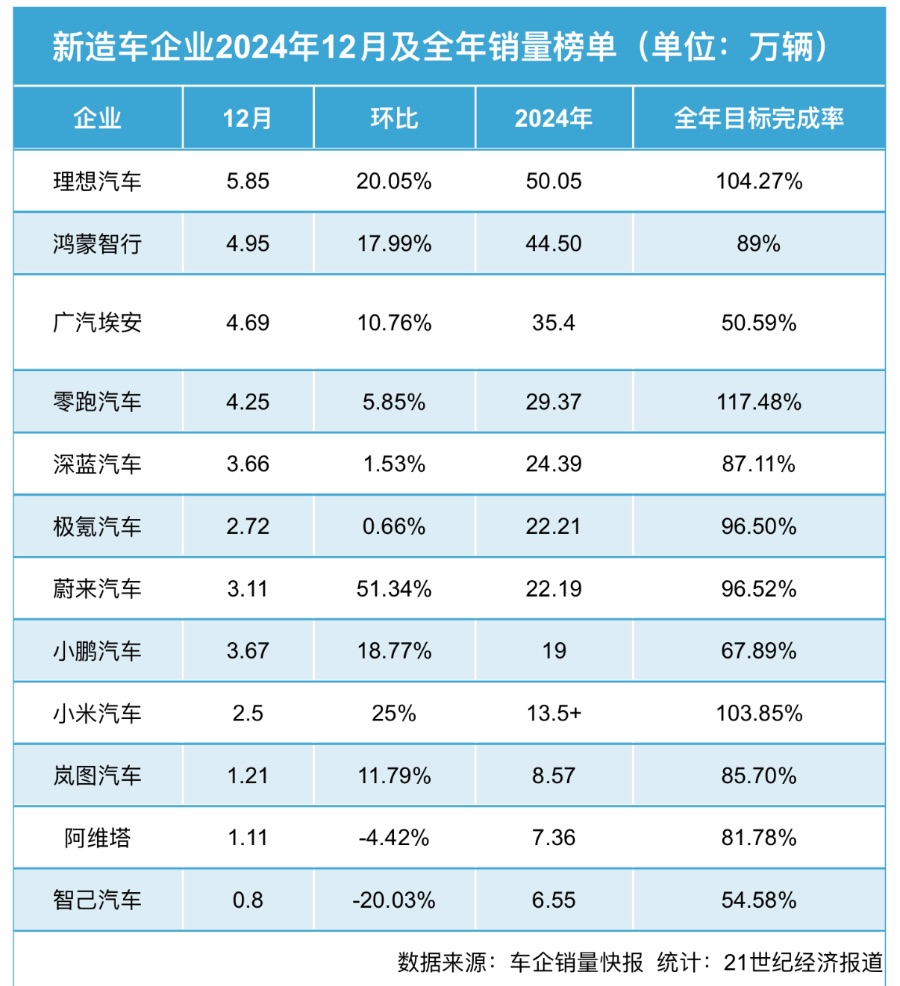
「訓練數據抄襲」:DeepSeek 動了誰的乳酪?
有的讀者指出:DeepSeek V3 有「訓練數據抄襲」的問題。
證據呢?這模型有時候會產生奇怪的幻覺,比如自稱「GPT-4」,甚至連所講的笑話都與 GPT-4 高度雷同。上網衝浪了會兒,發現這事情的討論還不小。
於是,就有了這篇:我會從技術和倫理的角度,來談談這個事情。
大模型的「奇怪幻覺」
從技術角度來說,這種「幻覺」現象,很可能是訓練數據受到了汙染。
大型語言模型 (LLM) 的訓練過程,本質上是對海量文本數據(即「語料」)進行學習和模仿。這些語料通常來源於互聯網的公開信息,涵蓋新聞、文章、博客、論壇等各種文本。模型通過學習這些語料中的語言模式、邏輯結構和知識信息,進而獲得生成類似文本的能力。
然而,如果在訓練數據中混入了大量來自某個特定模型(例如 GPT-4)的輸出內容,新模型就可能學習到該模型的「說話方式」甚至「思維模式」,從而在特定情況下表現出與該模型類似的特徵,產生所謂的「幻覺」。
DeepSeek V3 很可能就遭遇了這種情況。互聯網上充斥著大量由 GPT-4 生成的文本內容,這些內容或許在無意間被當作「語料」收錄進了 DeepSeek V3 的訓練數據中,最終導致其出現「幻覺」。其實 DeepSeek 並非個例,Google 的 Gemini 此前也曾出現過類似問題,會稱自己是「問心一言」。(當然,可能還有其他原因)

但我的重點不是這個,而是由訓練語料,引來的一個行業問題:未來如何更好地對AI內容進行版權確定和使用。畢竟,現有的版權法難以完全適用於AI生成的內容,其「獨創性」在法律上仍存爭議,傳統內容創造者的利益也會受到影響:《紐約時報》起訴OpenAI和微軟等訴訟反映了這種焦慮。
別的不知道,但在這個過程中,我這樣無良自媒體的「乳酪」,肯定會無聲消融。
「Created by Humans」
Scribd 聯合創始人 Trip Adler 的新項目「Created by Humans」做了一個嘗試:這是一個歐美版的「視覺中國」,讓創作者把內容的版權賣給各 AI 公司。方法類似當年 Spotify 解決音樂盜版問題的思路:通過構建新的商業模式來平衡各方利益。
當然,「Created by Humans」能否取得成功,還有待時間的檢驗。以及,該平台目前主要針對的是圖書版權,而 AI 模型的訓練數據還包括圖片、音頻、影片等多種類型的內容。如何將這個模式擴展到其他類型的內容,也是一個需要解決的問題。
儘管如此,「Created by Humans」的出現仍然具有重要的意義。它為我們提供了一種可能:讓大家公平交易食物,而不是爭奪口糧。
規則與乳酪
目前來說,AI 對「語料」的使用,正處於無人監管的「曠野」;而內容作者也缺乏話語權和議價能力,只能眼看著自己的「乳酪」被蠶食。
能頭疼的是,對於 AI 版權,我們壓根就沒形成基本共識。AI 的「學習」與人類的「借鑒」之間的邊界在哪裡?「語料」的擁有權和使用權該如何界定?AI 生成內容的版權又該歸屬於誰?
在這場不對稱的較量中,創作者岌岌可危:博弈,才剛剛開始。