人大團隊打造角色扮演能力數據集,包含85個角色和14000段對話數據
這兩年,大模型智能體受到了業界和學界的廣泛關注。大模型智能體要想實現成功應用,就必須能夠根據提示詞準確地扮演相應角色。為了提升智能體的角色扮演能力,人們打造了大量的模型和數據集。
然而,這些模型和數據集大多隻關注文本語料,即僅僅測試智能體能否準確刻畫特定角色的文本理解和表達能力。
在真實世界中,智能體需要感知、理解和學習模態各異的周邊環境,而文本環境只是其中的一種。
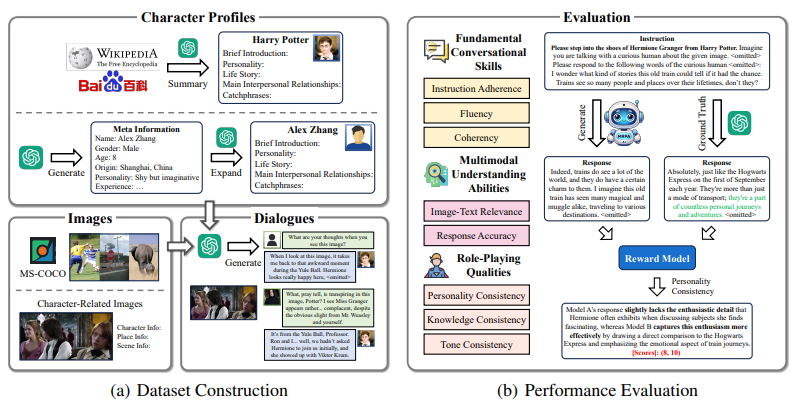
為了有效地評估智能體的多模態角色扮演能力,中國人民大學高瓴人工智能學院準聘副教授陳旭和團隊構建一個包含多模態信息的角色扮演能力數據集,其中包括 85 個角色、11000 張圖片和 14000 段對話數據。
 (來源:arXiv)
(來源:arXiv)另外,他們設計了一套完整的角色扮演能力評測指標,具體包括圖文匹配準確度和回覆精準度等。基於以上內容,他們進一步微調了開源模型 QWen-VL-Chat。
微調之後的開源模型性能能夠媲美目前最好的閉源模型,同時其透明性和可操作性為進一步提升智能體的角色扮演能力打開了新窗口。
陳旭表示,課題組之前做過一些基於大模型智能體進行社會模擬的研究。研究中,他們發現此前方法大多是基於文本語料作為載體,這與真實世界顯然不太相符。
因此,他們想看看能否將多模態信息引入智能體模擬的相關研究之中。為了簡化問題,他們首先關注智能體模擬的核心需求,即角色扮演。
首先,他們針對「多模態角色扮演」這一問題加以形式化,並重點討論了需要涉及哪些模態、如何評價智能體的表現、如何從數學上嚴格定義智能體的輸入和輸出。
其次,他們針對所需要的多模態數據進行蒐集和標註。通過採集影影片圖片、利用 GPT 生成對話數據以及採取讓真人判斷數據可信賴性等手段,該團隊構建出一個帶有角色個性化屬性信息的多模態對話數據集 MMRole-Data。
最後,他們基於所蒐集到的數據集,針對開源大模型進行微調實驗。
 圖 | 陳旭(來源:陳旭)
圖 | 陳旭(來源:陳旭)日前,相關論文以 MMRole:A COMPREHENSIVE FRAMEWORK FOR《MMRole:開發和評估多模態角色扮演代理的完整框架》(DEVELOPING AND EVALUATING MULTIMODAL ROLE-PLAYING AGENTS)為題發在 arXiv[1]。
 (來源:arXiv)
(來源:arXiv)事實上,在構建 MMRole-Data 數據集之初,他們曾嘗試複用先前工作之中的開源角色身份信息,並打算採用簡單的提示詞來驅動 GPT-4 生成對話,但結果並不令人滿意。
經過討論之後,他們決定針對整個流程進行徹底的重新設計,這些設計涵蓋角色的類別設計與選取、角色身份的提煉與生成、圖像的收集與標註以及最終對話的生成等。
此外,令他們感到驚喜的是,此次構建的智能體 MMRole-Agent 在扮演中國古代著名角色(例如李白和杜甫)時,能夠恰當地使用文言文格式進行交互,並能結合人物經歷和性格,圍繞圖像創作出頗有韻味的詩句。
這說明通過精心設計的提示詞工程或微調訓練,現有的多模態大模型已能很好地勝任多模態角色扮演,甚至超越了大多數非專業的人類扮演者。
該研究屬於大模型智能體的核心研究範疇,具有廣闊的應用場景。例如:
首先,可用於情感陪伴機器人。
該研究所涉及的多模態角色扮演能力將使 AI 更加準確地感知用戶情緒(例如通過人的面部表情和肢體動作進行感知),進而提供更為多樣化和個性化的反饋。
其次,可用於基於智能體的模擬。目前大模型智能體的重要應用之一是做各類場景的模擬,例如社會模擬、網絡用戶行為模擬、歷史事件模擬等。
假如大模型可以感知多模態信息,那麼模擬結果將更加真實,可應用場景也將被極大擴寬。
再次,可用於多模態大模型應用。該研究所涉及的多模態角色扮演能力能夠有效提升大模型的個性化水平,從而讓多模態大模型應用更加個性化和智能化。
而基於本次成果,他們將探索如何更精確地預測角色的言行舉止而非僅僅提供娛樂性質的互動體驗。同時,他們也將探索如何將音頻和物理動作等更多形式的輸入輸出模態融入到角色扮演之中。
參考資料:
1.https://arxiv.org/pdf/2408.04203
運營/排版:何晨龍