強化學習之父 Rich Sutton 最新演講:用「去中心化神經網絡」應對深度學習局限性

災難性遺忘是大模型時代的下一個突破口。
作者丨王悅
編輯丨陳彩嫻
在人們為 AI2.0 時代的技術進步驚呼和欣喜之時,人工智能和其背後深度學習、神經網絡土壤的真實發展水平如何?
關於這一問題的答案或許可以在第六屆國際分佈式人工智能會議(Distributed Artificial Intelligence Conference,DAI 2024)上窺知一二。DAI 2024 已在新加坡管理大學成功舉辦,本屆會議的亮點之一就是邀請到現代強化學習的奠基人 Richard S. Sutton 教授、崑崙萬維榮譽顧問顏水成博士、UC Berkeley Sergey Levine 教授和 Google DeepMind 研究科學家 Georgios Piliouras 博士這四位重量級嘉賓,從多智能體系統、強化學習和具身智能等方面,提出了新的思路和解決方案,給人工智能領域的前沿研究以啟發和全新視角。
DAI 2024 現場,現代強化學習的奠基人、阿爾伯塔大學教授 Richard S. Sutton 教授在開幕禮上發表了題為《Decentralized Neural Networks》的主旨演講。Sutton 教授指出,當前人工智能的發展尚未達到真正意義上的全面實現,其主要瓶頸在於深度學習的局限性。這些問題包括災難性遺忘、可塑性喪失以及模型坍塌等現象,對人工智能的持續學習能力構成了重大挑戰。
為應對這些問題,Sutton 教授提出了「去中心化神經網絡」的全新概念。該方法的核心理念是賦予每個神經元獨立的目標,例如向其他神經元傳遞有效信息、保持自身活躍等。這種設計旨在實現一種動態平衡:保持「骨幹」神經元的穩定性,同時鼓勵「邊緣」神經元進行探索,從而增強網絡的適應性和持續學習能力。
在演講中,Sutton 教授還分享了他的創新算法——持續反向傳播(Continual Backprop)。該算法通過在每輪反向傳播中,根據神經元的活躍度選擇性地重新初始化部分神經元,從而提升模型的靈活性和學習效果。實驗表明,該算法在多個持續學習任務中表現優於傳統反向傳播方法,為持續學習領域提供了新的解決方案。
AI 科技評論在不改變原意的前提下進行整理:
我想先從總體上談談人工智能以及我們應該如何抱有雄心壯誌。當下,我們到底在嘗試做什麼?我們試圖充分理解智能,以便創造出比當前人類更智能的生物。這是一個深刻的智力里程碑。我們將豐富我們的經濟,改變我們的社會制度,這將是變革性的、全新的,但同時也是延續了古老趨勢的。人們一直在創造工具,而這些工具也改變了他們。
那麼,下一步重大的步驟將是理解我們自己,為此構建工具,這是一個宏偉而光榮的探索,是典型的人類行為。我認為,這是思考人工智能的適當背景。
再次強調,我們必須以謙遜的態度面對這個問題,這是一個如此巨大、重要的問題,而我們面對它時顯得如此渺小。我們試圖在這方面取得進展。這正在發生,而且將會發生。認識到它將會發生並嘗試成為其中的一部分,並不是傲慢的。

這就是我的出發點,我的底牌已經擺在桌面上了。在科學中,方法和哲學的混合很重要,一方面是你想要絕對確立和改進的科學內容,但同時你也必須有策略和方法,這對於我今天想要談論的內容非常相關。
我今天要談論的,我稱之為《去中心化的神經網絡》,這隻是一個我正在發展的想法。所以這不是一個我會向你們展示最終產品的東西。我會向你們展示一些想法,並且我會提出一些硬性的結果,這些結果至少為這些想法提供了動機。
我想從我的結論開始。過去,所謂的分佈式人工智能或者說去中心化人工智能,我們更傾向於將其視作是一群像運行網絡或為某種大型活動做出貢獻的 Agents。我走的是另一條路,我會將其看作一個單一的心智、一個單一的大腦,將其視為分佈式的,它由許多本身就是目標尋求系統的組件組成,它們本身就是有目標的 Agents。
我要說的是,這些 Agents 就是人工神經網絡中的神經元。

1
DL & ANNs——All is not well
所以我想從我的結論開始。今天的深度學習和人工神經網絡並不是一切都很好。它們會災難性地忘記,失去可塑性,實際上會在延長訓練的條件下崩潰。
這些問題很多都與延長訓練有關,而我們通常不會在深度學習中遇到這些問題,因為我們通常不會進行延長訓練。我們只是訓練一會兒然後就停止並凍結系統。
但如果真的想要製造一個能夠度過一生的 Agent,它就必須持續學習。強化學習、Agent都想要持續學習。因此,它們能夠應對持續的、延長的訓練或學習是非常重要的。
為了實現全部潛力,需要更多的東西。我會為此提供證據,我們需要網絡中未充分利用的人工神經元的額外變異源。所以網絡必須嘗試不同的事情。然後我們需要保護和保留那些變異有用的神經元。這是一種生成性測試。其核心目標就是你嘗試各種事物,保留好的那些。
現在,對我來說,這些需求強烈表明神經元應該有讓其他神經元傾聽的去中心化目標。現在,這對我來說是一個強烈的建議,這是我正在思考的事情,我不能證明,我會嘗試和你討論這個想法,我會證明深度學習的局限性、弱點,並向你展示一些技術,讓它們更好地工作。但這種去中心化的想法只是我將要向你提出的一個想法,我目前還無法真正證明它。

今天我將討論網絡中的神經元這個概念。這些神經元自身有目標,它們想要連接其他神經元,它們想要為整個網絡做出貢獻。我將展示一些關於傳統深度學習的新的證據問題。這是我們幾個月前在《Nature》雜誌上發表的證據,我們展示了深度學習在持續監督學習中會失去可塑性。
其次,我們已經展示了深度學習在長時間的強化學習中可能會崩潰。這些問題已經得到瞭解決。我們通過引入變異和選擇性生存來解決它們,也就是嘗試一系列事物並保留好的那些。因此,我認為這是去中心化目標的基礎,這些 Agent 將嘗試為網絡做出貢獻。我認為用這些術語來思考將會是有用的。
我將展示的第二件事,是來自阿爾伯塔大學的一些新工作,他們開發了這些在線流算法用於強化學習,這一直是我們在深度學習中無法與之競爭的流算法。流算法意味著數據流經它們,它們不保存任何數據,每個數據有一個固定的計算量,你不需要保存任何東西,所以你可以在事情發生時完全處理它們,然後丟棄它們。這是自然的學習方式。

首先,我應該定義一下我所說的去中心化神經網絡是什麼意思。它是一個其神經元追求的目標與整個網絡的目標不同的網絡。去中心化意味著沒有中央控製器。有多個 Agent 在執行任務,但作為一個整體,我們希望最終能形成一個強大的智能網絡。
例如,整個網絡可能尋求最大化其強化學習系統的獎勵,或者它可能尋求按照訓練集的指示對圖像進行分類以監督學習系統。但單個神經元可能有其他目標,比如它們可能想要提供網絡中其他神經元發現有用的信號。這是一個局部目標,或者是它們可能想要自我規範化,並且在一定時間分數內保持活躍。這是它們獨立於網絡整體目標的局部目標的衡量。所以,去中心化神經網絡的說法是一個由追求目標的組成部分構成的目標尋求系統。

現代強化學習最初被構想為一個去中心化的神經網絡。所以,如果 Andy Bartow 和我可能是現代強化學習之父,那麼 A. Harry Klopf 就是祖父,因為他是讓我們開始這一切工作的人。他寫了《The Hedonistic Neuron》這本書,提出單個神經元。他將單個神經元視為尋求目標的實體,尋求事物和避免事物。大腦中的神經元類似於社會中的人。每個人都是享樂主義者。
他實際上認為新的通常的神經元試圖獲得興奮並避免被抑制。他非常注重這個短語,即從尋求目標的組件中尋求目標的系統。而Andy Barton和我在1980年左右在馬莎諸塞大學工作時研究了它。
Klopf 的科學貢獻是認識到這種去中心化的觀點,或者只是思考想要東西的代理,這對我們今天來說並不明顯。當時,它在所有工程學、所有控制論、所有神經網絡中都是不存在的。沒有代理想要某物的概念。它已經變成了監督學習,即他們不想要某物,他們只是做他們被告知的事情。他們不試圖改變世界,他們試圖匹配世界正在做的事情。而 Klopf 認識到了這一點,並在資助了 Andy Barton 和我在馬莎諸塞大學的工作。所以他真的是現代強化學習的祖父。
實際上強化學習像山一樣古老。Marvin Minsky 在他的博士論文中做了關於強化學習的研究,但他後來它變得不流行了,因為他們並不真正接受代理尋求事物的想法。他們認為它變成了監督學習。

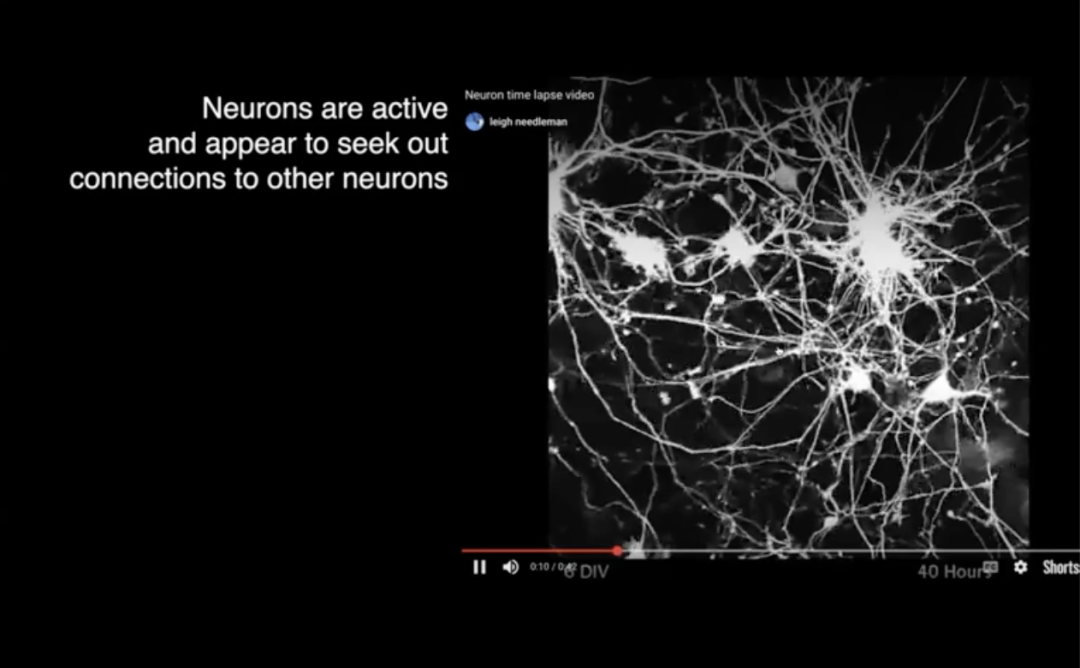
這些是一些真實神經元的時間延遲攝影,它們在培養中,但重點是這些神經元正在伸出纖維。它們的樹突和軸突末端有生長錐,不這樣想是很難的:這些神經元試圖做一些事情。
它們試圖找到其他單元連接,其他神經元連接,並參與網絡。所以,這是鼓舞人心的,但我們可能會想像我們的神經元以這種方式工作,就像 Harry Klopf 所做的那樣。
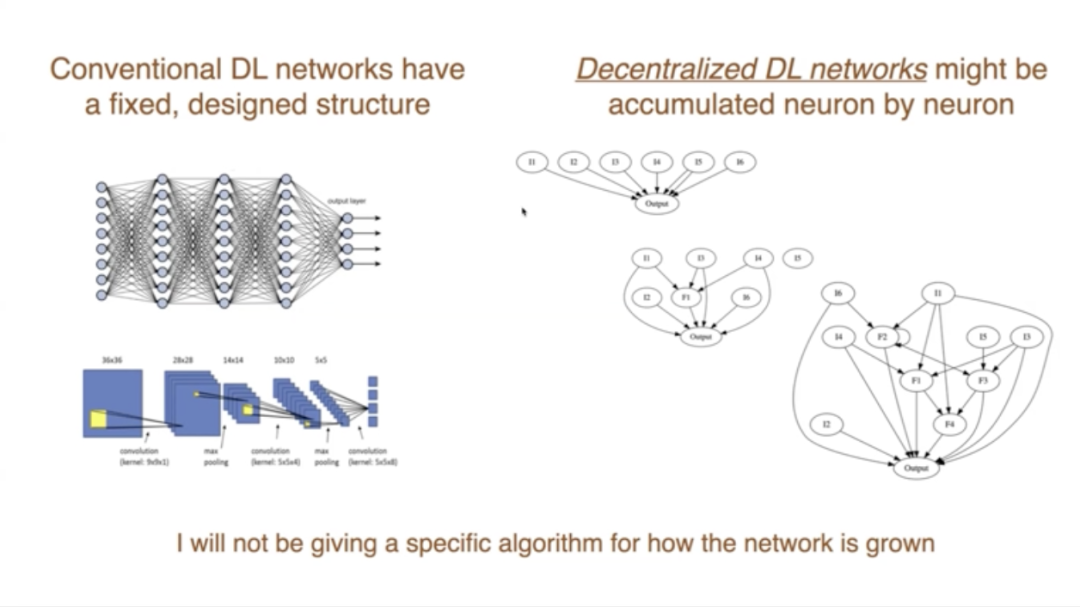
所以,我認為一個去中心化的神經網絡應該在三個層面上進行適應。它應該適應連接線,正如我們剛剛看到的,神經元伸出連接線與其他神經元形成連接;然後我們還要適應權重;第三,雖然不那麼明顯,我們要適應步長參數,這些參數決定了學習的速度,有時它們被稱為學習率參數,但最好稱之為步長參數。我相信,這對於神經網絡的未來來說是一個非常重要的理念,所以我們將會討論它。

現在,如果我們想改變結構,首先就注意到傳統的深度學習,它們有一個非常固定的預設計結構,通常是分層的,並且這些層有特殊的功能。另一種做法是讓網絡自然生長,所以你可能會從一個輸出單元和幾個傳感器、輸入開始,然後隨著你添加新的特徵,你會得到一個更複雜的網絡。在這個過程中,你會一點一點地積累神經元,變得更加複雜、更有能力。
所以我認為,如果這是一個去中心化的網絡,並且試圖為網絡做出貢獻,這將是一種更自然的方式。一旦為網絡做出了貢獻,你就成為了網絡的一部分。在那之前,你只是在探索並嘗試做一些有助於貢獻的事情。
第一個觀點是我們區分網絡中已經學習過的部分,我將這部分稱為骨幹網絡。你確定了權重是非零的,特別是它們通過網絡連接並影響網絡的輸出。現在確實在現代神經網絡中,許多神經元根本不是這樣的,它們對網絡的輸出沒有貢獻。所以,我們中的一些人會稱它們為死亡的,我不想讓你認為它們是死亡的,所以我將給它們一個不同的名字,將稱它們為邊緣部分。
骨幹網絡是我們目前正在使用的,我們學到的知識,而邊緣部分是我認為它們在邊緣嗡嗡作響並試圖形成一些對網絡有用的功能,一些信號,然後網絡將選擇性地傾聽。所以本質是我們要保護和維護骨幹網絡。在邊緣部分,我們希望它更具探索性。這實際上幾乎與常規反向傳播所做的相反。如果你想反向傳播,如果你影響了輸出,那些線性概率反向傳播會改變。通過梯度下降,你將改變那些已經影響輸出的,而那就是誤差。而那些不影響任何東西的,你根本不會改變它們,因為它們的梯度將為零。

為了更直觀地說明這一點,我做了這張圖。這裏有一個神經網絡,經過完全學習後,它們都有很多死亡單元。所以這裏的黑色代表骨幹網絡,藍色代表邊緣部分。我們可以簡單地修剪掉邊緣部分,只保留骨幹網絡。這就是骨幹網絡和邊緣部分的概念。

現在,我們需要新的算法,我們需要學習骨幹網絡,我們需要在邊緣部分進行學習。在骨幹網絡內部學習,或許我們可以直接使用反向傳播、梯度下降。在邊緣部分學習,我們需要一些新的想法,讓這些單元試圖被傾聽。以及需要注意一個問題,即如何找到骨幹網絡?

有個基本的理念是,一個單元控制其傳入權重,不控制其傳出權重。每個神經元都有傳入權重和傳出權重,每個傳出權重都是另一個神經元的傳入權重。對這些分佈式 Agent 分配責任,我們分配每個 Agent 控制其傳入權重。
這是梯度,這個關於權重值的平方誤差的小偏導數,從神經元i到神經元j的權重,我以前稱它們為單元。今天我決定稱它們為神經元,無論我們談論的是人工神經元還是真實神經元,從現在開始都是人工的。
所以,如果你是在邊緣部分,根據定義就不會影響誤差,所以這個梯度總是零。在反向傳播中,根據這個梯度,偏導數來改變權重。因此,反向傳播不能用來學習這些權重,因為根據定義,導數總是零,你永遠不會改變那些權重。所以這就像是一個陷阱。如果你陷入一個陷阱,如果你最終處於邊緣部分,梯度下降將永遠不會再改變你的權重。所以這就是為什麼,我們要求它們繼續學習。我的觀點是,邊緣部分必須是更具探索性的、更活躍的、更自由地改變自己。
是的,我們可以為邊緣單元、邊緣神經元改變其傳入連接,希望下遊的某個神經元選擇聽取我們提供的信息,因此,如果一個下遊神經元在骨幹網絡之外聽取意見,這對我們沒有好處,仍然是無用的、不影響骨幹網絡。所以我們對連接到骨幹網絡感興趣,我們想提供一些東西,那些骨幹網絡會決定我們不能直接控制那些。
現在我們想使用社會隱喻,就像我們都是人,我們都會對人們是否忽視我們或對他們是否對我們所說的感興趣非常敏感。

讓我們對這個總體概念再做一些補充。我們已經提到了步長優化,設置步長。這是在骨幹網絡上學習的一個不可或缺的部分,因為我們想要保護骨幹網絡,這意味著如果骨幹網絡正在做一些有用的事情,我們必須使其步長變小,以便它們不會被改變。我們不希望骨幹網絡快速變化,而反向傳播通常會傾向於改變骨幹網絡。我們必須抵消這一點。
所以如果一個邊緣單元確實創造了一個有用的東西,它與骨幹網絡的連接通常需要兩個步驟。首先,骨幹網絡對這個新神經元相當懷疑,先給它一個較小的步長,所以即使它在做好事,權重也會保持很小。但如果發現它真的在做好事,它的步長最終會增加,然後權重會增加。就是這樣才能與骨幹網絡連接。
以上所有這些都是我的第一個觀點。
2
在未充分利用的人工神經元中增加額外變化源
為了實現深度學習(DL)和人工神經網絡(ANNs)的全部潛力,需要更多的東西。我們需要在未充分利用的人工神經元中增加額外的變化源。我們需要保護和保留那些被認為有用的、變化的神經元。

第二部分,我想談談傳統深度學習存在問題的證據,因為這正是推動新事物需求的動力。
這個新證據是什麼?這是我提到的《Nature》雜誌上的文章。而且,我們並不是第一個發現深度持續學習問題的人,上個世紀 90 年代就有災難性遺忘的問題,早期的研究也顯示了容量丟失。Ashton Adams 展示了部分學習然後學習更多的失敗。還有其他一些研究很多都在強化學習領域,但沒有人真正使用現代方法系統地、徹底地展示持續學習中可塑性喪失的問題。所以我們在這篇《Nature》雜誌的文章中做了這樣的研究。

第一點是深度學習在持續的監督學習中失去了可塑性。我們首先在 ImageNet 上展示了這一點,這是一個經典的監督學習問題,這個數據庫包含了數百萬張名詞類別的圖片,有一千個類別,每個類別有700張或更多的圖片,它被廣泛使用。

深度學習至今仍在使用,我們必須適應它,使其能夠持續學習。我想做的是持續學習,這將在強化學習和人工智能中非常有用,是基於人工智能的強化學習。
所以我們不得不改變它,我們試圖儘可能少地改變它,使其成為一個持續學習的問題。所以我們做的,實際上是這些圖片中展示的,這裏我們拿了兩個類別,我們要求網絡區分鱷魚和吉他,然後當區分差不多完成時,我們繼續說「現在忘記它,想要你區分另外兩個東西」。
這個過程會一直持續,有一千個類別,你可能會想你可以做500對,但實際上你可以做更多,因為你可以在不同的對中重用單個類別。所以你可以得到任意數量的二元分類任務,你可以看到你在第一個任務上做得有多好?
如何衡量你做得有多好?我們將通過測試集和訓練集來衡量,測量測試集中正確百分比,然後將其在多次運行中平均,改變測試集中的配對,以獲得系統的結果。在提出問題之前,我必須談一個實驗。

這些是重要的是細節。我們在任何給定時間點,只會要求它對一對名詞進行分類。我們只在開始時用第一對名詞初始化網絡一次。然後我們使用的是我們能想到的最標準的方法,實際上我們嘗試了大量的不同方法,我會向你們展示代表性的結果。
問題是,性能將如何隨著任務序列演變?它會在第一個任務上更好還是在第二個任務上更好?你在分類第一對名詞時會得到更高的百分比,還是當你繼續到第二對時,你會做得更好或更差。你可能會做得更好的原因是什麼?
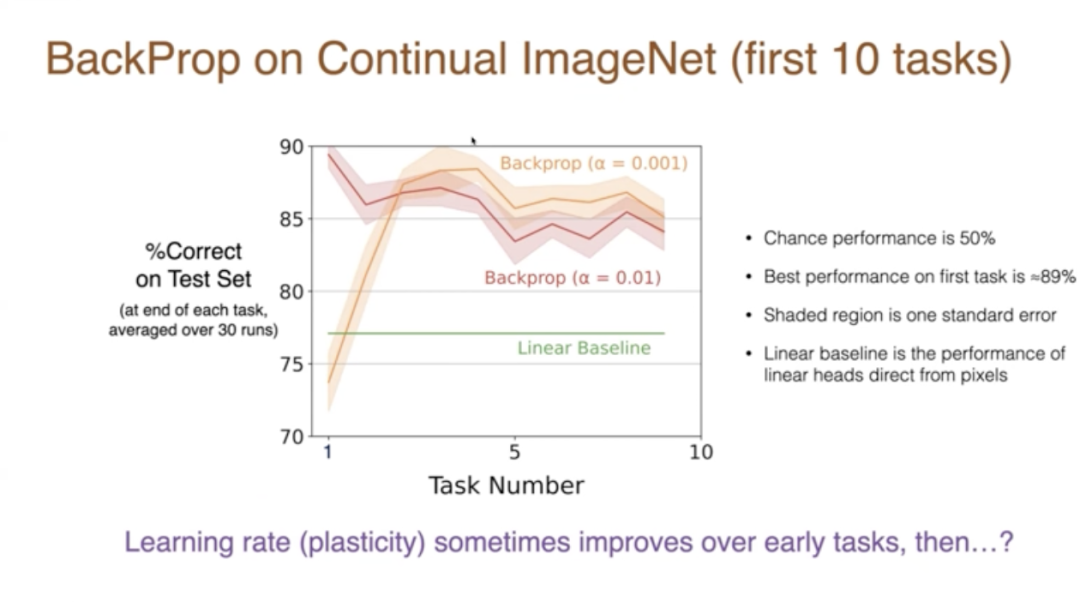
一旦你到了第500對,第500對應該和第499對非常相似。但由於你知道這部分討論的是可塑性的喪失,也許你預計實際上事情會隨著時間的推移變得更糟。所以這是在前10個任務中發生的情況,當然,結果取決於參數。

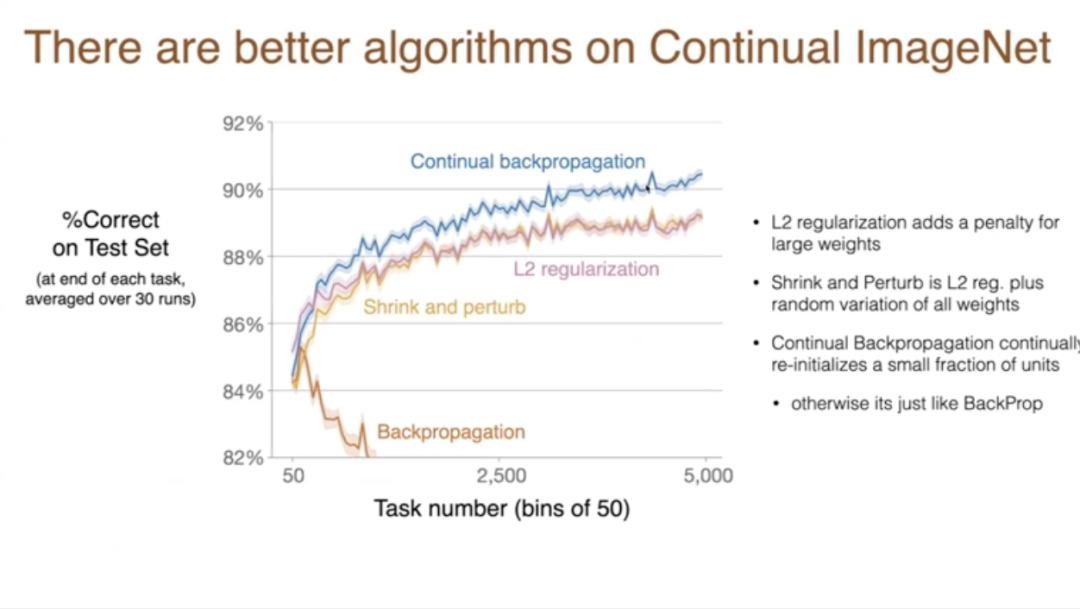
讓我們看看這些結果。在測試集上,如果步長是100,我們得到了大約89%的正確率。如果步長更小,我們會慢一些。我們最初做得沒那麼好,但實際上對於較小的步長,有更多的節省,我們確實在第二個任務、第三個任務、第四個任務上顯示了改進。那麼未來會發生什麼?我們得出什麼結論?學習率、可塑性在早期任務中有時是在提高的,但在長期內不清楚會發生什麼變化。
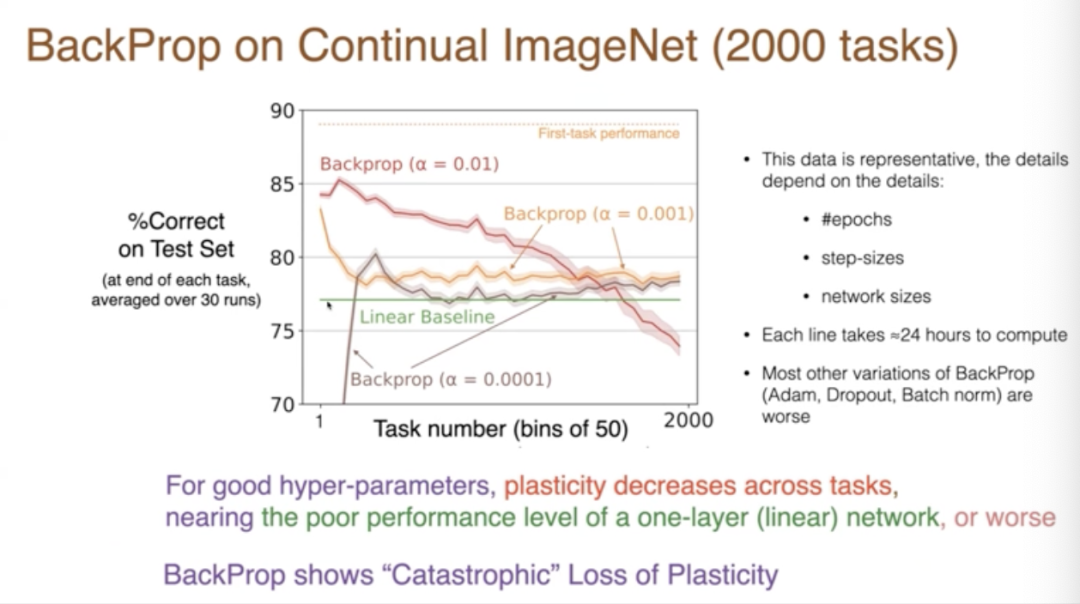
這些紅線和橙線之間只是數字略有不同,因為我們是在整個50個任務上進行分組。第一個數據點是前50個任務的平均值,但是有一個明顯的趨勢。首先,更好的步長是它一直在下降,到了第2000個任務時表現相當差,而且這種差的程度,與綠線相比,綠線是一個線性基線,基本上沒有任何深度學習,它直接從像素到類別。這就是我們在常規背景下看到的。
在某些情況下,會退化得比線性還差,在其他情況下,與線性相似。所以這基本上是隨著時間的推移,學習能力的可怕喪失。給你一個新的任務,你根本無法處理任何任務,甚至無法比線性網絡處理得更好。這項研究投入了大量的計算,大多數變體都更糟,我們做了所有變體,是一個龐大的數量。
現在你可以有更好的算法。所以這條線和之前一樣,只是比例尺有點不同。之前我們第一個類別的準確率能達到89%,現在有了這些其他的改進,我們在任務上取得了進步,不是可塑性的喪失,而是隨著時間的推移學習能力的提高。然後這種改進在很多任務中持續進行,超過5000個任務。所以這些算法中,L2是一種簡單的正則化,而在簡單的情況下,這實際上可以是一個顯著的改進。
L2正則化意味著我們對大權重進行懲罰。Shrink 和 Perturb 涉及到 L2 正則化,但也在權重中加入了隨機變化。我們發現在某些情況下,這可以有積極的效果,儘管在這個案例中不是很多,但在其他案例中是這樣的。
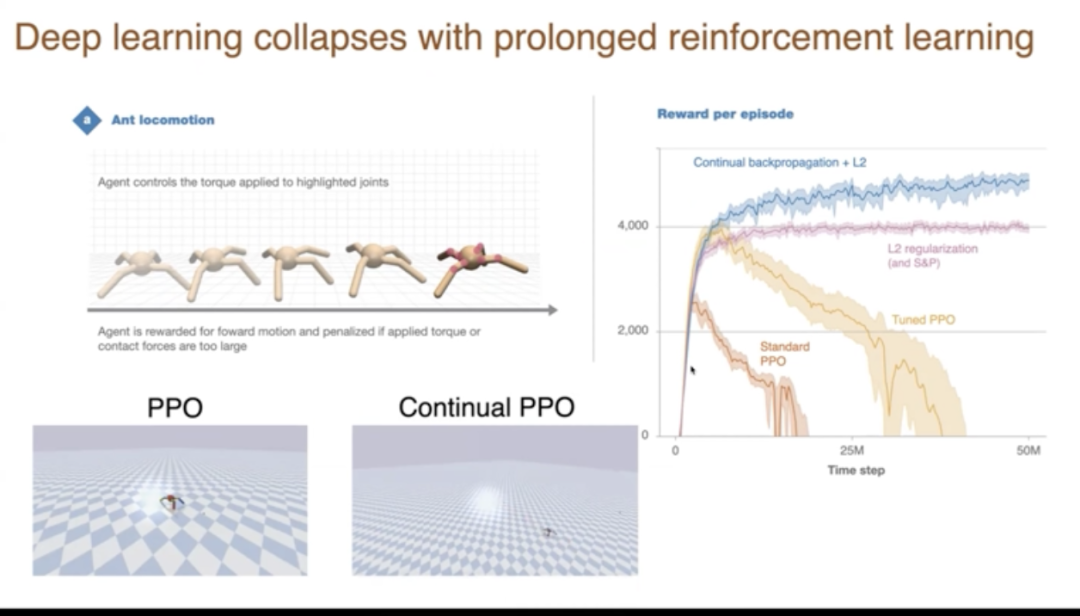
我想展示另一個結果,這是長期強化學習中深度學習的崩潰。這裏的任務是這隻螞蟻,儘管它只有四條腿,我們控制八個關節。我們試圖讓它行走時看起來像這樣。看到底部的螞蟻正以相當快的速度向前移動。它因為向前移動而得到獎勵,因為向後滑動而受到懲罰。
這是在數百萬個時間步長中的表現結果。在y軸上展示的是在一個情節中獲得的總獎勵,情節是它向前跑動的一段時間。然後在情節結束時重置。所以基本上,當我們有相當快的前進速度時,這個數字就會上升。一個標準的算法,PPO是一個強化學習算法。如果我們直接使用它,我們得到的是這樣的行為、它學得非常好,變化很高。但是,如果我們繼續訓練,它就完全停止快速行走了,它只是笨拙地移動。同一個網絡曾經能夠做得非常好,但現在它不能持續做好。實際上,它退化了,甚至跌到零以下,因為某些類型的跌倒會有懲罰。
如果調整權重,我們可以得到更長時間的更好表現。但如果我們繼續進行更長時間的訓練,同樣的事情也會發生。你可能會問,這不是一個大問題嗎?為什麼人們以前不知道呢?答案是,人們有時確實看到了,但他們通常不會運行那麼久。他們運行直到它運行得相當好,然後他們就停止了。如果你在這裏結束這個實驗,它看起來就像它運行得非常好。只有當你堅持,我寫了沒有數百萬的更多時間步長,但你會看到它退化了。
注意其他線條,LT正則化沒有退化,它是平線,而持續反向傳播可能隨著時間的推移做得稍微好一點。那麼持續反向傳播是什麼?這個短語是隨機梯度下降,反向傳播,但有選擇性地重新初始化。反向傳播涉及在時間開始時的初始化,在所有單元中製作小的隨機權重,在持續反向傳播中,我們將繼續在單元中設置小的隨機權重、重新初始化。
實際上,重新初始化和初始化算法是一樣的。但重新初始化將是選擇性的。我們不會對骨幹網絡上的單元進行重新初始化。我們將對未使用的單元進行重新初始化。因此,我們將根據它們的效用對神經元進行排名,然後只重新初始化那些最不有用的幾個。
3
賦予每個神經元獨立目標
這是效用更新的方程。所以這是單元、神經元i的效用,新的一個是Eta,Eta是一個像0.9這樣的參數。所以我們淡化舊的效用,加入這個數量。基本上效用變成了這個數量的平均值或平均值。這個數量是神經元活動的絕對值。所以你只有活動才有高效用,而且你的傳出權重必須在絕對值上很大。那是從你的單元i到單元K的所有K的權重,你擁有權重的,如果我們有大的傳出權重,所以這些是傳出權重,絕對值大的傳出權重在某些時候你的活動是衡量你對網絡影響程度的一個指標。當然,這沒有考慮到接收神經元的效用。也許這不是效用完美的概念,但這是我們使用的,這足以獲得那些好的結果,這是一個需要進一步實驗的領域。
所以一種方式是,神經元重新初始化,直到其他神經元從它們那裡覺醒。它們尋求關注,它們尋求貢獻,它們尋求讓別人聽它們的,發現它們有用。

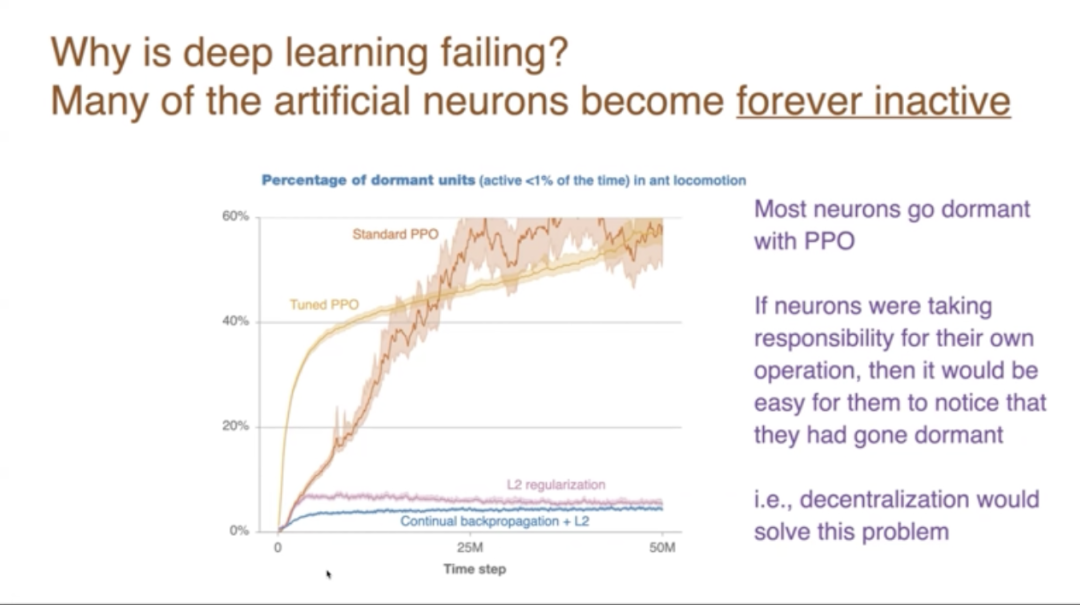
為什麼這種失敗會發生?很大程度上是我多次提到的,神經元變得死亡,它們退出了骨幹網絡,然後它們被困在骨幹網絡之外,無法貢獻。
所以這個圖表顯示的是——這是在螞蟻運動的強化學習任務上。隨著時間的推移,我們測量活躍時間少於1%的單元數量。所以這些是應該活躍的休眠單元,但它們只是普通的反向傳播中的休眠單元。值得注意的是,在持續反向傳播中,它們再次變得活躍。那些休眠的單元被選中進行重新初始化。所以它們再次獲得了變化。
但在反向傳播中,有這些休眠單元是不好的,因為它們沒有貢獻。所以在這裏,超過一半的單元最終變得休眠,而持續反向傳播和正則化,這兩種方法阻止了大量單元變得休眠。當神經元要為自己的運作負責時,它們自然會注意到自己已經休眠,然後在某種意義上重新喚醒自己。所以採取這種去中心化的視角將解決這個問題,就像持續反向傳播至少部分解決了這個問題一樣。
以上我的主要觀點。另外,我的同事們在阿爾伯塔大學進行的另一項新工作,是關於流算法的研究。圖片中的藍線,這是在各種標準深度強化學習任務上的性能數字,Mujoko和其他一些東西。所以每一個藍線代表一個問題,性能通過條形圖顯示,藍線是新算法的性能。藍線左邊的這些東西,這些是經典的強化學習算法,非深度算法,你會在強化學習的教科書中找到的流算法。
與這個流設置中的其他算法相比,這些算法表現得不太好,所以這被稱為流障礙。問題在於,如果我們採用自然的強化算法,它們在流式在線設置中表現得不太好。新的結果是,藍線與右邊的算法競爭,這些是基於重播的深度學習方法,保存了很多東西。所以現在我們可以進行流式深度強化學習,它奏效了。我認為這是一個非常重要的結果。並不是說它總是比一切都好,或者完全競爭,這取決於細節。但這是流方法性能的顯著提升,由 Muhammad 和他的一些同事完成的。
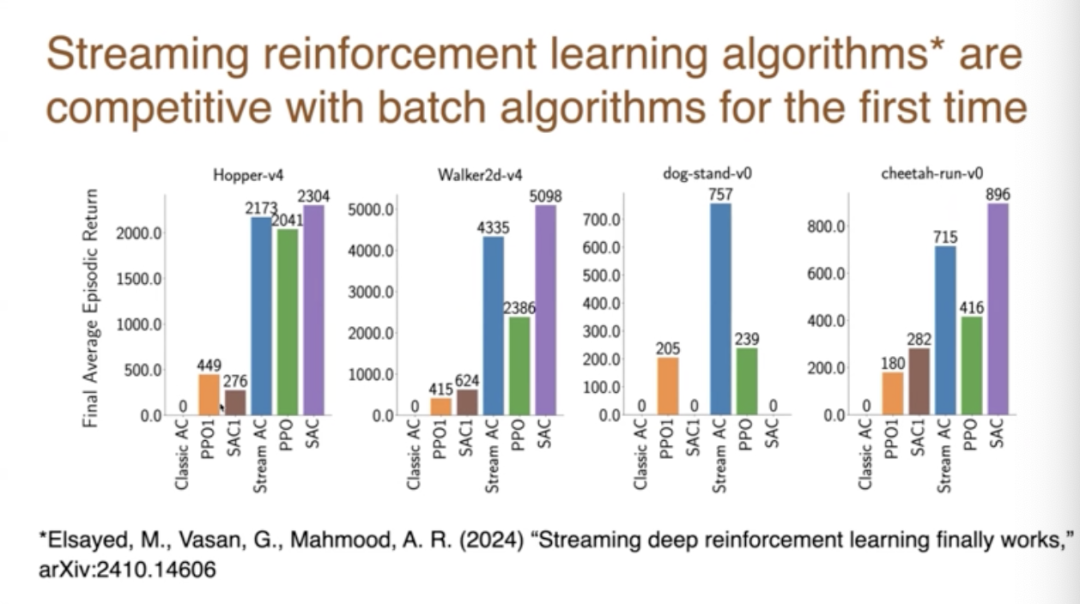
我之所以會提到這項工作,是因為我認為它和剛才講的內容特別相關,它也採取了一種去中心化的視角。所以我也將它視為支持去中心化神經網絡論點的一部分。

以上大致是我想講的內容。我的結論是,今天的深度學習方法並不完善,我們需要更多的東西。它們在所有這些方面都失敗了,我們今天已經展示了其中的一些,所以為了實現全部潛力,我們需要更多的東西。基於持續的背景,需要嘗試各種方法,然後我們需要保留好的那些,就是擁有一個去中心化網絡的想法。雖然這個聯繫還有點弱,但它強烈建議我們應該看看這些基於去中心化的算法,以及神經元的目標是讓其他神經元聽它們的,儘管我還不能證明這一點。

DAI2024 共分為五大主題、七個session,內容涉及多智能體系統、強化學習、深度學習、博弈論、AI Agents 和 LLM 推理等多個領域,展示了來自 NeurIPS、ICLR、ICML、AAAI、AAMAS、CoRL 等頂級會議期刊的高質量學術成果。此外,大會還組織了多個學術沙龍,深入探討具身智能、博弈論、開放環境中的多智能體強化學習以及大語言模型驅動的代碼智能體等前沿熱點話題。AI 科技評論將持續關注。





















