深度學習工作:從追求 SoTA 到揭示新現象
作者丨黃哲威 hzwer@知乎(已授權)
來源丨https://zhuanlan.zhihu.com/p/14170281797
編輯丨極市平台
導讀
本文主要討論了從追求模型 SoTA 到揭示新現象的轉變。通過幾個例子,包括ACNet到RepVGG的發展,RIFE插幀、Film插幀,以及OpenAI的近期工作,闡述了這種轉變的重要性。
最近大家對於前沿工作的討論,常常出現兩極分化
比如 DiT,看到很多人說是灌水,研究生實驗報告,Sora 以後有人又說「打臉」
比如說 OpenAI-o3,有答主說 「這是真正的智能爆炸,斷崖式提升」,然後評論區說 「下次換個話術」
身邊的故事,近期審了不少論文,發現大家對於宣稱 SoTA 的工作越來越嚴苛了。往年那種先 SoTA 再故事的論文,眼看著被連環拒。作者喊著性能無敵,審稿人 borderline reject
想了一些東西,也對 論文寫作指南(https://github.com/hzwer/WritingAIPaper) 做了點補充
ACNet 到 RepVGG 的現象上升
聊個大佬朋友的例子, @丁霄漢 說 RepVGG 其實可以叫 ACNetv2
簡單來說 ACNet 就是訓練的時候三個卷積核,推理的時候合成一個
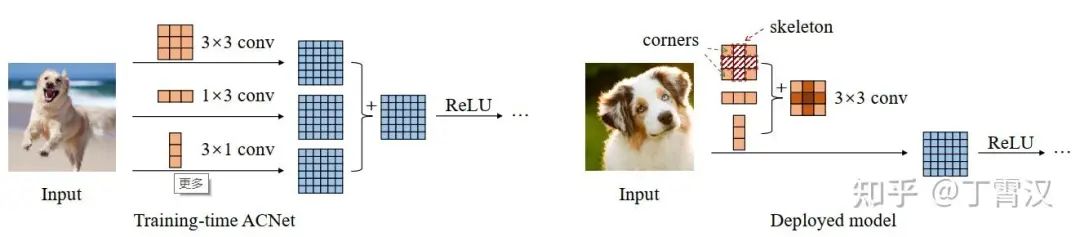
ACNet 在 ICCV19 投稿得分還是有正有負被撈起來,目前 800+ 引用說明後續影響力很不錯
我個人覺得並不是當年的審稿人水平太差沒有看出它的創新性,而是 ACNet 的創新性在丁博的後續工作中有廣泛提升
因為 RepVGG 抽像了一個新概念「結構重參數化」,把 ACNet 中不好說清楚動機的設計方式變成 「構造一系列結構(一般用於訓練),並將其參數等價轉換為另一組參數(一般用於推理),從而將這一系列結構等價轉換為另一系列結構」
然後同時又報告了一個現象,即 VGG 式的網絡,只要有並行的恒等和 1×1 卷積分支,就能訓出 ResNet 相當的性能,推理時還跟原來的 VGG 結構一樣
重參數化自此成為手工設計 CNN 的一類重要操作
論文刷點是一部分,更高的性能同時揭露新的現象,才是學術的本質
王婆賣瓜 – RIFE 插幀
賣個自己論文的例子 – RIFE 實時影片插幀模型(https://www.zhihu.com/question/516128811/answer/2557922020)
我近一兩年才逐漸意識到自己陰差陽錯做了一篇還不錯的論文,目前還不知道怎麼達到更高水平,希望以此為例傳達一些經驗教訓
研究初衷是當時業界流行的插幀算法 DAIN 速度比較慢,就想設計個規整的 CNN 網絡來做一個實時插幀模型
一開始投稿也是主要突出 SoTA 性能,但是審稿人買賬的不多,特別是輕量化模型並不是一個討喜的研究話題,被拒好幾次
雖然我們認為某個指標提高就是模型核心競爭力的體現,但是全世界大概只有幾個小同行共識,而且提高一點性能,本身不為領域帶來什麼新的知識
於是我們重寫了文章,更多的加入了新的發現,於是審稿人和讀者可以各自尋找心中的哈姆雷特
把先前一些模型的誤差解釋為光流逆轉時忽略了物體空間移動,所以我們有更強的動機在輕量化網絡中端到端估計中間幀光流
對於為什麼要做光流蒸餾,先指出輸入中間幀信息為「特權」的模型會有高得多的性能
多倍插幀,我們發現把目標時間 T 輸入進網絡是可以實現控制任意時刻插幀的,而且訓練之後還可以放入梯度式的時間編碼實現場景融合或果凍效應模擬
將光流和融合權重先一起預測,可以用來做其它模態的插幀
性能上我們也改成強調整體設計帶來的多倍插幀場景的效果提升等等
這樣自己都不用強調,審稿人每個人都會說這篇論文提出的方法性能很好
我們希望讀者覺得論文更有讀的價值,現在看引用也真的來自很多不同的方向,比如有 20+ 篇做果凍效應的引用
為什麼說 「陰差陽錯」 呢,因為很多 idea 其實是多次 rebuttal 以後想的。比如說有兩次審稿人批評不能做任意時刻插幀,我就回覆說這個簡單,把目標時間 T 輸入就行了嘛。審稿人說,沒做實驗你說個錘子,一做才發現效果比預期還好
水平所限,當年其實還是沒有把這篇論文寫的很好,寫這篇總結是希望下次能做的更優美
不用刷 SoTA 的 Film 插幀
帶著這樣的視角,看看為什麼有的論文在很卷的賽道也能中得順利,發在 ECCV22 的插幀論文 Film: Frame interpolation for large motion(https://github.com/google-research/frame-interpolation),Fitsum Reda 大佬作品

看宣稱的論文貢獻:
我們將幀插值的範圍擴展到一個新穎的近重覆照片插值應用,為社區開闢了一個新的探索空間。
– 我們調整了一個共享權重的多尺度特徵提取器,並提出了一個尺度無關的雙向運動估計器,使用常規訓練幀來很好地處理小範圍和大範圍的運動
– 我們採用基於Gram矩陣的損失函數來修復由大場景運動引起的大範圍遮擋,從而生成清晰且令人滿意的幀
– 我們提出了一個統一、單階段的架構,以簡化訓練過程,並消除對額外光流或深度網絡的依賴
很明顯地有一些新東西,首先是開闢新的研究範圍,找到一些以往算法都會掛掉的例子
然後圍繞這個問題構建整個論文,提出了一系列設計,包括結構和損失函數
和別人的對比是次要的,在以往 benchmark 上和 SoTA 差不多可比就可以了,突出一些關注場景的性能
近期熱門的 OpenAI 工作
OpenAI 發的一系列東西,如果我們從做新現象的角度去審視,就能知道為什麼它們是好東西
比如說 Sora 現在不如可靈,那它是不是價值顯著下降?
我覺得可靈以及很多國產影片生成大模型的廣泛成功,其實說明了 Sora 的重要性,即它展示的現像是別人可以複現的,通過 DiT 來高質量長時長的可控影片生成,甚至於它的失敗例子其實都是很有意思的實驗現象
GPT4 / o1 / o3,每一個都展示了前代模型沒有的新現象,這是它們足以吸引諸多研究者的原因
如果我第一次看到 ChatGPT,我會很疑惑怎麼會有這樣交互水平的對話模型,它是不是在時不時聯網 + 人工干預 + 複雜的 pipeline 設計來產出內容
然後當我們在小模型複現了一些流程以後,會驚訝於一個 7B 左右大小的模型真的能日常對話
GPT4 一開始最吸引我的,就是它解決我出的算法題的水平。雖然它在這方面不如很多經過訓練的初中生,但是比起其它胡說八道的模型真的強了很多
o1 / o3 是思維鏈了更擴展版本,探索了用更多的推理開銷換取智能的可能性
具體就不贅述了,總之我希望社區看這些工作的時候,不要過多討論 xxx 是不是通往 AGI(通用人工智能)的路子,以及 xxx 的本質是不是就是 xxx,而是分享我們能從新方法看到什麼新現象
新的現象才孕育著新的可能