微軟論文意外「走光」,OpenAI參數全泄密,GPT-4o僅200B,o1 300B
穿越重重迷霧,OpenAI模型參數終被揭開!一份來自微軟華盛頓大學醫療論文,意外曝光了GPT-4、GPT-4o、o1系列模型參數。讓所有人震驚不已的是,GPT-4o mini僅8B。
誰能想到,微軟在一篇醫學領域的論文里,竟然把OpenAI模型的參數全「曝光」了!
- GPT-4參數約1.76萬億
- GPT-4o參數約2000億
- GPT-4o mini參數約80億
- o1-preview參數約3000億
- o1-mini參數約1000億
- Claude 3.5 Sonnet參數約1750億
 研究人員:參數均為估算值
研究人員:參數均為估算值讓所有人難以置信的是,GPT-4o系列的參數如此少,mini版甚至只有8B。

有網民猜測,4o mini是一個大約有40B參數的MoE模型,其中激活參數為8B。
因為,他發現4o mini明顯比8B模型學到了更多的知識,同時間運行速度很快。
此外,由於GPT-4o是MoE架構,所以OpenAI可能在mini版本上使用了相同的架構。

另有網民驚訝地表示,Claude 3.5 Sonnet參數竟等同於GPT-3 davinci。

這篇來自微軟、華盛頓大學團隊的論文中,發佈了一個具有里程碑意義的評估基準——MEDEC1,專為臨床筆記醫療錯誤檢測和糾正而設計。
 論文地址:https://arxiv.org/abs/2412.19260
論文地址:https://arxiv.org/abs/2412.19260這項基準涵蓋了五種類型的錯誤,包括診斷、管理、治療、藥物治療和致病因子。
MEDEC的數據來源,收集了來自3家美國醫院系統的488篇臨床筆記,總計3,848篇臨床文本。
值得一提的是,這些數據此前從未被任何LLM接觸過,能夠確保評估真實性可靠性。目前,該數據集已被用於MEDIQA-CORR共享任務,以評估17個參與系統的表現。

得到數據集MEDEC後,研究團隊對當前最先進的模型,包括o1-preview、GPT-4、Claude 3.5 Sonnet、Gemini 2.0 Flash等,在醫療錯誤檢測和糾正任務中進行了全面測試。
同時,他們也邀請了兩位專業醫生進行相同的錯誤檢測任務,最終將AI與人類醫生結果進行PK。
結果發現,最新LLM在醫療錯誤檢測和糾正方面表現不俗,但與人類醫生相比,AI還是有著明顯的差距。
這也從側面印證了,MEDEC是一個具有充分挑戰性的評估基準。
論文講了什麼?
來自美國醫療機構的一項調查研究顯示,每5位閱讀臨床筆記的患者中,就有一位報告發現了錯誤。
其中40%的患者認為這些錯誤是嚴重的,最常見的錯誤類別與當前或過去的診斷相關。

與此同時,如今越來越多的醫學文檔任務(比如,臨床筆記生成)均是由LLM去完成。
然而,將LLM用於醫學文檔任務的主要挑戰之一,容易產生「幻覺」,輸出一些虛構內容或錯誤信息,直接影響了臨床決策。
畢竟,醫療無小事,一字之差可能關乎生死。
為了降低這些風險,並確保LLM在醫學內容生成中的安全性,嚴格的驗證方法至關重要。這種驗證需要相關的基準來評估是否可以通過驗證模型實現完全自動化。
在驗證過程中,一個關鍵任務是,檢測和糾正臨床文本中的醫學錯誤。
站在人類醫生的角度來考慮,識別和糾正這些錯誤不僅需要醫學專業知識和領域背景,有時還需要具備豐富的經驗。
而此前,大多數關於(常識性)錯誤檢測的研究都集中在通用領域。
為此,微軟華盛頓大學團隊引入了全新數據集——MEDEC,並對不同的領先的LLM(比如,Claude 3.5 Sonnet、o1-preview和Gemini 2.0 Flash)進行了實驗。
作者稱,「據我們所知,這是首個公開可用的臨床筆記中自動錯誤檢測和糾正的基準和研究」。
MEDEC數據集
MEDEC數據集一共包含了3,848篇來自不同醫學專業領域的臨床文本的新數據集,標註任務由8位醫學標註員完成。
如前所述,該數據集涵蓋了五種類型的錯誤,具體包括:
- 診斷(Diagnosis):提供的診斷不準確
- 管理(Management):提供的管理下一步措施不準確
- 藥物治療(Pharmacotherapy):推薦的藥物治療不準確
- 治療(Treatment):推薦的治療方案不準確
- 致病因子(Causal Organism):指出的致病生物或致病病原體不準確
(註:這些錯誤類型是在分析醫學委員會考試中最常見的問題類型後選定的。)
上圖1展示了,MEDEC數據集中的示例。每篇臨床文本要麼是正確的,要麼包含一個通過以下兩種方法之一創建的錯誤:方法#1(MS)和方法#2(UW)。
數據創建方法#1(MS)
在此方法中,作者利用了MedQA集合中的醫學委員會考試題目。
4位具有醫學背景的標註員參考這些考試中的醫學敘述和多項選擇題,在核對原始問題和答案後,將錯誤答案注入場景文本中,並排除包含錯誤或信息模糊的問答對。
醫學標註員遵循以下準則:
使用醫學敘述多項選擇題,將錯誤答案注入場景文本中,並創建兩個版本,分別將錯誤注入文本的中間或末尾。
使用醫學敘述多項選擇題,將正確答案注入場景文本中,以生成正確版本,如圖2所示(包含正確答案的生成文本)。
手動檢查自動生成的文本是否忠實於原始場景及其包含的答案。
最終,研究人員從兩個不同的場景(錯誤注入文本中間或末尾)中,隨機為每篇筆記選擇一個正確版本和一個錯誤版本,構建了最終數據集。

數據創建方法#2(UW)
這裏,作者使用了華盛頓大學(UW)三家醫院系統(Harborview Medical Center、UW Medical Center 和 Seattle Cancer Care Alliance)從2009年-2021年間的真實臨床筆記數據庫。
研究人員從中17,453條診斷支持記錄中,隨機選取了488條,這些記錄總結了患者的病情並提供了治療依據。
4名醫學生組成的團隊手動向其中244條記錄中引入了錯誤。
在初始階段,每條記錄都標註了若干候選實體,這些實體由QuickUMLS 4識別為統一醫學語言系統(UMLS)的概念。
標註員可以從這些候選實體中選擇一個簡潔的醫學實體,或者創建一個新的文本片段(span)。隨後,該片段被標記為五種錯誤類型之一。
接著,標註員用類似但不同的概念替換該片段,錯誤版本由標註員自行設計或通過基於SNOMED和LLM的方法生成。這種方法向標註員建議替代概念,但不依賴輸入文本。醫學標註員手動確定最終注入文本中的概念或錯誤。
在此過程中,每個錯誤片段必須與臨床筆記中的至少兩個其他部分相矛盾,同時標註員需為每個引入的錯誤提供合理的解釋。
作者使用了Philter5工具對注入錯誤後的臨床筆記進行自動去標識化處理。
隨後,每條筆記由2名標註員獨立審查以確保去標識化的準確性。對於任何分歧,由第3名標註員進行裁定。
下表1展示了訓練集、驗證集和測試集的劃分情況。其中,MS訓練集包含2,189篇臨床文本,MS驗證集包含574篇臨床文本,UW驗證集包含160篇臨床文本。
MEDEC測試集由MS集合的597篇臨床文本和UW數據集的328篇臨床文本組成。測試集中,51.3%的筆記包含錯誤,而48.7%的筆記是正確的。
 下圖3展示了數據集中錯誤類型的分佈情況(診斷、管理、治療、藥物治療和致病因子)。
下圖3展示了數據集中錯誤類型的分佈情況(診斷、管理、治療、藥物治療和致病因子)。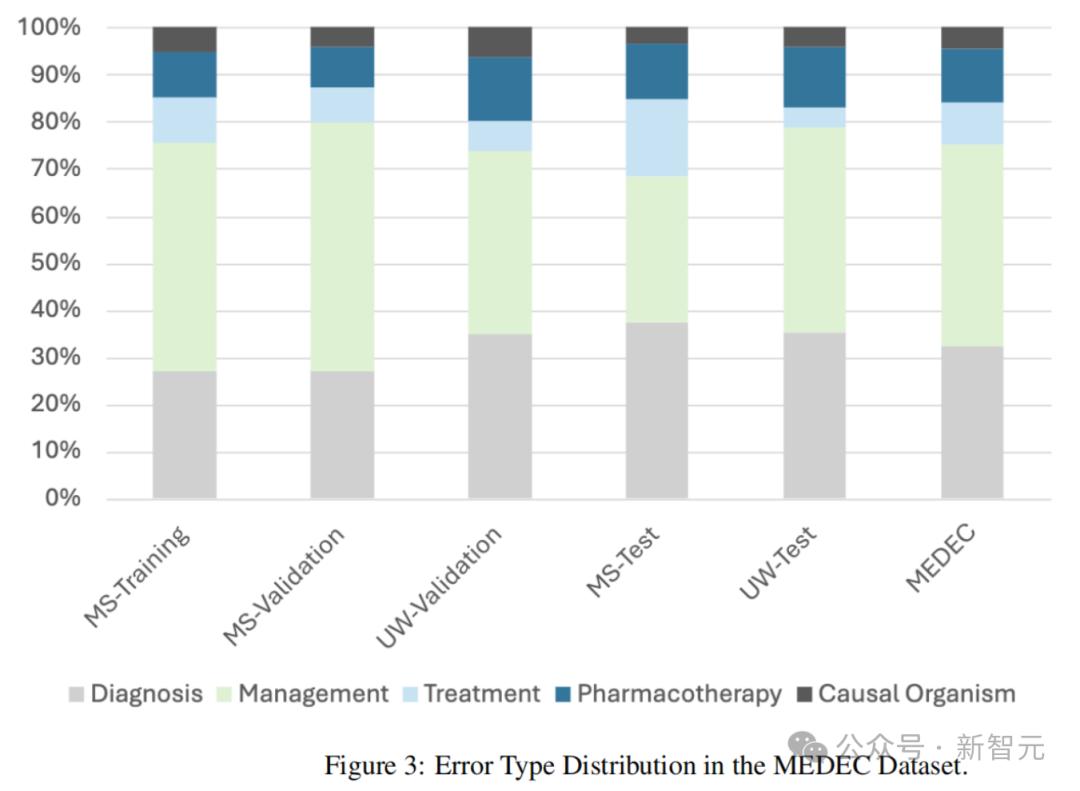
醫療錯誤檢測與糾正方法
為了評估模型在醫療錯誤檢測與糾正任務中的表現,作者將該過程劃分為三個子任務:
子任務 A:預測錯誤標誌(0:如果文本沒有錯誤;1:如果文本包含錯誤)
子任務 B:提取包含錯誤的句子,用於已標記錯誤的文本(-1:如果文本沒有錯誤;句子ID:如果文本包含錯誤)
子任務 C:為包含錯誤的標記文本生成修正後的句子(NA:如果文本沒有錯誤;生成的句子/修正內容:如果文本有錯誤)
為了進行比較,他們基於LLM構建瞭解決方案,使用了兩種不同的提示詞來生成所需的輸出,以評估模型在這三個子任務中的表現:
提示詞#1:
以下是關於一名患者的醫療敘述。你是一名熟練的醫生,正在審閱這些臨床文本。文本要麼是正確的,要麼包含一個錯誤。文本中每行是一句話。每行以句子ID開頭,後跟一個豎線符號,然後是需要檢查的句子。檢查文本中的每一句話。如果文本正確,則返回以下輸出:CORRECT。如果文本中存在與治療、管理、病因或診斷相關的醫療錯誤,則返回包含錯誤的句子ID,後跟一個空格,然後是修正後的句子。發現並糾正錯誤需要用到醫學知識與推理能力。
提示詞#2:與第一個提示詞類似,但包含一個從訓練集中隨機選取的輸入和輸出示例:
以下是一個示例。
0 一名35歲的女性向她的醫生訴說手部疼痛和僵硬。1 她說,疼痛始於6周前,在她克服了一次輕微的上呼吸道感染幾天后開始。(……) 9 雙手的雙側X線顯示左手第五掌指關節周圍輕微的關節周圍骨質減少。10 給予甲氨蝶呤。
在這個示例中,錯誤出現在句子編號10:「給予甲氨蝶呤」。修正為:「給予潑尼鬆」。輸出為:10 1 Prednisone is given。示例結束。
實驗與結果
語言模型
研究人員對幾種近期的語言模型進行了實驗:
Phi-3-7B:具有70億參數的小語言模型(SLM)。
Claude 3.5 Sonnet(2024-10-22):Claude 3.5系列的最新模型(≈1750億參數),在多個編碼、視覺和推理任務中展現出了SOTA的性能。
Gemini 2.0 Flash:最新/最先進的Gemini模型。其他Google模型(如專為醫療設計的Med-PaLM,5400億參數)尚未公開。
ChatGPT(≈1750億參數)和GPT-4(≈1.76萬億參數),是「高智能」模型。
GPT-4o(≈2000億參數),提供「GPT-4級別的智能但速度更快」,以及專注於特定任務的小模型GPT-4o-mini(gpt-4o-2024-05-13)(≈80億參數)。
最新的o1-mini(o1-mini-2024-09-12)(≈1000億參數)和o1-preview(o1-preview-2024-09-12)(≈3000億參數),具備「全新AI能力」,可處理複雜推理任務。
值得注意的是,大多數模型的參數量為估算值,主要用來幫助理解模型性能。少數模型(如Phi-3和Claude)需要進行少量自動後處理來修正格式問題。
結果
下表2展示了,由醫療醫生手動標註的結果以及使用上述兩個提示詞的多個最新LLM的結果。
在錯誤標誌(error flag)檢測方面,Claude 3.5 Sonnet以70.16%的準確率優於其他方法,在錯誤句子檢測中更是達到了65.62%的準確率。
o1-mini在錯誤標誌檢測中,拿下了第二高的準確率69.08%。
在錯誤糾正方面,o1-preview以0.698的綜合評分(Aggregate Score)獲得了最佳表現,遠超第二名GPT-4 [P#2] 的0.639。

下表3展示了,在每個數據集(MEDEC-MS和MEDEC-UW)上的錯誤檢測準確率和錯誤糾正評分。其中,MS子集對Claude 3.5 Sonnet和醫生#2來說更具挑戰性,而UW子集對o1-preview和醫生#1來說更具挑戰性。
結果表明,與醫生的評分相比,最新的LLM在錯誤檢測和糾正方面表現良好,但在這些任務中仍然不及人類醫生。
這可能是因為,此類錯誤檢測和糾正任務在網絡和醫學教科書中相對罕見,也就是,LLM在預訓練中遇到相關數據的可能性較低。
這一點可以從o1-preview的結果中看出,該模型在基於公開臨床文本構建的MS子集上的錯誤和句子檢測中分別取得了73%和69%的準確率,而在私有的UW集合上僅取得了58%和48%的準確率。
另一個因素是,任務需要分析和糾正現有的非LLM生成的文本,這可能比從0開始起草新答案的難度更高。

下表4展示的則是,每種錯誤類型(診斷、管理、治療、藥物治療和病因微生物)的錯誤檢測召回率和錯誤糾正評分。
可以看到,o1-preview在錯誤標誌和句子檢測中,召回率顯著高於Claude 3.5 Sonnet和兩位醫生。但在結合準確率結果(見表2)之後發現,醫生在準確率上表現更佳。
這些結果表明,模型在精確度方面存在顯著問題,並且與醫生相比,AI在在許多情況下都過度預測了錯誤的存在(即產生了幻覺)。

另外,結果還顯示,分類性能與錯誤糾正生成性能之間存在排名差異。
例如,在所有模型中,Claude 3.5 Sonnet在錯誤標誌和句子檢測的準確率上排名第一,但在糾正生成評分中排名最後(見表 2)。
此外,o1-preview在所有LLM中的錯誤檢測準確率排名第四,但在糾正生成中排名第一且遙遙領先。同樣的模式也可以在兩位醫療醫生之間觀察到。
上述現象,可以通過糾正生成任務的難度來解釋,同時也可能反映了當前SOTA的文本生成評估指標在捕捉醫學文本中的同義詞和相似性方面的局限性。
表5展示了參考文本、醫生標註以及由Claude 3.5 Sonnet和GPT模型自動生成的糾正示例。
例如,第二個示例的參考糾正表明患者被診斷為Bruton無丙種球蛋白血症,而LLM提供的正確答案提到了X-連鎖無丙種球蛋白血症(該罕見遺傳疾病的同義詞)。
此外,一些LLM(如Claude)提供了更長的答案/糾正,並附上了更多解釋。類似的現象也出現在醫生的標註中,其中醫生#1提供的修正比醫生#2更長,而兩位醫生在某些示例/案例中存在不同意見,這反映了由不同醫生/專家撰寫的臨床筆記在風格和內容上的差異。

關於醫療錯誤檢測和糾正的相關研究下一步,還需要在提示詞中引入更多示例並進行示例優化。
作者介紹
Wen-wai Yim

Wen-wai Yim是微軟的高級應用科學家。
她在UCSD獲得生物工程學士學位,並在華盛頓大學獲得生物醫學與健康信息博士學位,研究方向包括從臨床和放射學筆記中提取臨床事件以及進行癌症分期預測。
此外,還曾在史丹福大學擔任博士後研究員,開發用於從自由格式臨床筆記中提取信息的方法,並將這些信息與電子病曆中的元數據相結合。
她的研究興趣包括從臨床筆記和醫學對話中進行臨床自然語言理解,以及從結構化和非結構化數據生成臨床筆記語言。
Yujuan Fu

Yujuan Fu是華盛頓大學醫學信息專業的博士生。
此前,她在上海交通大學獲得電子與計算機工程學士學位,在密歇根大學獲得數據科學學士學位。
研究領域是面向健康領域的自然語言處理:通過指令微調大語言模型,包括信息抽取、摘要、常識推理、機器翻譯以及事實一致性評估。
Zhaoyi Sun

Zhaoyi Sun是華盛頓大學生物醫學與健康信息學專業的博士生,隸屬於UW-BioNLP團隊,由Meliha Yetisgen博士指導。
此前,他在南京大學獲得化學學士學位,並在康奈爾大學獲得健康信息學碩士學位。
他的研究重點是將LLM應用於醫療問答和臨床筆記中的錯誤檢測,興趣是結合生物醫學圖像與文本的多模態深度學習研究,目標是提升自然語言處理技術在臨床領域中的應用效率和效果。
Fei Xia

Fei Xia是華盛頓大學語言學系的教授,也是華盛頓大學/微軟研討會的聯合組織者。此前,曾在IBM T. J. Watson研究中心擔任研究員。
她在北京大學計算機科學係獲得學士學位,並在賓夕法尼亞大學計算與信息科學係獲得碩士和博士學位。
在賓大期間,她是中文樹庫項目的團隊負責人,也是XTAG項目的團隊成員。博士論文導師是Martha Palmer博士和Aravind Joshi博士。
參考資料:
https://x.com/koltregaskes/status/1874535044334969104
https://arxiv.org/pdf/2412.19260
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。