ViT作者飛機上也要讀的改進版Transformer論文,花2個小時詳細批註解讀分享出來
夢晨 發自 凹非寺
量子位 | 公眾號 QbitAI
ViT核心作者Lucas Beyer,長文分析了一篇改進Transformer架構的論文,引起推薦圍觀。
他前不久從Google跳槽到OpenAI,這次是在飛機上閱讀論文並寫下了分析。
這篇論文被他簡寫為DiffTranformer,不過不是Sora底層架構的那個Diffusion Transformer,而是不久前來自微軟的Differencial Transformer。
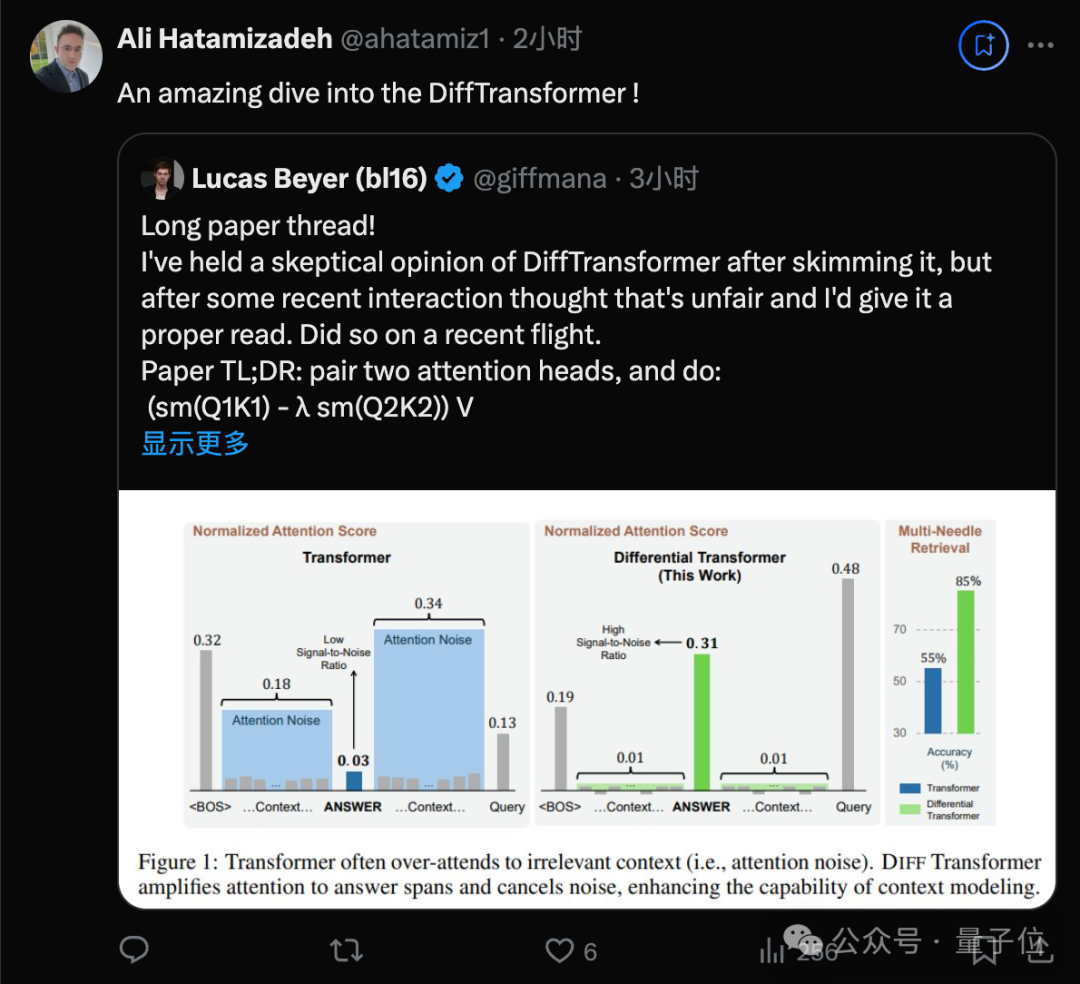
論文中介紹,整體思路類似差分放大電路或降噪耳機,用兩個信號的差值來濾除共模噪聲,解決Transformer模型信噪比低的問題。
這篇論文發佈時引起大量關注,但也面對一些質疑,在彈幕版alphaXiv上作者與讀者進行了很多討論。

Beyer起初也對這篇文章持保留態度,覺得「難道MHA中的兩個注意力頭不能學習到這些嗎?」。
但經過近期和同行的一些互動,覺得不應該輕易下定論,重新看了一遍論文後,他改變了看法
我的最初印象被團隊的實驗徹底打破了,他們的實驗非常公平和謹慎。
此外還有一個彩蛋:
大佬通常會用坐飛機的時間來打4把Dota 2遊戲快速模式。
現在寫這個帖子也不能當論文評審工作寫進簡曆,是純純的貢獻個人時間了,以後也不會常寫。
總之先給大佬點讚。
大佬解讀熱點論文
Beyer評價這篇論文的核心創新非常simple和nice,可以用一句話概括。
將兩個注意力頭配對,然後執行(softmax(Q1K1) – λ*softmax(Q2K2)) V,其中λ是一個可學習的標量。
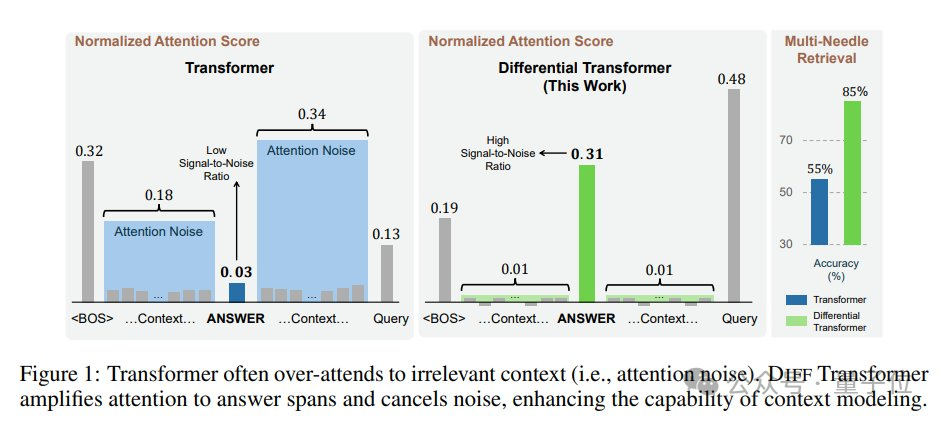
他認為這項研究的動機非常充分:隨著上下文變長,(微小的)對不相關token的注意力之和可能超過對少數相關token的注意力,從而淹沒它們。
這一洞見表明,隨著輸入長度的增加,經典Transformer可能越來越難以捕捉到關鍵信息。DIFF Transformer試圖解決這一問題。
但他仍不確定對於訓練充分的模型來說這是個多大的問題,希望在DIFF Transformer論文中有一些關於attention分佈/熵的圖表,以實際證明這個插圖的合理性。
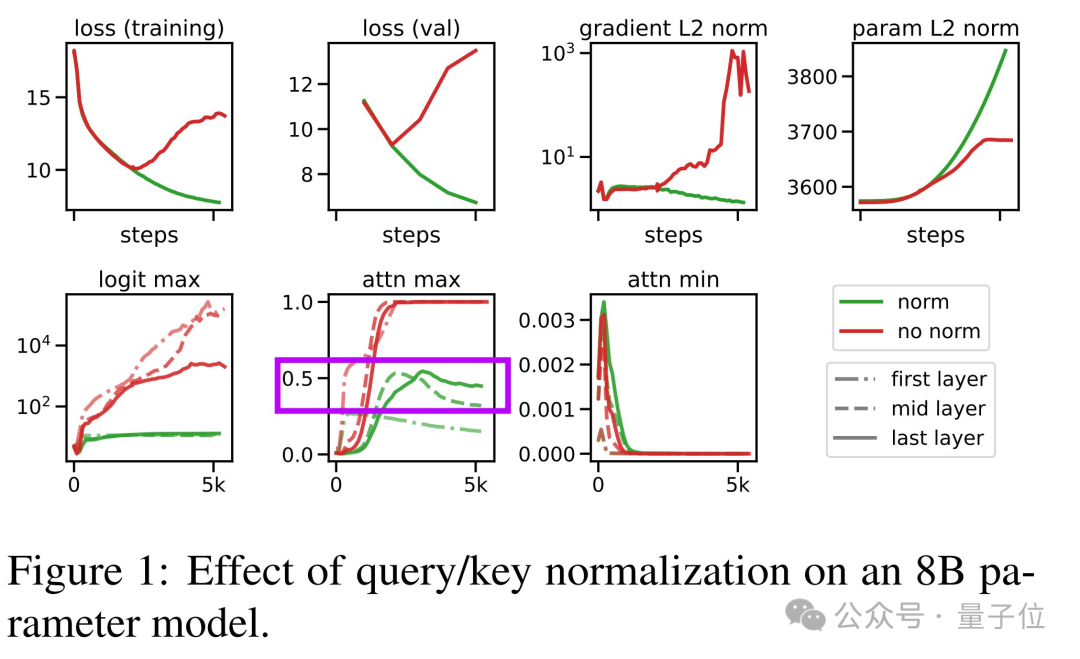
接下來,他指出了幾個容易被忽視的細節:
-
與Figure1不同,DiffAttn實際上並沒有對差值重新歸一化。那麼它究竟如何放大」相關」的分數呢?
Beyer建議論文中能提供更多實際訓練的DIFF Transformer的分析圖表。

-
λ的計算相當複雜,涉及兩個可學習的指數函數之差,加上一些基線λ_init,在早期的層是0.1,後面又是0.8。
Beyer認為λ不一定需要是正值,並建議提供更多對可學習λ參數的分析。
-
每個注意力頭的輸出都經過了層歸一化並乘以(1-λ_init),然後再concat並乘以WO,這裏也需要更多圖表來證明。

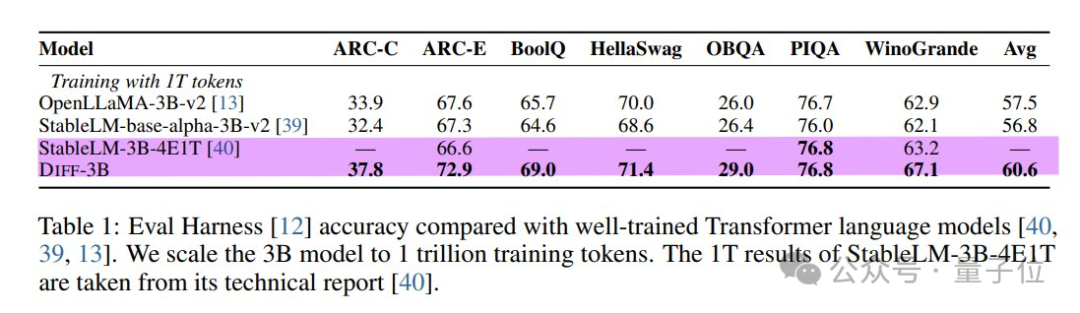
接下來看論文中大量的實驗。研究者基本上分叉了了StableLM-3B-4E1T,稱之為Diff-3B,作為基線模型進行比較。
可惜的是,基線模型只在其中3個數據集上報告了結果,其中2個Diff-3B的表現都相當好。
Beyer懷疑這個StableLM-3B是否真的是一個強基線。
在參數量和token數的縮放曲線上,DIFF Transformer乍一看很有前景。但仔細觀察後,Beyer提出了兩點質疑:
-
縮放曲線明顯分為兩組,在它們之間畫一條線有點牽強。查看附錄可知,研究者為較大的兩個模型降低了學習率。這是否意味著他們遇到了不穩定性問題?
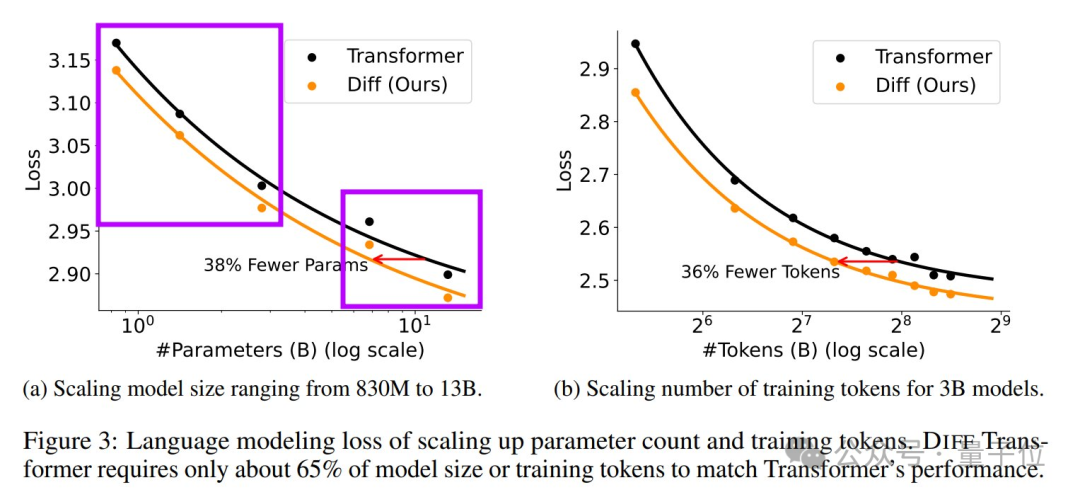
-
每次實驗只用了10B個token訓練,這個數量非常小。Beyer理解其中的計算資源限制,但仍然感到有點不安。

這些實驗表明,在相同大小的情況下,DIFF Transformer性能會更好一些,並且訓練時間相同。
然而,它的的推理速度也會慢一些(慢5-10%)。
Beyer提出最好能看到以計算量或實際時間為橫軸的縮放曲線。
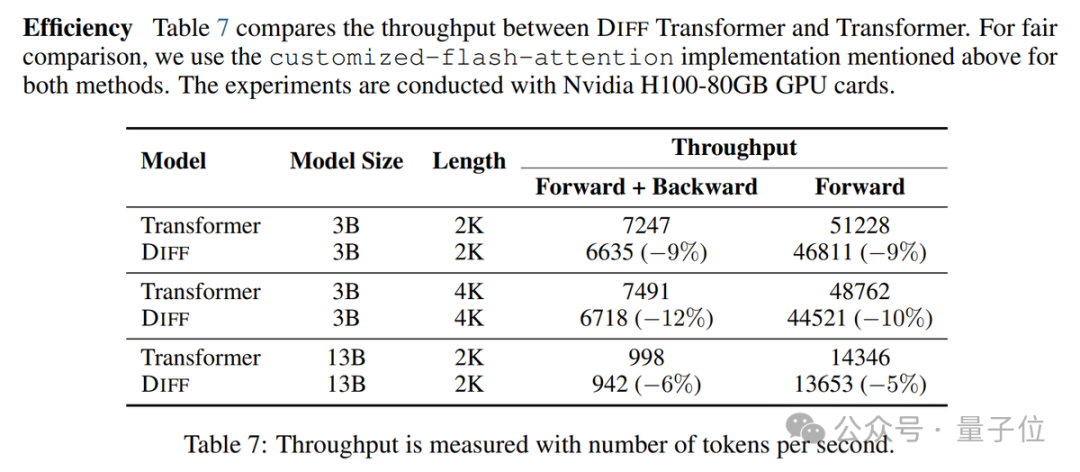
在長文本評測和對輸入樣本順序的魯棒性方面,DIFF Transformer表現出了明顯的優勢。
特別是在上下文學習的魯棒性實驗中,DIFF Transformer在不同的樣本排列順序下,性能方差遠小於經典Transformer。
這表明它更不容易被輸入的細微變化擾亂,而經典Transformer容易受到樣本順序的影響,在最好和最壞情況下表現相差很大。
總的來說,Beyer對這篇論文的看法有所改觀:
研究者的實驗非常全面和謹慎,的確展現了DIFF Transformer比單純的」兩個注意力頭相減」更多的潛力。
這項工作展現了一些有前景的火花。它在其他人的訓練任務中能否很好地複現、或帶來幫助,還有待進一步觀察。
Lucas Beyer是誰
12月初,Lucas Beyer與Xiaohua Zhai、Alexander Kolesnikov集體從Google被挖到OpenAI。
他們曾共同提出Vision Transformer,開創了Transformer在CV領域應用的先河。

據他個人官網中介紹,他在比利時長大,曾夢想製作電子遊戲以及從事AI研究。
他在德國亞琛工業大學學習機械工程,並在那裡獲得了機器人感知和計算機視覺博士學位,2018年加入Google。

除了這次長文分析DIFF Transformer之外,他還經常對新研究發表一些短的評論,比如最近火爆的DeepSeek v3,他也提出自己的建議。
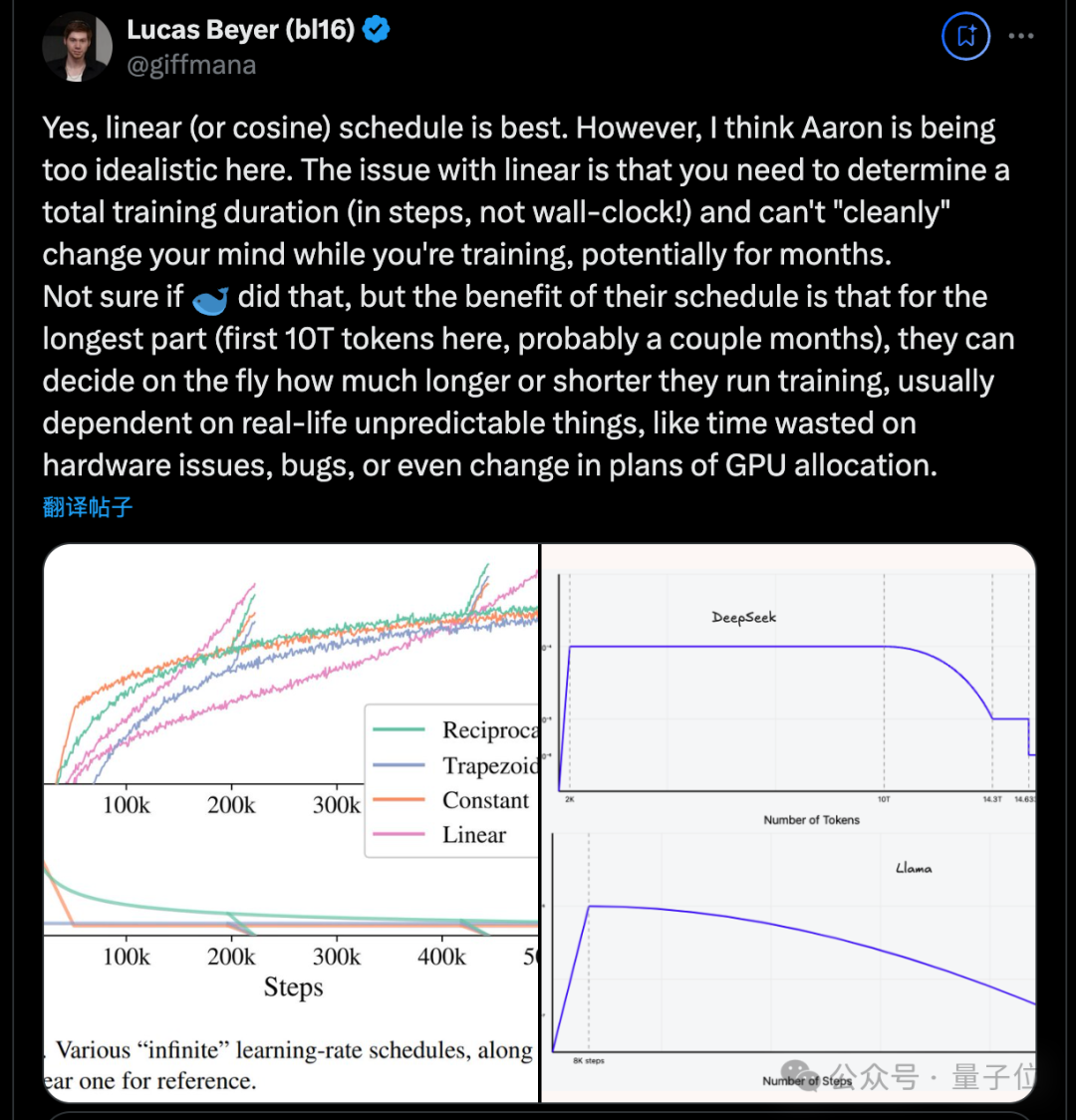
總之是一位非常值得關注的學者。
DIFF Transformer論文:
https://arxiv.org/abs/2410.05258
參考鏈接:
[1]https://x.com/giffmana/status/1873869654252544079



















