度小滿近日宣佈開源國內首個金融行業推理大模型——軒轅-FinX1
度小滿近日宣佈開源國內首個金融行業推理大模型——軒轅-FinX1!
該模型是金融領域首個類 GPT-O1 推理大模型,首次將大模型深度推理能力注入金融領域,採用創新的「思維鏈+過程獎勵+強化學習」訓練範式,顯著提升邏輯推理能力,並可展示 O1 模型未公開的完整思考過程。
軒轅-FinX1 由度小滿研發,本次發佈的是預覽版本,現已在開源社區開放免費下載。後續優化版本也將持續開源,供用戶下載使用。
Github 地址:https://github.com/Duxiaoman-DI/XuanYuan
基準測試結果
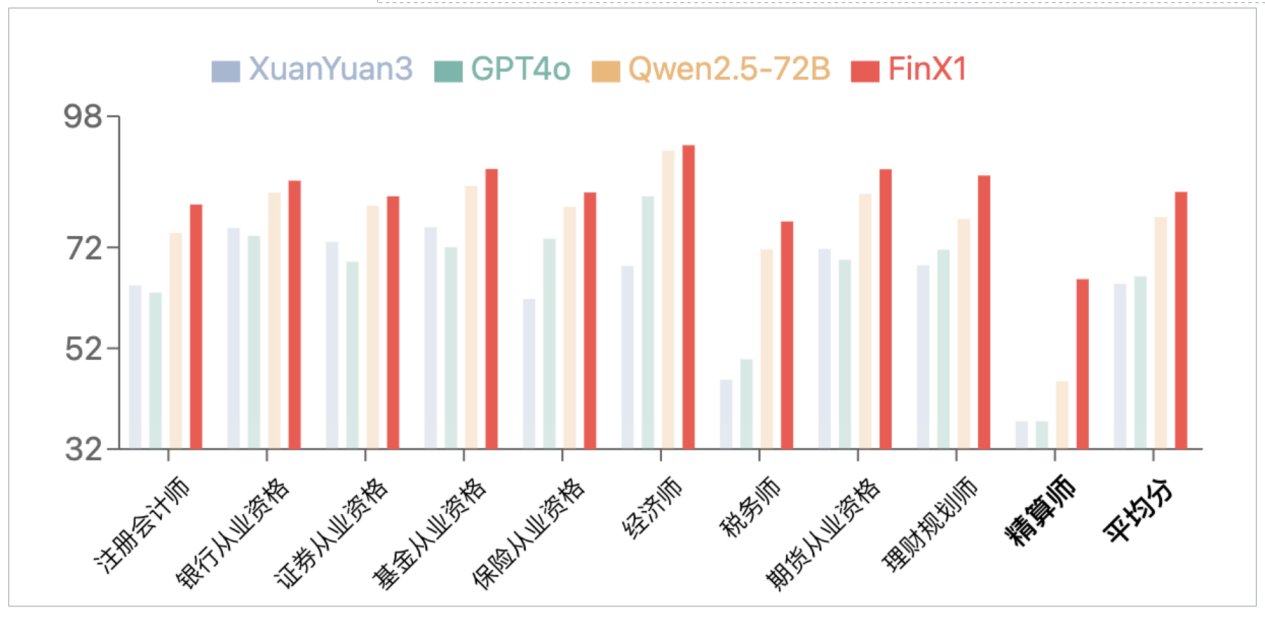
在金融評測基準 FinanceIQ 上,初代軒轅-FinX1 展現了卓越的表現。在 CPA、銀行從業資格、證券從業資格等 10 大類金融權威資格認證中,均超越了 GPT-4o 和開源模型 Qwen2.5-72B,並相較上一版 XuanYuan3 實現了大幅提升。尤其是在精算師這一類別,此前所有大模型得分普遍偏低,而軒轅-FinX1 將分數從 37.5 提升至 65.7,顯著體現了其在金融邏輯推理和數學計算方面的強大優勢。
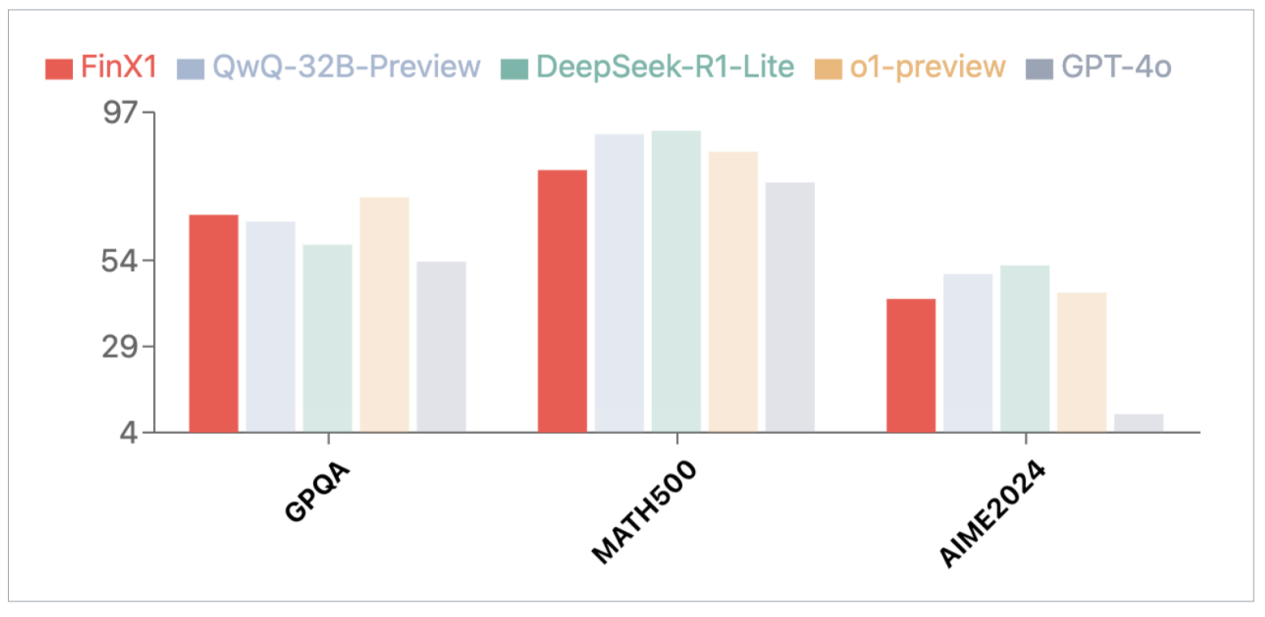
除了金融領域,初代軒轅-FinX1 也展現了突出的通用能力。在多個權威評測集上的測試結果顯示,軒轅-FinX1 不僅在 GPQA(科學推理)、MATH-500(數學) 和 AIME2024(數學競賽) 等評測中取得卓越成績,還超越了 GPT-4o,與 O1 以及國內最新發佈的推理版大模型共同位列頂尖梯隊,驗證了其強大的基礎推理能力。
軒轅-FinX1 代表了在 2024 年度小滿為「金融大模型該往何處走」提供的答案。這背後有著怎樣的深度思考?總結起來就是:深挖專有數據,優化推理能力,提升業務深度,以及持續開放開源。
ChatGPT 火爆以來,金融機構一直在積極探索如何將生成式大模型應用在金融領域,但全球範圍內都沒有標杆案例。金融領域大部分數據都是私密的,市場上的大模型難以直接適配業務需求,而且在精準度要求高和計算複雜度高的業務,比如反欺詐、財務分析等,生成式大模型被發現即便投入大量資源也無法解決這些問題。
推理大模型誕生前,金融領域的大模型主要用於文檔摘要、客服、營銷等非核心業務場景。對於高難度應用,大模型只能給出開放性的參考建議,而不能自己完成最後一公里的決策步驟。
因此,推理優化給金融領域帶來的衝擊,將是變革性的。
押注推理能力優化
推理是 2024 年 AI 領域的主角,從 O1 到 O3,大模型顯示出越來越強大的推理能力。這些成果並非像過去那樣主要基於更大的算力、模型和數據集,而是集中在推理能力計算上的優化。
推理計算優化能力的提升有多種典型的模式,比如多輸出、反饋迭代、逆向推理、思維鏈、Best-of-N 策略、Agent 工作流、複雜問題拆解、推理過程評估等,其中複雜問題拆解和推理過程評估經發現是提升最普遍有效的方法。
度小滿也在其最新發佈的金融推理大模型中重點採用了這類方法,並與經典方法進行了融合,實現了基於金融決策加強的雙獎勵模型的強化學習訓練方法。
為了評估模型在金融決策場景下的表現,度小滿設計了結果導向 (ORM) 和過程級 (PRM) 兩個互補的獎勵模型。
PRM 是度小滿針對金融領域的推理過程的創新,重點解決了開放性金融問題(如市場分析、投資決策等)的評估難題。
對於 PRM 的訓練數據構建,度小滿針對不同場景採用了不同策略:對於風險評級等有確定答案的問題,更偏重結果,使用反向驗證方法;對於開放性的金融分析問題,則更偏重過程,通過多個大模型從正確性、必要性、邏輯性等多維度進行標註,並通過下采樣和主動學習解決了分析類思考過程中正樣本中過多帶來的數據不平衡問題。
在強化學習訓練階段,度小滿採用 PPO 算法進行 online 訓練,將 PRM 和 ORM 作為獎勵信號。對於思考過程,使用 PRM 在每個思考步驟進行打分,及時發現和糾正思考路徑中的錯誤;對於答案部分,則針對不同類型的問題採用不同的評估策略:對有確定答案的金融問題(如風險等級評估)採用規則匹配計算獎勵,對開放性問題(如市場分析)則使用 ORM 進行整體評分。
基於此,度小滿實現了 PRM 和 ORM 雙引導下的強化學習微調。
這種基於雙重獎勵的訓練機制,不僅克服了單一獎勵模型的局限性,也通過穩定的強化學習訓練顯著提升了模型在金融決策場景下的推理能力。
可以看出,上述路線中的關鍵是對不同於數學或者邏輯的金融分析類開放問題的思維鏈數據的構造和獎勵模型的評估,目前度小滿仍在仍在不斷優化和迭代,會持續探索更有效的技術路線。
基於這些技術創新,度小滿率先展現了使用大模型進行金融複雜分析決策的價值。
專注金融複雜分析決策
度小滿首次將大模型深度推理能力注入金融領域,推動大模型在金融領域的應用從非核心業務場景深入到風控決策等核心業務場景。
決策與風控能力
決策與風控能力方面,在風險識別與預測、風控模型構建、策略製定等核心任務中,軒轅 FinX1 憑藉強大的推理能力和完整的思維鏈機制,能夠系統分析風險因素間的關聯與傳導路徑,為機構提供全面深入的風險洞察。
例如,根據用戶上傳的銀行流水,軒轅 FinX1 能夠從上千條交易記錄中精準識別高頻彩票消費、遊戲消費等風險信號,並結合收入水平和債務負擔,科學評估用戶的還款能力和信貸風險。
 軒轅 FinX1 分析用戶上傳的銀行流水
軒轅 FinX1 分析用戶上傳的銀行流水研究分析能力
研究分析能力方面,軒轅 FinX1 能對宏觀經濟數據、市場情緒、政策影響等進行多維度分析,通過清晰的邏輯鏈條逐步拆解複雜問題。
例如,在分析美聯儲政策時,模型不僅深入探討了經濟數據背後的深層原因,還結合多維度市場信息進行量化分析,甚至能夠對未來政策走勢進行預測,展現出專業的研究深度。
 軒轅 FinX1 預測美聯儲降息政策
軒轅 FinX1 預測美聯儲降息政策數據智能能力
數據智能能力的核心是高效的數據處理能力和深度的分析能力。軒轅 FinX1 可幫助金融機構快速挖掘數據背後的業務邏輯與價值。
例如,將某公司季度財務數據輸入軒轅 FinX1,模型能夠精準提取核心信息,直觀展示資產質量、流動性與業務動態。通過分析「流動性壓力」「資產擴張驅動」等關鍵指標,軒轅 FinX1 在量化比較的基礎上補充定性解釋,揭示財務數據背後的潛在風險與增長機會,助力企業優化決策。
 軒轅 FinX 分析某公司季度財務數據
軒轅 FinX 分析某公司季度財務數據在金融行業數智化轉型浪潮中,「決策與風控能力」、「研究分析能力」和「數據智能能力」構成了推動業務創新和價值提升的關鍵維度。這些能力分別通過精準的風險識別與管控、深入的市場研判與價值發現、高效的數據建模與分析,為機構帶來持續價值增長。

但對於 AI 金融推理這個大命題而言,這僅僅是一個開始。
垂域 AI 推理的無限潛力
今年整個行業的領先者都在大力押注大模型推理優化,是別無選擇,還是推理優化有可預見的潛力?
LLM 最初展現出推理能力,是基於 CoT 即思維鏈的激發,也就是通過提示工程,讓大模型不直接給出答案,而是一步一步地推理再給出最終結果。經驗表明這樣能讓大模型的生成結果準確率顯著提升。
OpenAI 資深研究科學家 Noam Brown 曾說出一個驚人的發現,只需讓大模型多思考 20 秒,其提升效果相當於將模型的規模擴大 10 萬倍並增加 10 萬倍的訓練時間。可以說,僅僅是 AI 從不假思索到深度思考的經驗性提升程度,就足以給人信心投入下一代模型的開發。
而另一個決定性的判據是,理論研究表明,只要投入足夠的時間和資源,LLM 推理能做到的事情和通過一般計算機、編程做到的事情是一致的,所以 AI 還能借助推理機制繼續增強能力。學界甚至認為大模型推理機制是本質存在的,存在於潛在空間「黑盒」中,不是對於人類思維的模仿。
如此看來,AI 發展還遠遠沒有撞牆,對推理優化需求更強的各個垂直領域將大有可為。
為了加速推進推理優化的發展,不同於 O1,軒轅 FinX1 選擇了更加開放的方式,打開了「黑盒」,它能夠在生成回答前先呈現完整的思考過程,構建從問題拆解到最終結論的全透明思維鏈。通過這一機制,軒轅 FinX1 不僅提升了推理的可解釋性,也解決了傳統大模型的「黑盒」問題,為金融機構提供了更加可信的決策支持工具。
如下圖所示,對於「智能高頻交易風險評估系統設計與實現」這個問題,軒轅 FinX1 在分析問題、解決問題等階段,都非常詳盡地展示了其完整的思考過程,不僅是分步驟的,也是逐步深入的,會在思考推進至問題解決的核心因素之後再逐步解決問題。
 軒轅 FinX1 的思維鏈生成示例
軒轅 FinX1 的思維鏈生成示例在垂直領域、推理範式上,AI 還有無窮的金礦等待挖掘,在這個時間節點上著力垂域推理大模型,正當其時。



















