AAAI 2025 | 多模態大語言模型空間智能新探索:僅需單張圖片或一句話,就可以精準生成3D建模代碼啦!
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的主要作者來自上海交通大學電子信息與電氣工程學院 i-WiN 中心團隊,團隊負責人是上海交通大學講席教授關新平。本文的第一作者為上海交通大學博士生王思宇,研究方向涉及多模態大模型、大模型的可靠生成及其工業應用。本文的通訊作者和主要指導老師為i-WiN中心陳彩蓮教授、樂心怡副教授和許齊敏副研究員。
計算機輔助設計(CAD)已經成為許多行業設計、繪圖和建模的標準方法。如今,幾乎每一個製造出來的物體都是從參數化 CAD 建模開始的。CAD 構造序列是 CAD 模型表示的一種類型,不同於 Mesh 類型的三角網格、B-rep 格式的點、線、面表示,它被描述為一系列建模操作,包括確定草圖 3D 起點和 3D 草圖平面方向、繪製 2D 草圖、將草圖拉伸成 3D 實體形狀的完整參數和過程,以 JSON 代碼格式儲存和表示。這類表示方法與專業建模工程師構建 CAD 模型的過程最為近似,可以直接被導入 AutoDesk、 ProE 等建模軟件。構建這些 CAD 模型需要領域專業知識和空間推理能力,也需要較高的學習成本。
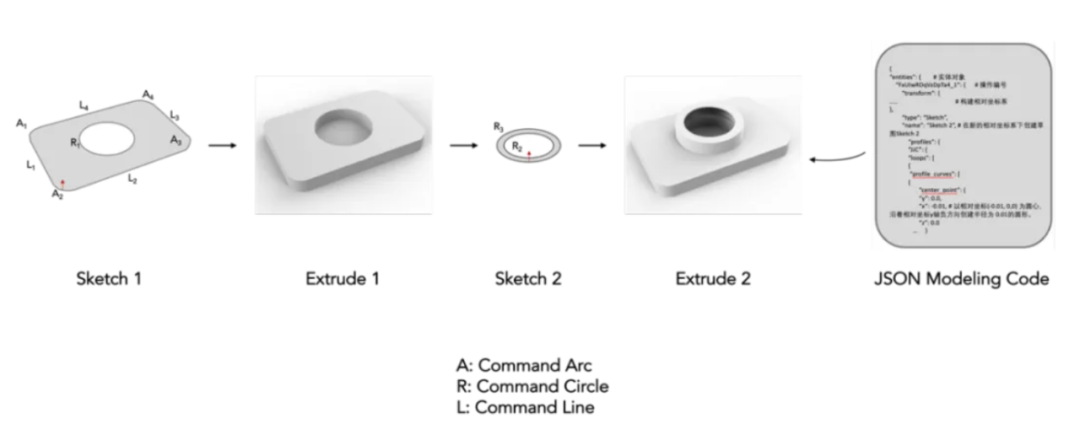
圖 1. CAD 建模代碼示意圖
作為空間智能的關鍵能力之一,空間建模能力對 MLLM 提出了嚴峻的挑戰。儘管 MLLM 在生成 2D 網頁佈局代碼等方面展現出了卓越的性能,這類方法在 3D 建模領域仍然存在問題,比如生成 4 個平行於車底方向車輪的小車。這是因為 MLLM 在推理 3D 草圖角度和 3D 空間位置時受限於大語言模型的 1D 推理慣性,難以理解複雜數字背後真正的空間含義。
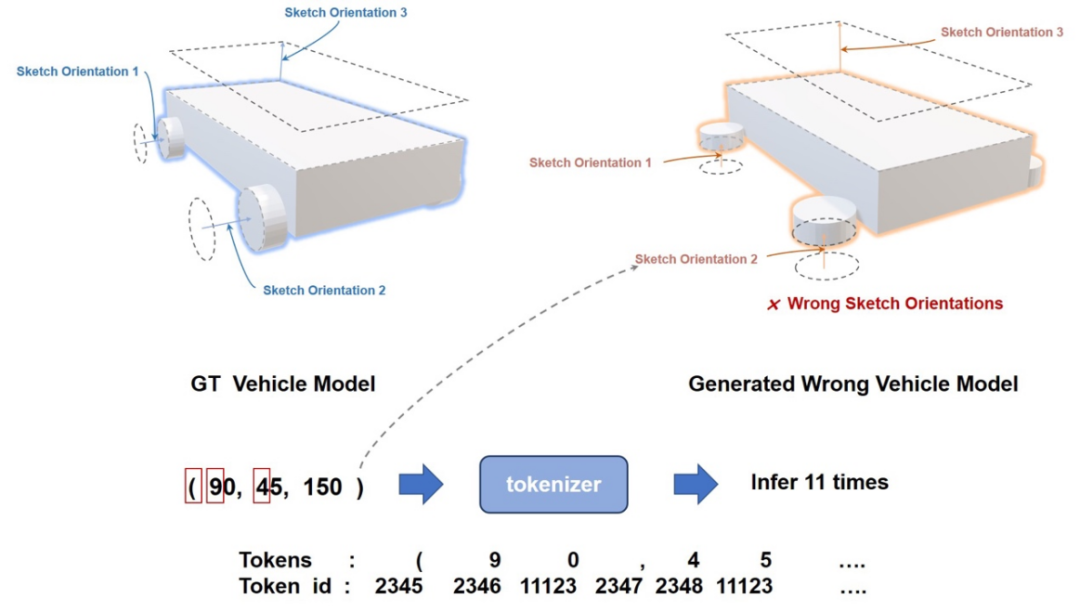
圖 2. 原始多模態大模型 3D 建模效果差原因分析
近期,來自上海交通大學的 i-WiN 研究團隊提出了專門用於 CAD 建模的多模態大語言模型 CAD-GPT,結合專門設計的 3D 建模空間定位機制,將 3D 參數映射到 1D 語言信息維度,提高了 MLLM 的空間推理能力,實現了基於單張圖片或一句話描述的精準 CAD 建模構造序列生成。該項研究以《CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs》為題,被 AAAI 2025 接收。

-
論文標題:CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs
-
論文地址:https://arxiv.org/abs/2412.19663
-
項目地址:https://OpenIWIN.github.io/CAD-GPT/
方法介紹
3D 建模空間定位機制
我們把關鍵的 3D、2D 建模參數定義為大語言模型可以理解的建模語言,便於大模型理解和生成。具體來說,設計了 3 個系列的定位 token 來代替 3D 草圖平面起點坐標、3D 草圖平面角度和 2D 草圖曲線坐標的參數。通過將全局空間 3D 坐標、草圖平面 3D 旋轉角度的特徵展開到一維語言特徵空間,將它們轉換為兩類不同的 1D 位置 tokens。此外,2D 草圖被離散化並轉換為特殊的 2D token。這些 token 被合併到原始 LLM 詞表中。同時,納入了 3 類適配 3 種 token 的自定義可學習的位置嵌入,以彌合語言和空間位置之間的差距。
數據集構建
基於 DeepCAD 數據集,生成了 160k 固定視角渲染的 CAD 模型圖像和 18k 相應的自然語言描述數據集,構建專門用於訓練多模態大語言模型的 CAD 建模數據集,便於後續其他工作訓練大模型生成 CAD 模型建模序列。
訓練策略與細節
我們採用 LLaVA – 1.5 7B 版本作為基礎模型。訓練包括兩個階段:首先在 image2CAD 任務上進行訓練,然後在 text2CAD 任務上降低學習率進行微調。此外,因 CAD 建模序列長度較長,我們基於外推法,通過超參調整,擴展 LLM 的窗口長度到 8192。
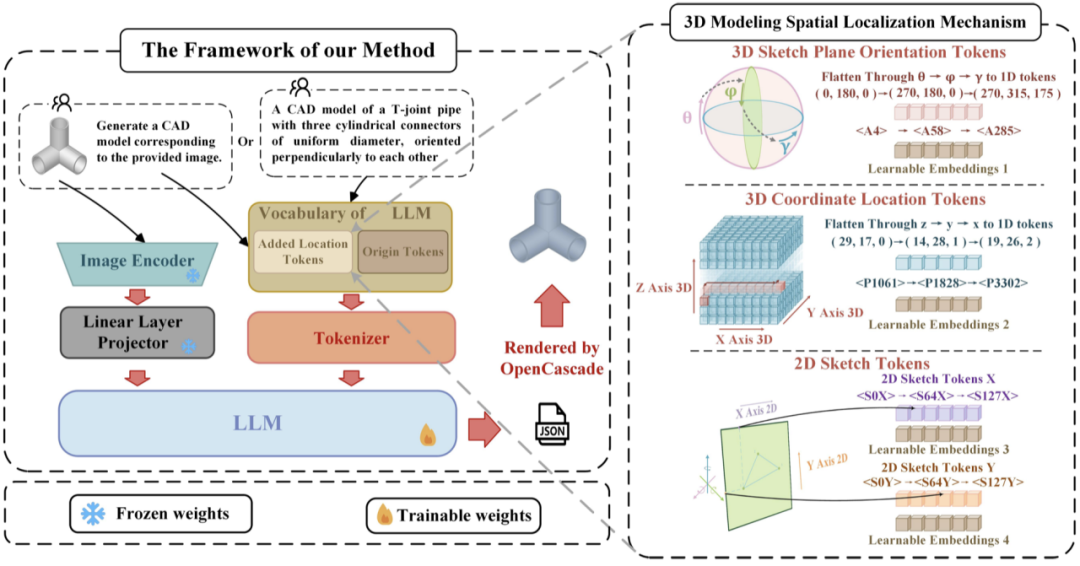
圖 3. CAD-GPT 原理框架圖
實驗效果展示

圖 4. CAD-GPT 生成的各種 CAD 模型展示
圖 4 中的模型展示了包含精準語義草圖生成能力(如心形和字母 「E」)、帶有類別的 CAD 生成能力(如桌子、椅子和鑰匙)、空間推理能力(如桌子和相互垂直的圓柱體),以及生成不同尺寸的相同模型的能力(如三個有兩個圓孔的不同尺寸連接器)。
基於單張圖片的生成效果
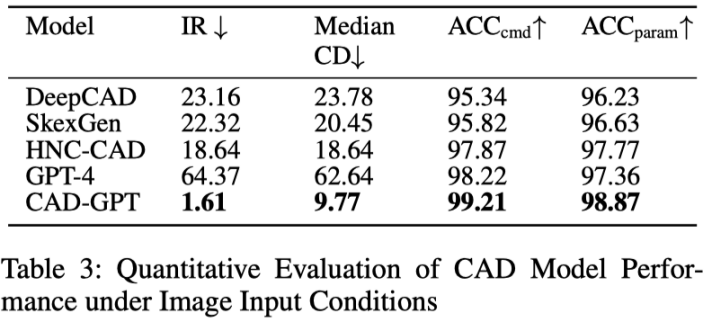
將 CAD-GPT 與三種代表性方法進行了比較。第一個是 DeepCAD,它演示了 CAD 建模中的先進生成技術。第二個是 GPT-4,代表了閉源多模態大型模型的前沿。第三個是 Qwen2-VL-Max,這是領先的開源多模態大型模型之一。相比之下,CAD-GPT 產生的輸出既準確又美觀。
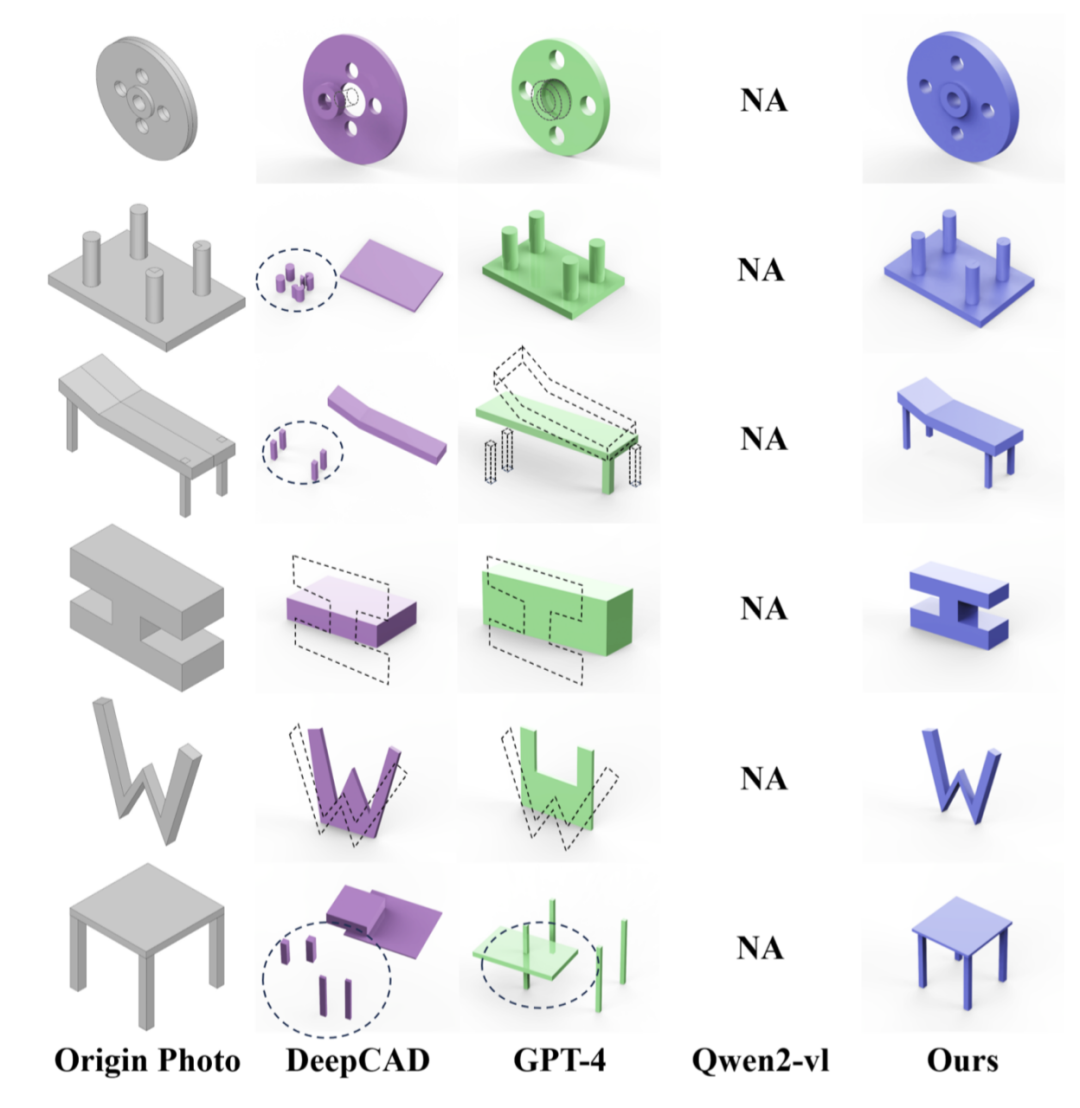
圖 5. 基於圖片的 CAD 生成效果對比
基於一句話描述生成效果展示
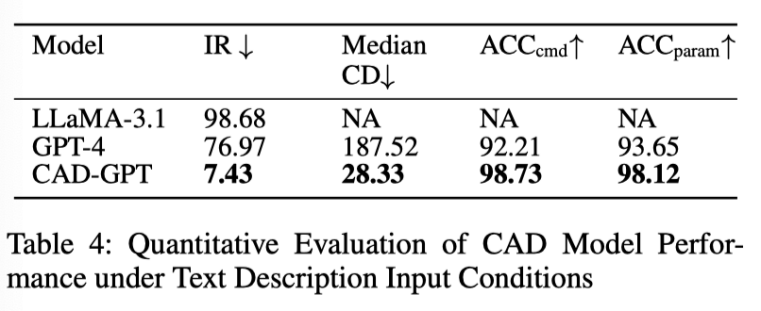
本文選擇了兩個有代表性的大型語言模型:領先的閉源模型 GPT-4 和最先進的開源模型 LLaMA-3.1(405B)。如圖 6 所示,我們的模型始終生成高精度、美觀的輸出,並且展示出了與文本描述對應的語義信息。
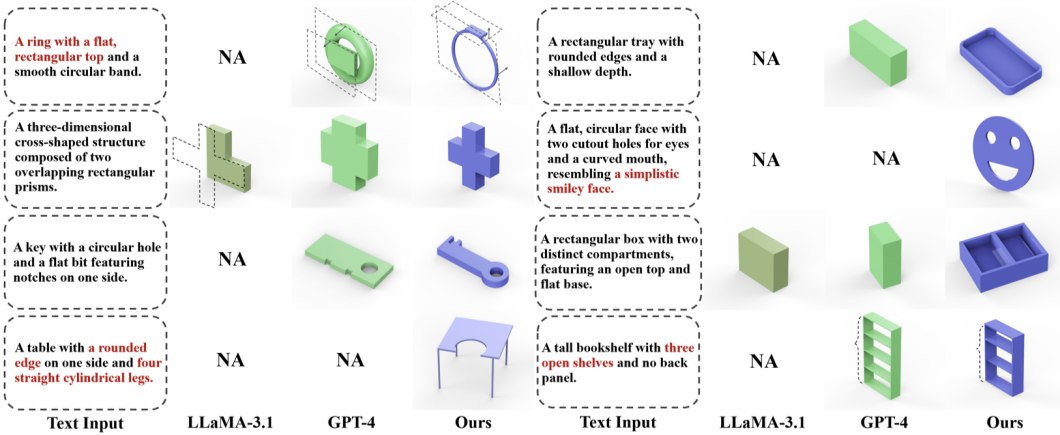
圖 6. 基於文本描述的 CAD 生成效果對比
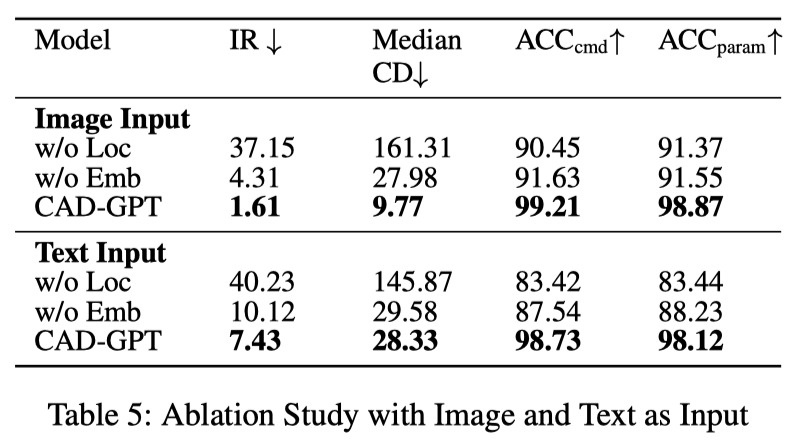
消融實驗
圖 7 展示了是否添加 3D 建模空間定位機制訓練模型的差異。如圖所示,添加定位機制後,CAD-GPT 可以精準的推理空間角度、位置變化,以及生成準確的 2D 草圖。
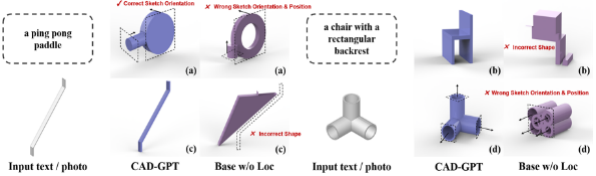
圖 7. 消融實驗效果展示
總結
本文提出 CAD-GPT,一種具有三維建模空間定位機制的多模態大模型,以提高空間推理能力。所提出模型擅長推斷草圖 3D 方向的變化、3D 空間位置的變化,並準確渲染 2D 草圖。利用這些功能,CAD-GPT 在單張圖像和文本輸入條件下生成精確 CAD 模型方面表現出卓越的性能。