系統裡面現在容納模型還不多,還不能提供服務,歡迎大家有模型提交上來,未來模型很多之後可望能提供服務。現在國際上也出現機器學習模型平台,相比而言,學件2016年就提出了,裡面的構想要精巧得多,能力會強得多,並且未來還有很大潛力發展空間。但我們作為高校師生開發的系統,工程化能力肯定是短板,如果有企業希望基於這個開發自己學件基座系統,我們也歡迎大家來合作。謝謝!
謝謝!
北冥塢:
https://bmwu.cloud