一張圖生成高質量廣視野3D場景,還可控制攝像軌跡
Wonderland團隊 投稿
量子位 | 公眾號 QbitAI
只需一張圖,就能生成高質量、廣範圍的3D場景!
泰迪熊、花園、山穀都從平面圖片變成了彷彿觸手可及的立體物品。

這就是來自多倫多大學、Snap和UCLA的研究團隊推出的全新模型——Wonderland。

他們首次證明,三維重建模型可以有效地建立在擴散模型的潛在空間上,進而實現高效的三維場景生成,是單視圖3D場景生成領域的一次突破性進展。
具體來說,團隊引入了一種大規模重建模型,該模型使用影片擴散模型中的潛在信息,以前饋方式預測場景的3D表示(3DGS)。
影片擴散模型可以精確地按照指定的相機軌跡創建影片,生成包含多視角信息的潛在特徵,同時保持三維一致性。
三維重建模型則通過漸進式訓練策略在影片潛在空間進行訓練,高效地生成高質量、大範圍和通用的三維場景。

這樣一來,機器就可以高效地模擬人類從單張圖像中感知並想像三維世界的能力了。
技術突破:從單張圖像到三維世界的關鍵創新
傳統的3D重建技術往往依賴於多視角數據或逐個場景(per-scene)的優化,且在處理背景和不可見區域時容易失真。
為解決這些問題,Wonderland創新性地結合影片生成模型和大規模3D重建模型,實現了高效高質量的大規模3D場景生成:
-
向影片擴散模型中嵌入3D意識
通過向影片擴散模型中引入相機位姿控制,Wonderland在影片latent空間中嵌入了場景的多視角信息,並能保證3D一致性。影片生成模型在相機運動軌跡的精準控制下,將單張圖像擴展為包含豐富空間關係的多視角影片。
-
雙分支相機控制機制
利用ControlNet和LoRA模塊,Wonderland實現了在影片生成過程中對於豐富的相機視角變化的精確控制,顯著提升了多視角生成的影片質量、幾何一致性和靜態特徵。
-
大規模latent-based 3D重建模型(LaLRM)
Wonderland創新地引入了3D重建模型LaLRM,利用影片生成模型生成的latent直接重構3D場景(feed-forward reconstruction)。重建模型的訓練採用了高效的逐步訓練策略,將影片latent空間中的信息轉化為3D高斯點分佈(3D Gaussian Splatting, 3DGS),顯著降低了內存需求和重建時間成本。憑藉這種設計,LaLRM能夠有效地將生成和重建任務對齊,同時在圖像空間與三維空間之間建立了橋樑,實現了更加高效且一致的廣闊3D場景構建。
效果展示:影片生成
基於單張圖和camera condition,實現影片生成的精準視角控制:
Input Image and Camera Trajectory


Input Image and Camera Trajectory


Camera-guided影片生成模型可以精確地遵循軌跡的條件,生成3D-geometry一致的高質量影片,並具有很強的泛化性,可以遵循各種複雜的軌跡,並適用於各種風格的輸入圖片。
一起來看看更多的例子:
不同的輸入圖片,同樣的三條相機軌跡,生成的影片:





給定輸入圖片和多條相機軌跡,生成影片可以深度地探索場景:


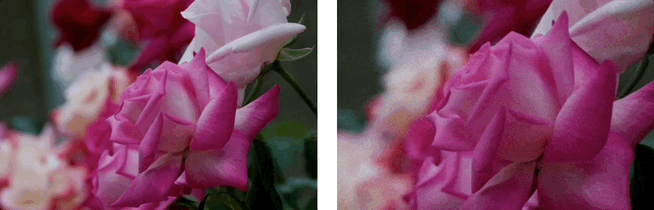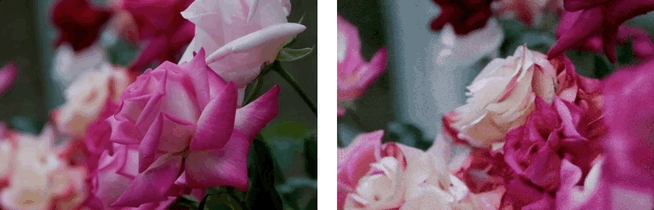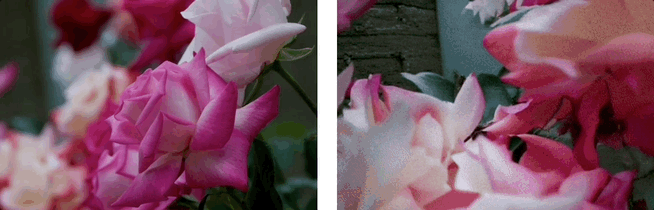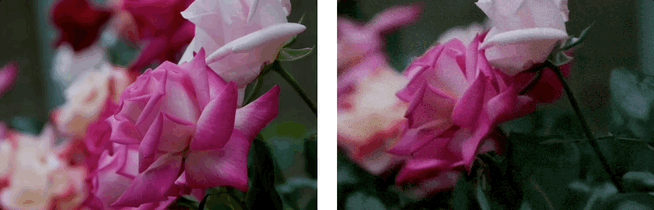


效果展示:3D場景生成
基於單張圖,利用LaLRM, Wonderland 可以生成高質量的、廣闊的3D場景:





基於單張圖和多條相機軌跡,Wonderland 可以深度探索和生成高質量的、廣闊的3D場景:





卓越性能:在視覺質量和生成效率等多個維度上表現卓越
Wonderland的主要特點在於其精確的視角控制、卓越的場景生成質量、生成的高效性和廣泛的適用性。
實驗結果顯示,該模型在多個數據集上的表現超越現有方法,包括影片生成的視角控制、影片生成的視覺質量、3D重建的幾何一致性和渲染的圖像質量、以及端到端的生成速度均取得了優異的表現:
-
雙分支相機條件策略:通過引入雙分支相機條件控制策略,影片擴散模型能夠生成3D-geometry一致的多視圖場景捕捉,且相較於現有方法達到了更精確的姿態控制。
-
Zero-shot 3D 場景生成:在單圖像輸入的前提下,Wonderland可進行高效的3D場景前向重建,在多個基準數據集(例如RealEstate10K、DL3DV 和Tanks-and-Temples)上的3D場景重建質量均優於現有方法。
-
廣覆蓋場景生成能力: 與過去的3D 前向重建通常受限於小視角範圍或者物體級別的重建不同,Wonderland能夠高效生成廣範圍的複雜場景。其生成的3D場景不僅具備高度的幾何一致性,還具有很強的泛化性,能處理out-of-domain的場景。
-
超高效率: 在單張圖像輸入的問題設定下,利用單張A100,Wonderland僅需約5分鐘即可生成完整的3D場景。這一速度相比需要16分鐘的Cat3D提升了3.2倍,相較需要3小時的ZeroNVS更是提升了36倍。
應用場景:影片和3D場景內容創作的新工具
Wonderland的出現為影片和3D場景的創作提供了一種嶄新的解決方案。
在建築設計、虛擬現實、影視特效以及遊戲開發等領域,該技術展現了廣闊的應用潛力。
通過其精準的影片位姿控制和具備廣視角、高清晰度的3D場景生成能力,Wonderland能夠滿足複雜場景中對高質量內容的需求,為創作者帶來更多可能性。
儘管模型表現優異,Wonderland研發團隊深知仍有許多值得提升和探索的方向。
例如,進一步優化對動態場景的適配能力、提升對真實場景細節的還原度等,都是未來努力的重點。
希望通過不斷改進和完善,讓這一研發思路不僅推動單視圖3D場景生成技術的進步,也能為影片生成與3D技術在實際應用中的廣泛普及貢獻力量。
論文: https://arxiv.org/abs/2412.12091
項目主頁:https://snap-research.github.io/wonderland/