史丹福AI科研神器開源,一鍵成文GPT-4o mini加持,科研寫作徹底解放雙手
史丹福大學最新AI進展!開源STORM&Co-STORM系統,只需填寫主題,就可以全面整合資源,避開信息盲點生成高質量長文。
AI寫作神器,竟被史丹福開源了!
在OpenAI與Perplexity絞盡腦汁去動Google搜索的蛋糕時,史丹福研究團隊卻「於無聲處響驚雷」,一鳴驚人推出了支持避開信息盲點、全面整合可靠信息、從頭寫出域奇長文的STORM&Co-STORM系統。

背後模型是由必應搜索,以及GPT-4o mini加持。

簡單來講,STORM&Co-STORM系統分為兩部分。
STORM通過讓「LLM專家」與「LLM主持人」進行多角度問答,以此從提綱,到段落與文章的迭代式生成。
Co-STORM則是能夠通過讓多智能體之間互相對話並生成可交互的動態思維導圖,以避免遺漏掉用戶沒注意到的信息需求。
該系統只需輸入英文主題詞,就能生成有效整合了多源信息的高質量長文(如域奇百科文章)。

進入主頁,可以自選模式STORM和Co-STORM。

給定主題後,STORM便可以在3分鐘內就形成如下演示中的一篇「形神兼備」的結構化高質量長文。

我們也可以在給出的文章上麵點擊「See BrainSTORMing Process」來獲取如下圖所示中,不同LLM Role的頭腦風暴過程。

在「發現」欄中,還可以參考當前其他學者生成的一些文章,以及聊天的示例。

另外,個人生成的文章和聊天記錄,都可以在側邊欄My Library中找到。
系統一經發佈,大家紛紛上手體驗,許多人驚歎道,STORM & Co-STORM實在讓人眼前一亮!
「你只需輸入一個主題,它就會搜索數百個網站,然後把主要發現寫成一篇文章。關鍵是每個人都可以免費使用!」

網民JoshPeterson更是利用STORM,第一時間去結合NotebookLLM自動生成了播客。
具體流程是這樣的:使用STORM生成4篇文章,然後將其中2篇提交給GPT-4o分析並提出後續主題。最後再把它們添加到NotebookLM里,一期有聲的播客就做好了。

網民Pavan Kumar則是認為STORM揭示了一個重大趨勢:「 就算是沒有博士學曆,也可以創作出現階段博士生才能有的成果。而將來一年的課程內容也足以媲美如今4-7年才能修讀到的課程內容。」

STORM協助從頭寫出域奇好文

傳統長文寫作(如域奇百科文章)需要大量人工進行寫作前的準備,包括資料蒐集和大綱構建,而目前的生成式寫作方法通常忽略這些步驟。
但是這也意味著生成文章往往面臨著信息角度覆蓋不周到,文章內容不夠充實的問題。
而STORM可以通過多個LLM-Role互相提問與回答來讓文章內容所涉及的角度更加詳實周全。
如下圖所示,STORM系統分為三大階段:
多視角問題生成:
– 為了覆蓋主題的不同方面,系統引入多角色模擬(如專家、普通用戶),並生成視角引導的問題- 圖(A)顯示了簡單問題生成的效果有限,圖(B)演示了通過視角引導問題生成的多樣性提升
大綱生成與完善:
– 使用模型的內置知識生成初步大綱。- 系統通過對話(圖C)模擬提問並完善大綱,使其更具深度
全文生成:
– 基於大綱逐節生成文章,利用檢索到的信息增加內容可信度和引用

從給定的主題入手,STORM系統通過查閱相關的域奇百科文章(步驟1-2)來確定涵蓋該主題的各種視角。
接著,它會模擬這樣一場對話:一方是域奇百科撰寫者,其會依據給定視角提出問題,另一方則是基於可靠網絡來源的專家(步驟3-6)。
根據LLM的固有知識, 從不同視角收集到的對話內容, 最終精心編排了寫作大綱(步驟7-8)。
 STORM系統自動化寫作的整體流程
STORM系統自動化寫作的整體流程由於早期的研究採用了不同的設置,並未使用大語言模型(LLM),因此難以直接進行比較。
所以研究者使用了以下三種基於LLM的基線方法:
1. Direct Gen:一種直接提示LLM生成提綱的基線方法,生成的提綱隨後用於創作完整的文章。
2. RAG:一種檢索增強生成(Retrieval-Augmented Generation)基線方法,該方法通過主題進行搜索,並利用搜索結果與主題一起生成提綱或完整的文章。
3. oRAG(提綱驅動的RAG):與RAG在提綱創建上完全一致,但進一步通過章節標題檢索額外信息,以逐章節地生成文章內容。
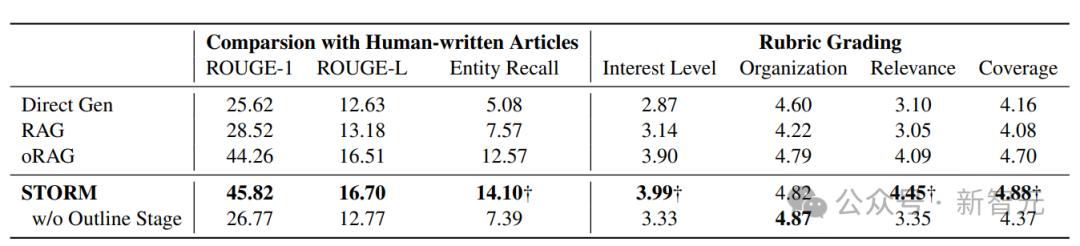
從上表可以發現,利用STORM生成的文章完全不輸於人類水平,並且也優於目前LLM生成文章的幾種範式,如效果最強的oRAG。
但不可否認的是,STORM生成文章的質量在中立性和可驗證性方面仍然落後於經過精心修訂的人工撰寫文章。
雖然STORM在研究給定主題時發現了不同的視角,但收集的信息可能仍然傾向於互聯網的主流來源,並可能包含促銷內容。
該研究的另一個局限性是,儘管研究者專注於從零開始生成類似域奇百科文章,但他們也僅考慮生成自由組織的文本。而人工撰寫的高質量域奇百科文章通常包含結構化數據和多模態信息。
因此,目前利用LLM生成文章所面臨的最關鍵的挑戰,依然是基於事實去生成擁有多模態結構的高質量文章。
智能體溝通打破人類盲點,顯著降低認知負擔
對於一些學習任務來講,在蒐集整合信息中,通常會由於個人或搜索引擎偏好而造成信息遺漏,以至於無法觸及信息盲點(即未意識到的信息需求)。
研究團隊在下列論文中所提出的Co-STORM正是為了改善這一情況,以大幅促進學習效率。

在學習工作中,使用搜索引擎面臨著需要閱覽過多的冗餘信息,而和Chatbots問答聊天,則又不知道如何進行準確的提問。但是這兩種獲取信息的方式都無法觸及「信息盲點」,況且認知負擔還不小。
那如果閱讀現有的一些報導呢?這雖然降低了認知負擔,但並不支持交互,無法讓我們去更進一步的進行深度學習。
而與上述信息獲取方式不同,Co-STORM智能體能夠代表用戶提問,能夠多方位地獲取新信息,探索到自己的「信息盲點」。然後通過動態思維導圖組織信息,並最終生成綜合報告。

如下圖所示,Co-STORM由以下模塊組成:
–多智能體協作對話:由「專家」和「主持人」進行模擬對話,探討主題各個方面的相關內容。
–動態思維導圖:實時追蹤對話內容,將信息按層次組織,幫助用戶理解和參與。
–報告生成:系統基於思維導圖生成引用明確、內容翔實的總結報告。

為了更真實地反映用戶體驗,研究者對20名誌願者進行了人類評估,比較了Co-STORM與傳統搜索引擎和RAG Chatbot的表現。結果顯示:
1. 信息探索體驗:
– Co-STORM顯著提升了信息的深度和廣度- 用戶發現其能夠有效引導探索盲點
2. 用戶偏好:
– 70%的用戶更喜歡Co-STORM,認為其顯著減少了認知負擔- 用戶特別認可動態思維導圖對跟蹤和理解信息的幫助

不過,目前STORM&Co-STORM還僅支持英語交互,未來或許官方團隊會將其擴展至擁有多語言交互能力。

最後,正如網民TSLA的感受一樣,「我們正生活在一個非凡的時代。今天,不僅所有的信息都變得觸手可及,甚至連信息獲取的方式也可以完全根據自己的水平量身定製,讓學習任何東西都成為可能。」

主要作者介紹

Yucheng Jiang是史丹福大學計算機科學專業的碩士研究生。
他的研究目標是通過創建能夠與用戶無縫協作的系統,提升學習能力、決策效率和工作生產力。

Yijia Shao是史丹福大學自然語言處理(NLP)實驗室的二年級博士生,由楊笛一教授指導。
此前,她是北京大學元培學院的本科生,通過與Bing Liu教授的合作,開始接觸並從事機器學習和自然語言處理的研究。
參考資料:
https://x.com/dr_cintas/status/1874123834070360343
https://storm.genie.stanford.edu/
https://www.arxiv.org/abs/2408.15232
https://arxiv.org/abs/2402.14207
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。