你的專屬「鐵甲奇俠」助手OS Agents來了!浙大聯手OPPO、零一萬物等10個機構推出全新綜述
OS Agents團隊 投稿
量子位 | 公眾號 QbitAI
電影《鐵甲奇俠》中,東尼·斯塔克的助手賈維斯(J.A.R.V.I.S.)能幫他控制各種系統並自動完成任務,曾讓無數觀眾羨慕不已。
現在,這樣的超級智能助手,終於變成現實了!
隨著多模態大語言模型的爆髮式進化,OS Agents橫空出世,它們能無縫操控電腦和手機,為你自動搞掂繁瑣任務。
從Anthropic的Computer Use,到蘋果的Apple Intelligence,再到智譜AI的AutoGLM,以及Google DeepMind的Project Mariner,科技巨頭們的野心都指向了同一個目標:打造真正意義上的操作系統智能助手。
OS Agents 已經不僅僅是「助手」,它們正在改寫「人機交互」的遊戲規則。
最近,浙江大學聯手OPPO、零一萬物等十個機構共同梳理了一篇綜述文章《OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use》,不僅詳細解讀了OS Agents的硬核技術構造,還盤點了它們的評估方法和未來挑戰。
科技行業的下一個新風口,會是OS Agents嗎?

OS Agents商業學術同時迸發
像賈維斯這樣的超級AI助手,一般被稱為OS Agents,它們能夠通過操作系統(OS)提供的環境和接口(如圖形用戶界面,GUI),在諸如電腦或者手機等計算設備上自動化的完成各類任務。
OS Agents有巨大的潛力改善全球數十億用戶的生活,想像一個世界:在線購物、預訂差旅等日常活動都可以由這些智能體無縫完成,這將大幅提高人們的生活效率和生產力。
過去,諸如Siri[1]、Cortana[2]和Google Assistant[3]等AI助手,已經展示了這一潛力。然而,由於模型能力在過去較為有限,導致這些產品只能完成有限的任務。
幸運的是,隨著多模態大語言模型的不斷髮展,如Gemini[4] 、GPT[5] 、Grok[6] 、Yi[7] 和Claude[8] 系列模型(排名根據2024年12月22日更新的 Chatbot Arena LLM Leaderboard[9]),這一領域迎來了新的可能性。
(M)LLMs展現出令人矚目的能力,使得OS Agents能夠更好地理解複雜任務並在計算設備上執行。
基礎模型公司和手機廠商近期在這一領域動作頻頻,例如最近由Anthropic推出的Computer Use[10]、由蘋果公司推出的Apple Intelligence[11]、由智譜AI推出的AutoGLM[12]和由Google DeepMind推出的Project Mariner [13]。
其中,Computer Use利用Claude[14]與用戶的計算機直接互動,可以實現無縫的任務自動化。
與此同時,學術界已經提出了各種方法來構建基於(M)LLM的OS Agents。
例如,OS-Atlas[15]提出一種 GUI 基礎模型,通過跨多個平台綜合 GUI 操作數據,大幅改進了模型對 GUI 的操作能力,提升OOD任務的表現。
而OS-Copilot[16]則是一種OS Agents框架,能夠使智能體在少監督情況下實現廣泛的計算機任務自動化,並展示了其在多種應用中的泛化能力和自我改進能力。
 △OS Agents的部分代表性商業產品與學術研究
△OS Agents的部分代表性商業產品與學術研究本文是對OS Agents進行的一次全面綜述。
首先闡明OS Agents的基礎,探討了其關鍵要素,包括環境、觀察空間和動作空間,並概述了理解、規劃和執行操作等核心能力。
接著,審視了構建OS Agents的方法,重點關注OS Agents領域特定的基礎模型和智能體框架的開發。
隨後,文章詳細回顧了評估協議和基準測試,展示了OS Agents在多種任務中的評估方式。
最後,文章討論了當前的挑戰並指出未來研究的潛在方向,包括安全與隱私、個性化與自我進化。
本文旨在梳理OS Agents研究的現狀,為學術研究和工業開發提供幫助。
為了進一步推動該領域的創新,團隊還維護了一個開源的GitHub倉庫,包含250+有關OS Agents的論文以及其他相關資源,並且仍在持續更新中。(鏈接在文章末尾~)
 △OS Agents基礎:關鍵要素和核心能力
△OS Agents基礎:關鍵要素和核心能力OS Agents基礎
關鍵要素 (Key Component)
要實現 OS Agents 對計算設備的通用控制,需要通過與操作系統提供的環境、輸入和輸出接口進行交互來完成目標。
為滿足這種交互需求,現有的 OS Agents 依賴三個關鍵要素:
-
環境(Environment):智能體操作的系統或平台,例如電腦、手機和瀏覽器。環境是智能體完成任務的舞台,支持從簡單的信息檢索到複雜的多步驟操作。
-
觀察空間(Observation Space):智能體可獲取的所有信息範圍。這些信息諸如屏幕截圖、文本描述或GUI界面結構,是智能體理解環境和任務的基礎。例如,網頁的 HTML 代碼或手機的屏幕截圖。
-
動作空間(Action Space):智能體與環境交互的動作集合。它定義了可執行的操作,如點擊、輸入文本、導航操作甚至調用外部工具。這使得智能體能夠自動化完成任務並優化工作流。
核心能力 (Capability)
在OS Agents的這些關鍵要素後,如何與操作系統正確、有效的交互,這就需要考驗OS Agents自身各方面的能力。
OS Agents必須掌握的核心能力可以總結為如下三點:
-
理解(Understanding):OS Agents 首先需要理解複雜的操作環境。無論是 HTML 代碼、屏幕截圖,還是屏幕界面中密集的圖標和文本信息,智能體都需要通過理解能力提取關鍵內容,構建對任務和環境的全面認知。這種理解能力是處理信息檢索等任務的前提。
-
規劃(Planning):在任務執行中,OS Agents 的規劃能力至關重要。規劃能力要求OS Agents將複雜任務拆解為多個子任務,並製定操作序列來實現目標。同時,它們最好還要能夠據環境變化動態調整計劃,以適應複雜的操作系統環境,例如動態網頁和實時更新的用戶屏幕界面。
-
操作(Grounding):OS Agents最終需要將規劃轉化為具體的、可執行的操作,例如點擊按鈕、輸入文本或調用 API。這種將規劃「落地」的能力使得它們能夠在真實環境中高效完成任務,並實現從文字描述到操作執行的精準轉換。
OS Agents的構建
基礎模型 (Foundation Model)
要構建能夠高效執行任務的 OS Agents ,其核心在於開發適配的基礎模型。
這些模型不僅需要理解複雜的屏幕界面,還要在多模態場景下執行任務。
下面是對基礎模型的架構與訓練策略的詳細歸納與總結:
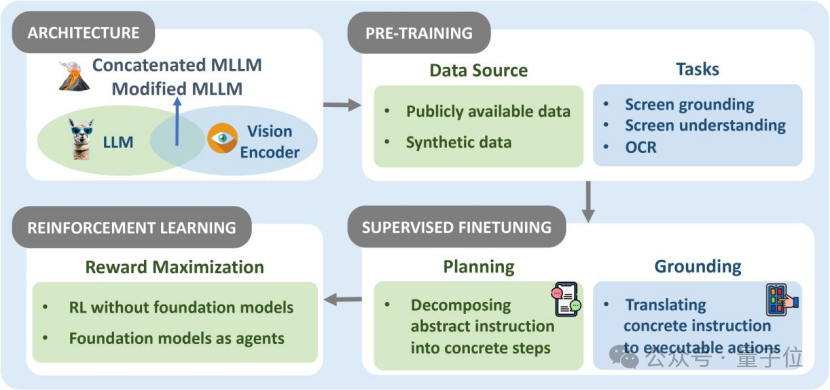 △OS Agents基礎模型:架構、預訓練、監督微調和強化學習
△OS Agents基礎模型:架構、預訓練、監督微調和強化學習架構(Architecture):我們將主要的模型架構分為四個類別:1、Existing LLMs:直接採用開源的大語言模型架構,將結構化的屏幕界面信息以文本形式輸入給LLMs,從而使得模型可以感知環境;2、Existing MLLMs:直接採用開源的多模態大語言模型架構,整合文本和視覺處理能力,提升對GUI的理解能力,減少文本化視覺信息而造成的特徵損失;3、 Concatenated MLLMs:由LLM與視覺編碼器橋接而成,靈活性更高,可以根據任務需求選擇不同的語言模型和視覺模型進行組合;4、Modified MLLMs:對現有 MLLM 架構進行優化調整,以解決特定場景的挑戰,如:添加額外模塊(高解像度視覺編碼器或圖像分割模塊等),以更細緻地感知和理解屏幕界面細節。
預訓練(Pre-training):預訓練為模型構建打下基礎,通過海量數據提升對屏幕界面的理解能力。數據源包括公共數據集、合成數據集;預訓練任務覆蓋屏幕定位(Screen Grounding)、屏幕理解(Screen Understanding)與光學字符識別(OCR)等。
監督微調(Supervised Fine-tuning):監督微調讓模型更貼合 GUI 場景,是提升OS Agents規劃能力和執行能力的重要手段。例如,通過記錄任務執行軌跡生成訓練數據,或利用 HTML 渲染屏幕界面細節,提升模型對不同 GUI 的泛化能力。
強化學習(Reinforcement Learning):現階段的強化學習實現了用(M)LLMs作為特徵提取到(M)LLM-as-Agent的範式轉變,幫助了OS Agents在動態環境中交互,根據獎勵反饋,不斷優化決策。這種方法不僅提升了智能體的對齊程度,還為視覺和多模態智能體提供了更強的泛化能力與任務適配性。
近期OS Agents基礎模型的相關論文總結如下:
 △OS Agents基礎模型近期研究工作總結
△OS Agents基礎模型近期研究工作總結智能體框架 (Agent Framework)
OS Agents 除了需要強大的基礎模型,還需要搭配上Agent框架來增強感知、規劃、記憶和行動能力。
這些模塊協同工作,使 OS Agents 能夠高效應對複雜的任務和環境。
以下是OS Agents框架中四大關鍵模塊的總結歸納:
 △OS Agents框架:感知、規劃、記憶和行動
△OS Agents框架:感知、規劃、記憶和行動感知(Perception):感知作為OS Agents 的「眼睛」,通過輸入的多模態數據(如屏幕截圖、HTML 文檔)觀察環境。我們將感知細分為:1、文本感知:將操作系統的狀態轉化為結構化文本描述,如 DOM 樹或 HTML 文件;2、屏幕界面感知:使用視覺編碼器對屏幕界面截圖進行理解,通過視覺定位(如按鈕、菜單)和語義連接(如 HTML 標記)精準識別關鍵元素。
規劃(Planning):規劃作為OS Agents 的「大腦」,負責製定任務的執行策略,可以分為:1、全局規劃:一次生成完整計劃並執行;2、迭代規劃:隨著環境變化動態調整計劃,使智能體能夠適應實時更新的屏幕界面和任務需求。
記憶(Memory):OS Agents框架的「記憶」部分可以幫助存儲任務數據、操作歷史和環境狀態。記憶分為三個類型:1、內部記憶(Internal Memory):存儲操作歷史、屏幕截圖、狀態數據和動態環境信息,支持任務執行的上下文理解和軌跡優化。例如,借助截圖解析屏幕界面佈局或根據歷史操作生成決策;2、外部記憶(External Memory):提供長期知識支持,例如通過調用外部工具(如 API)或知識庫獲取領域背景知識,輔助複雜任務的決策;3、特定記憶(Specific Memory):聚焦於特定任務的知識和用戶需求,例如存儲子任務分解方法、用戶偏好或屏幕界面交互功能,提供高度針對性的操作支持。此外,我們還總結了多種記憶優化策略。
行動(Action):我們將OS Agents 的行動範圍定義為動作空間,這包含操作系統交互的方式,我們將其細分為三個類別:1、輸入操作:輸入是 OS Agents 與數字屏幕界面交互的基礎,主要包括鼠標操作、觸控操作和鍵盤操作;2、導航操作:使 OS Agents 能夠探索和移動於目標平台,獲取執行任務所需的信息;3、擴展操作:突破了傳統屏幕界面交互的限制,為智能體提供更靈活的任務執行能力,例如:代碼執行與API 調用。
近期有關OS Agents框架的論文總結如下:
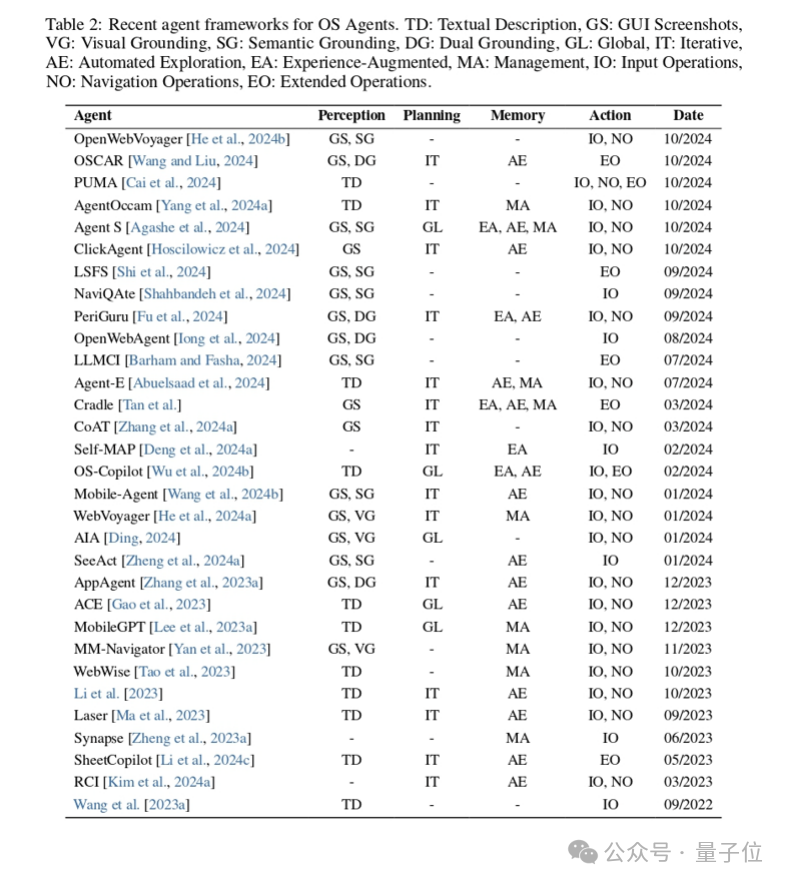 △OS Agents框架近期研究工作總結
△OS Agents框架近期研究工作總結OS Agents的評估
在 OS Agents 的發展中,科學的評估起到了關鍵作用,幫助開發者衡量智能體在各種場景中的性能。
下面的表格總結了近期有關OS Agents評估基準的論文:
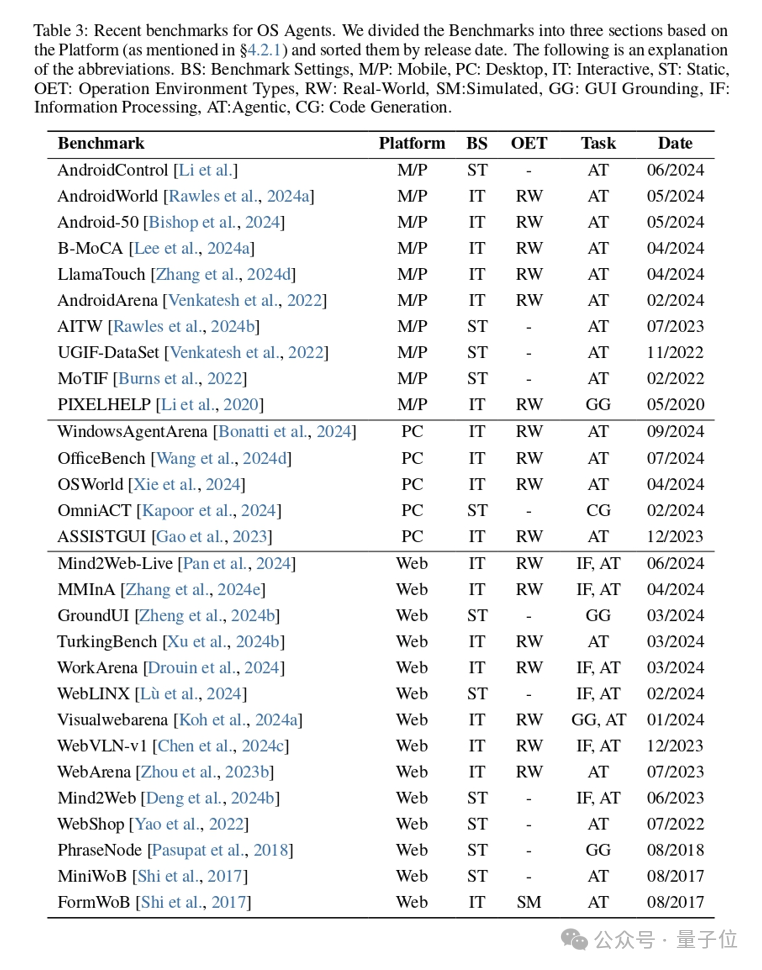 △OS Agents Benchmark近期研究工作總結
△OS Agents Benchmark近期研究工作總結評估協議 (Evaluation Protocol)
操作系統智能體評估的核心可總結為兩個關鍵問題:評估過程應如何進行與需要對哪些方面進行評估。
下面本文將圍繞這兩個問題,闡述操作系統智能體的評估原則和指標。
-
評估原則(Evaluation Principle):OS Agents 的評估結合了多維度的技術方法,提供對其能力與局限性的全面洞察,主要分為兩種類型:1、客觀評估(Objective Evaluation):通過標準化的數值指標,評估智能體在特定任務中的性能。例如,操作的準確性、任務的成功率以及語義匹配的精準度。這樣的評估方法能快速且標準化地衡量智能體的性能;2、主觀評估(Subjective Evaluation):基於人類用戶的主觀感受,評估智能體的輸出質量,包括其相關性、自然性、連貫性和整體效果。越來越多的研究也利用(M)LLM-as-Judge來進行評估,從而提高效率和一致性。
-
評估指標(Evaluation Metric):評估指標聚焦於 OS Agents 的理解、規劃和操作能力,衡量其在不同任務中的表現。主要包括以下兩個方面:1、步驟級指標:評估智能體在每一步操作中的準確性,如任務執行中動作的語義匹配程度、操作準確性等;2、任務級指標:聚焦於整個任務完成情況,包括任務的成功率和完成任務的效率。
評估基準 (Evaluation Benchmark)
為了全面評估 OS Agents 的性能,研究者開發了多種評估基準,涵蓋不同平台、環境設置和任務類別。
這些基準測試為衡量智能體的跨平台適應性、動態任務執行能力提供了科學依據。
評估平台(Evaluation Platform):評估平台構建了集成的評估環境,不同平台具有獨特的挑戰和評估重點,我們將其主要分為三類:移動平台(Mobile)、桌面平台(Desktop)與網頁平台(Web)。
基準設置(Benchmark Setting):該部分將 OS Agents 的評估環境分為兩大類:靜態(Static)環境和交互式(Interactive)環境,並進一步將交互式環境細分為模擬(Simulated)環境和真實世界(Real-World)環境。靜態環境適用於基礎任務的離線評估,而交互式環境(尤其是真實世界環境)更能全面測試OS Agents在複雜動態場景中的實際能力。真實世界環境強調泛化能力和動態適應性,是未來評估的重要方向。
任務(Task):為了全面評估OS Agents的能力,當前的基準測試整合了各種專業化任務,涵蓋從系統級任務(如安裝和卸載應用程序)到日常應用任務(如發送電子郵件和在線購物)。主要可以分為以下三類:1、GUI 定位(GUI Grounding):評估OS Agents將指令轉換為屏幕界面操作的能力,即如何在操作系統中與指定的可操作元素交互;2、信息處理(Information Processing):評估OS Agents高效處理和總結信息的能力,尤其在動態和複雜環境中,從大量數據中提取有用信息;3、智能體任務(Agentic Tasks):評估OS Agents的核心能力,如規劃和執行複雜任務的能力。這類任務為智能體提供目標或指令,要求其在沒有顯式指導的情況下完成任務。
挑戰與未來
本部分討論了 OS Agents 面臨的主要挑戰及未來發展的方向,重點聚焦於安全與隱私(Safety & Privacy)以及個性化與自我進化(Personalization & Self-Evolution)兩個方面。
安全與隱私
安全與隱私是OS Agents開發中必須重視的領域。
OS Agents 面臨多種攻擊方式,包括間接提示注入攻擊、惡意彈出窗口和對抗性指令生成,這些威脅可能導致系統執行錯誤操作或泄露敏感信息。
儘管目前已有適用於LLMs的安全框架,但針對OS Agents的防禦機制仍顯不足。
當前研究主要集中於設計專門應對注入攻擊和後門攻擊等特殊威脅的防禦方案,急待開發全面的且可擴展防禦框架,以提升 OS Agents 的整體安全性和可靠性。
為評估OS Agents在不同場景下的魯棒性,還引入了一些智能體安全基準測試,用於全面測試和改進系統的安全表現,例如ST-WebAgentBench[17]和MobileSafetyBench[18]。
個性化與自我進化
個性化OS Agents需要根據用戶偏好不斷調整行為和功能。
多模態大語言模型正逐步支持理解用戶歷史記錄和動態適應用戶需求,OpenAI的Memory功能[19]在這一方向上已經取得了一定進展。
讓智能體通過用戶交互和任務執行過程持續學習和優化,從而提升個性化程度和性能。
未來將記憶機制擴展到更複雜的形式,如音頻、影片、傳感器數據等,從而提供更高級的預測能力和決策支持。
同時,支持用戶數據驅動的自我優化,增強用戶體驗。
總結
多模態大語言模型的發展為操作系統智能體(OS Agents)創造了新的機遇,使得實現先進AI助手的想法更加接近現實。
本綜述旨在概述OS Agents的基礎,包括其關鍵組成部分和能力。
此外,文章還回顧了構建OS Agents的多種方法,特別關注領域特定的基礎模型和智能體框架。
在評估協議和基準測試中,團隊成員細緻分析了各類評估指標,並且將基準測試從環境、設定與任務進行分類。
展望未來,團隊明確了需要持續研究和關注的挑戰,例如安全與隱私、個性化與自我進化等。這些領域是進一步研究的重點。
本綜述總結了該領域的當前狀態,並指出了未來工作的潛在方向,旨在為OS Agents的持續發展貢獻力量,並增強其在學術界和工業界的應用價值與實際意義。
如有錯誤,歡迎大家批評指正,作者也表示,期待各位同行朋友交流討論!
論文鏈接:https://github.com/OS-Agent-Survey/OS-Agent-Survey
項目主頁:https://os-agent-survey.github.io/
參考文獻:
[1]Apple Inc. Siri – apple, 2024. https://www.apple.com/siri/
[2]Microsoft Research. Cortana research – microsoft research, 2024. https://www.microsoft.com/en-us/research/group/cortana-research/
[3]Google. Google assistant, 2024. https://assistant.google.com/
[4]Google. Gemini – google. https://gemini.google.com/
[5]OpenAI. Home – openai. https://openai.com/
[6]xAI. x.ai. https://x.ai/
[7]01.AI. 01.ai. https://www.lingyiwanwu.com/
[8]Anthropic. Anthropic. https://www.anthropic.com/
[9]Chatbot arena: An open platform for evaluating llms by human preference, 2024. https://arxiv.org/abs/2403.04132
[10]Anthropic. 3.5 models and computer use – anthropic, 2024a. https://www.anthropic.com/news/3-5-models-and-computer-use
[11]Apple. Apple intelligence, 2024. https://www.apple.com/apple-intelligence/
[12]Autoglm: Autonomous foundation agents for guis. https://arxiv.org/abs/2411.00820
[13]Google DeepMind. Project mariner, 2024. https://deepmind.google/technologies/project-mariner/
[14]Anthropic. Claude model – anthropic, 2024b. https://www.anthropic.com/claude
[15]Os-atlas: A foundation action model for generalist gui agents. https://arxiv.org/abs/2410.23218
[16]Os-copilot: Towards generalist computer agents with self-improvement. https://arxiv.org/abs/2402.07456
[17]St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents, 2024. http://arxiv.org/abs/2410.06703
[18]Mobilesafetybench: Evaluating safety of autonomous agents in mobile device control, 2024. https://arxiv.org/abs/2410.17520^Memory and new controls for ChatGPT. https://openai.com/index/memory-and-new-controls-for-chatgpt/