北大、港理工革新性LiNo框架:線性與非線性模式有效分離,性能全面超越Transformer
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的通訊作者為北京大學計算機學院長聘副教授楊仝和香港理工大學助理教授王淑君。第一作者為香港理工大學 24 級博士生餘國齊,以及聯合作者北京大學 21 級軟微學院博士生、每因智能創始人郭瀟宇等。研究工作在北京大學計算機學院數據結構實驗室和每因智能發起的研究課題中完成。

-
論文鏈接:https://arxiv.org/pdf/2410.17159
-
代碼鏈接:https://github.com/Levi-Ackman/LiNo
時間序列數據,作為連續時間點的數據集合,廣泛存在於醫療、金融、氣象、交通、能源(電力、光伏等)等多個領域。有效的時間序列預測模型能夠幫助我們理解數據的動態變化,預測未來趨勢,從而做出更加精準的決策。然而,時間序列數據通常包含複雜的線性和非線性模式,這些模式往往相互交織 (見下圖 Fig.1),給預測模型的設計和優化帶來了巨大挑戰。
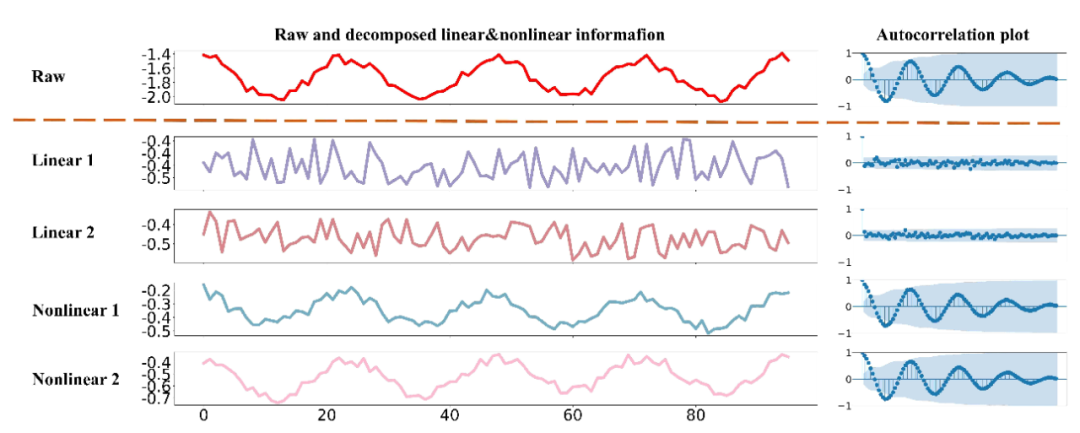
Fig.1 現實世界的時間序列往往是多種線性和非線性的交疊。上圖中紅色的序列可以被表徵為其下方的兩種線性和兩種非線性模式的加和。
現有的模型依賴於 Autoformer 中提出的基於殘差的 Trend (線性) 和 seasonal (非線性) 分解 —— 先使用一個運動平均核 (Auto/FEDformer,DLinear) 或者可學習卷積 (Leddam) 來獲取 Trend 項,然後使用原始序列減去 Trend 得到 Seasonal 項。但是這樣只能獲取簡單的線性模式,而且得到的非線性模型或者說 Seasonal 項事實上是由未充分提取的線性模型,待提取的非線性模式,以及序列中的噪聲所組成的,應該被稱為 Residual(殘差),而不是 Seasonal。
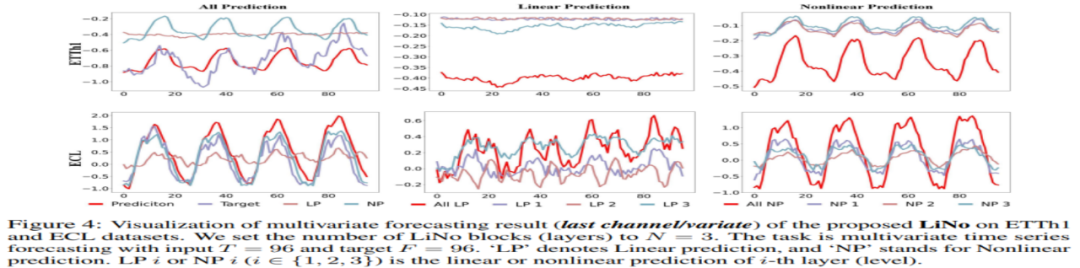
Fig.2 LiNo 在電力數據集中最後一個變量上的預測可視化,LP 指線性預測,NP 指非線性預測。左側的 Prediction(預測值)被劃分為 General 的線性和非線性預測,中間和右側,線性和非線性預測進一步被劃分為更細緻的多種模式。
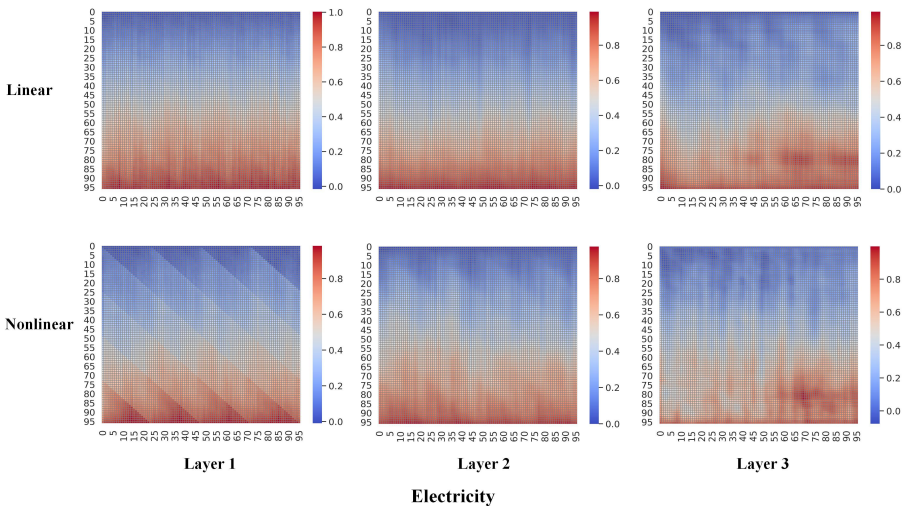
Fig.3 Fig2 中用於預測各個線性和非線性份量的抽像權重的可視化。可以看到每種模式的預測權重是各有差異的。
同時,觀察 Fig2&3,我們可以看到線性模式更多關注序列的長期模式,而非線性更多關注短期浮動。另外,用於預測線性和非線性的權重,以及用於預測不同線性或者不同非線性的權重之間均存在差異。因此,高效地對這些線性和非線性模式進行分離,不僅可以幫助理解時間序列內部的特質,得到更具有解釋性的預測結果,還能幫助我們設計更高效更魯棒的預測算法。
正是在這樣的背景下,北京大學聯合香港理工大學以及每因智能的研究團隊提出了 LiNo 框架。該框架通過遞歸殘差分解(Recursive Residual Decomposition, RRD)技術,實現了對線性和非線性模式的顯式提取。
 Fig.4 LiNo 框架圖
Fig.4 LiNo 框架圖LiNo 框架的算法核心在於其遞歸殘差分解(RRD)策略,該策略靈感來源於經驗模態分解(Empirical Mode Decomposition, EMD)。LiNo 採用兩個主要的模塊:Li 塊和 No 塊,分別負責線性和非線性模式的提取。
-
Li 塊(Linear block):這一模塊負責提取時間序列中的線性模式,如趨勢和週期性成分。通過學習時間序列數據的自回歸特性,Li 塊可以捕捉長期依賴關係。Li 塊可以採用移動平均核或其他線性濾波器,以捕捉數據中的線性結構。
-
No 塊(Nonlinear block):這一模塊負責提取時間序列中的非線性模式,如突變和複雜的季節性變化。No 塊可以採用 Transformer 編碼器或 TSMixer 等其他非線性模型,以捕捉數據中的非線性動態。
-
通過交替和遞歸地應用 Li 塊和 No 塊,LiNo 框架能夠逐步剝離並提取時間序列中的複雜模式,直到殘差信號中不再包含有用的信息。在經過多個 LiNo 塊的處理後,最終的預測結果是通過聚合所有 Li 塊和 No 塊的輸出得到的。
這種方法不僅提高了模型對週期性特徵的捕捉能力,而且增強了對非週期性特徵的建模能力。
以下是算法的詳細過程:
1.Li 塊(Li Block)
Li 塊的設計目的是提取時間序列中的線性模式。它通過一個可學習的自回歸模型(AR)來實現,該模型具有完整的感受野,可以替代傳統的移動平均(MOV)、可學習的一維卷積核(LD)和指數平滑函數(ESF)。
-
線性模式提取:
對於輸入特徵
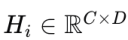
,其中
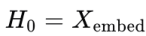
,Li 塊通過以下公式提取第 i 個線性模式
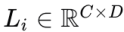
:
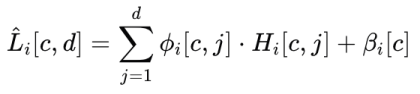
這裏,
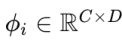
表示自回歸係數,表示偏置項。
-
卷積操作:
提取線性部分的過程可以通過卷積實現,其中卷積核的權重設置為
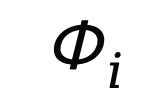
,偏置的權重設置為
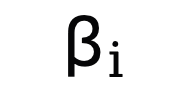
-
填充和 Dropout:
在應用卷積之前,對輸入特徵 H_i 進行填充,以確保 H_i 和 L_i 具有相同的尺度。通過應用 Dropout 以增強模型的泛化能力。
-
線性預測:
– 通過映射提取的線性成分 L_i 得到該層的線性預測
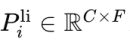
。
2.No 塊(No Block)
No 塊的設計目的是同時處理時間序列中的時變模式、頻率信息和序列間依賴性。
-
時變和頻率模式提取:
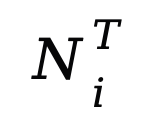
和頻率信息模式
– 使用快速傅里葉變換(FFT)和逆快速傅里葉變換(IFFT)在時域和頻域之間轉換。
-
特徵融合:
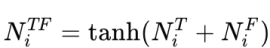
-
序列間依賴性建模:
使用 softmax 函數對進行通道維度的歸一化,然後計算加權平均值以獲得序列間依賴性信息
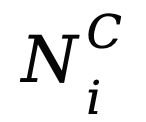
-
非線性模式整合:
將時變、頻率和序列間依賴性信息整合,通過層歸一化和 MLP 處理,得到整體非線性模式 N_i。
-
非線性預測:
通過映射提取的非線性部分 N_i 得到該層的非線性預測
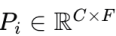
3. 聚合方法
最終的預測結果是通過聚合所有 Li 塊和 No 塊的輸出得到的:
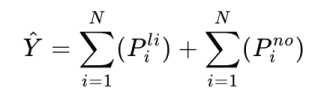
這種方法不僅提高了模型對週期性特徵的捕捉能力,而且增強了對非週期性特徵的建模能力,從而在多個真實世界數據集上實現了優於現有最先進方法的性能。
在涵蓋電力、金融、交通等 13 個廣泛使用的真實世界數據集上,無論是單元時間序列預測還是多元時間序列預測,LiNo 均取得了優於現有最先進方法的性能,而且展現出優異的魯棒性。
LiNO 框架在多變量時間序列預測中表現卓越(如表 1),尤其在 10 個基準數據集中的 9 個上實現了最低的 MSE 和 8 個上的最低 MAE,顯著超越了包括 iTransformer 在內的先前模型。在高維度和複雜非線性的 PEMS 和 ECL 數據集上,LiNO 通過精細的非線性模式提取,平均 MSE 分別實現了 11.89% 和 7.87% 的降低。這些結果突出了 LiNO 在處理複雜時間序列數據時的高效能力,無論是在電力、交通還是金融領域,都展現了其在捕捉線性與非線性模式平衡中的重要性。
 表 1 多變量時間序列預測
表 1 多變量時間序列預測LiNO 框架在單變量時間序列預測任務中展現了頂尖的性能,根據表 2 的分析,它在所有 6 個數據集上都取得了最佳的預測結果。與先前的最先進方法 MICN 相比,LiNO 在六個數據集上將均方誤差(MSE)降低了 19.37%,平均絕對誤差(MAE)降低了 10.28%。特別是在 Weather、E湯臣h2 和 Traffic 數據集上,LiNO 分別實現了 47.11%、28.64% 和 12.97% 的 MSE 降低,這標誌著預測精度的顯著提升。LiNO 在單變量和多變量時間序列預測中的一致優越表現證明了它在不同場景下的廣泛適用性。
 表 2 單變量時間序列預測
表 2 單變量時間序列預測LiNO 框架在單變量時間序列預測領域的表現極為出色,其設計基於 iTransformer 這一領先業界的變換器模型作為基礎架構。如表 3 所示,通過與 ‘Raw’(傳統設計)和 ‘Mu’(N-BEATS 中使用的遞歸表示分裂預測設計)的比較,LiNO 在 E湯臣m2、ECL 和 Weather 數據集上實現了 2.96%、6.34% 和 6.72% 的 MSE 降低,這一成就凸顯了其在有效分離和處理線性與非線性模式方面的高效率。此外,LiNO 在面臨不同噪聲水平的挑戰時,依然展現出了卓越的魯棒性和可靠性,如圖 5 所示,這不僅驗證了其設計的穩健性,也進一步證實了在時間序列預測模型中區分線性與非線性模式對於提升預測魯棒性的重要性。
 表 3 LiNo 框架對 iTransformer Backbone 的預測精度提升
表 3 LiNo 框架對 iTransformer Backbone 的預測精度提升 Fig 5 LiNo 框架對 iTransformer Backbone 的魯棒性提升
Fig 5 LiNo 框架對 iTransformer Backbone 的魯棒性提升LiNo 框架的提出,不僅推動了時間序列預測技術的發展,也為設計更有效、更魯棒,更具有解釋性的預測模型提供了新的思路和工具。