剛拿下NeurIPS最佳論文,字節就開源VAR文生圖版本,拿下SOTA擊敗擴散模型
自回歸文生圖,迎來新王者——
新開源模型Infinity,字節商業化技術團隊出品,超越Diffusion Model。

值得一提的是,這其實是從前段時間斬獲NeurIPS最佳論文VAR衍生而來的文生圖版本。

在預測下一級解像度的基礎上,Infinity用更加細粒度的bitwise tokenizer建模圖像空間。同時他們將詞表擴展到無窮大,增大了Image tokenizer的表示空間,大大提高了自回歸文生圖的上限。他們還將模型大小擴展到20B。
結果,不僅在圖像生成質量上直接擊敗了Stabel Diffusion3,在推理速度上,它完全繼承了VAR的速度優勢,2B模型上比同尺寸SD3快了3倍,比Flux dev快14倍,8B模型上比同尺寸的SD3.5快了7倍。

目前模型和代碼都已開源,也提供了體驗網站。
來看看具體細節。
自回歸文生圖新王者
在過去自回歸模型和擴散模型的對比中,自回歸模型廣受詬病的問題是生成圖像的畫質不高,缺乏高頻細節。
在這一背景下,Infinity生成的圖像細節非常豐富,還能夠生成各種長寬比圖像,解掉了大家過去一直疑慮的VAR不支持動態解像度的問題。
具體性能上面,作為純粹的離散自回歸文生圖模型,Infinity在一眾自回歸方法中一鳴驚人,遠遠超過了HART、LlamaGen、Emu3等方法。
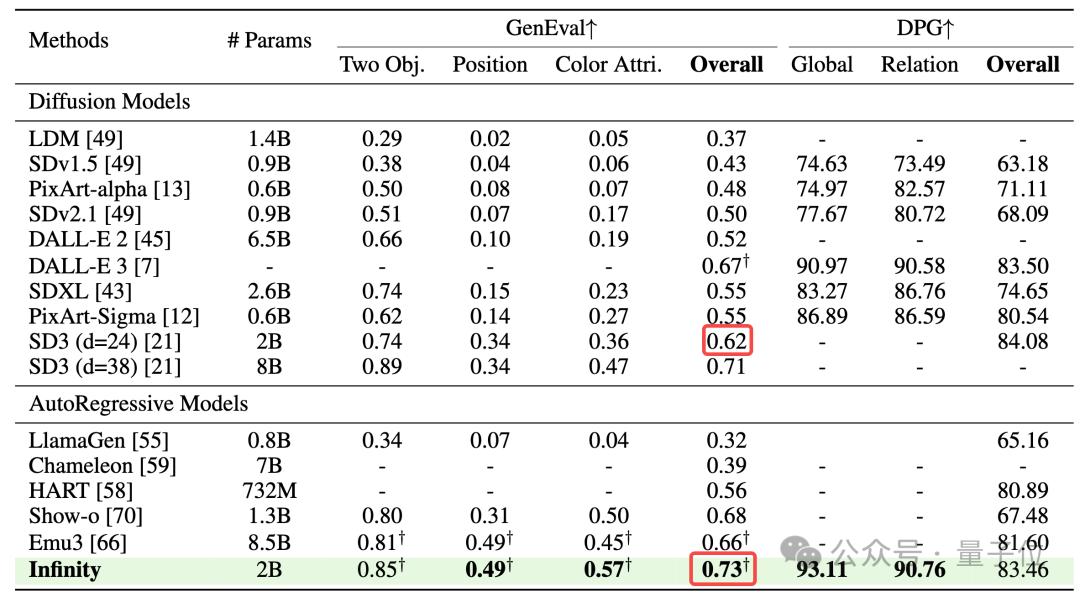
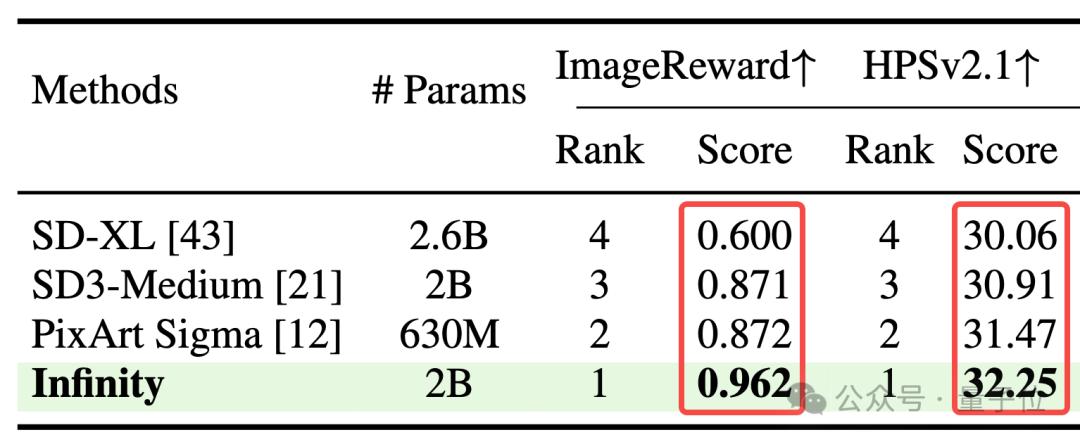
與此同時,Infinity也超過了SDXL,Stable diffusion3等Diffusion路線的SOTA方法。
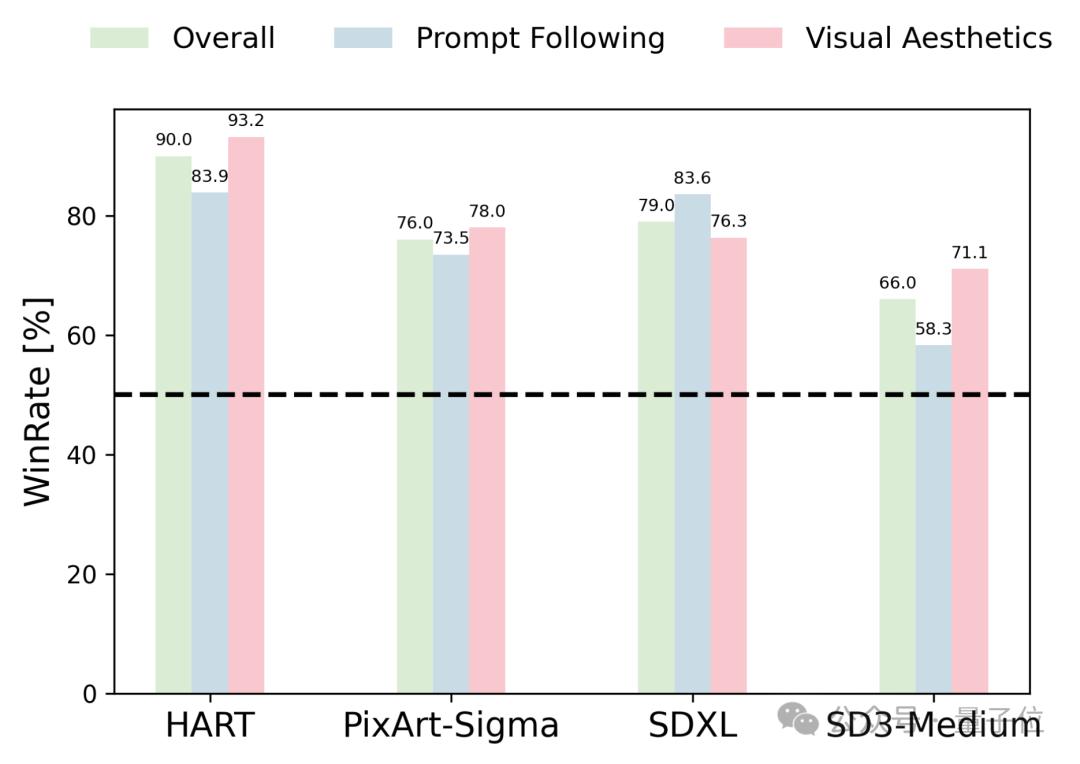
人類評測上,用戶從畫面整體、指令遵循、美感三個方面對於Infinity生成圖像和HART、PixArt-Sigma、SD-XL、SD3-Meidum生成圖像進行了雙盲對比。
其中HART是一個同樣基於VAR架構,融合了diffusion和自回歸的方法。PixArt-Sigma、SD-XL、SD3-Meidum是SOTA的擴散模型。
Infinity以接近90%的beat rate擊敗了HART模型。顯示了Infinity在自回歸模型中的強勢地位。
此外,Inifnity以75%、80%、65%的beat rate擊敗了SOTA的擴散模型如PixArt-Sigma、SD-XL、SD3-Meidum等,證明了Infinity能夠超過同尺寸的擴散模型。
那麼,這背後具體是如何實現的?
Bitwise Token自回歸建模提升了模型的高頻表示
大道至簡,Infinity的核心創新,就是提出了一個Bitwise Token的自回歸框架——
拋棄原有的「Index-wise Token」,用+1或-1構成的細粒度的「Bitwise Token」預測下一級解像度。
在這個框架下,Infinity表現出很強的scaling特性,通過不斷地scaling視覺編碼器(Visual Tokenizer)和transformer,獲得更好的表現。
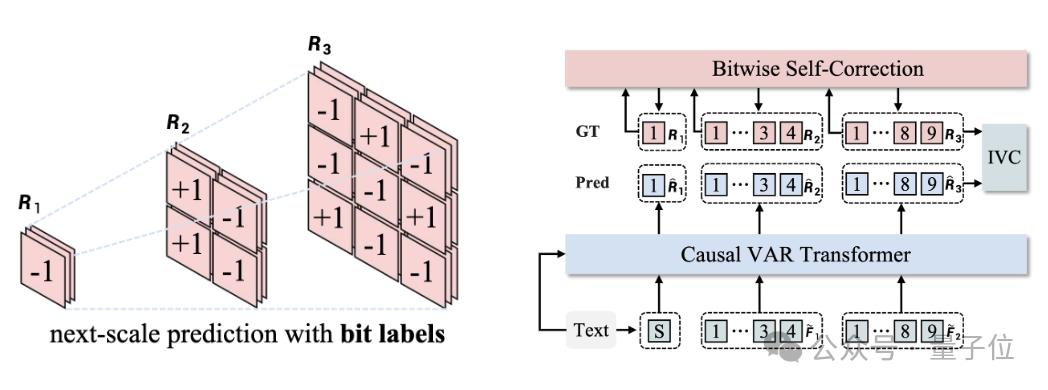
在Bitwise Token自回歸框架中,關鍵技術是一個多尺度的比特粒度視覺編碼器(Visual Tokenizer)。
它將H×W×3大小的圖像編碼、量化為多尺度的特徵:1×1×d,2×2×d,…,h×w×d。其中d是視覺編碼器的維度,每一維是+1或-1。詞表的大小是2d。過去的方法中,會繼續將d維的特徵組合成一個Index-wise Token(索引的範圍是0~2d-1,用這個Index-wise Token作為標籤進行多分類預測,總共類別是詞表大小,即2d。
Index-wise Token存在模糊監督的問題。如下圖所示,當量化前的連續特徵發生微小擾動後(0.01變成-0.1),Index-wise Token的標籤會發生劇烈變化(9變成1),使得模型優化困難。
而Bitwise Token僅有一個比特標籤發生翻轉,其他比特標籤仍能提供穩定監督。相比於Index-wise Token,Bitwise Token更容易優化。
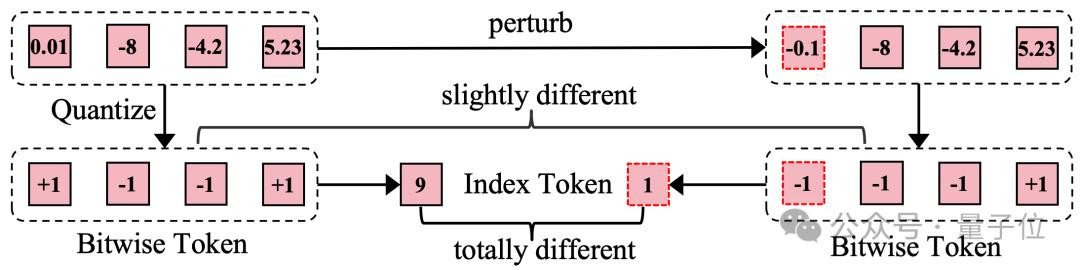
研究人員在相同的實驗設置下對比了Index-wise Token和Bitwise Token。
結果顯示,預測Bitwise Token能夠讓模型學到更細粒度的高頻信號,生成圖像的細節更加豐富。

無窮大詞表擴展了Tokenizer表示空間
從信息論的角度來看,擴散模型採用的連續Visual Tokenizer表示空間無窮大,而自回歸模型採用的離散Visual Tokenizer表示空間有限。
這就導致了自回歸採用的Tokenizer對於圖像的壓縮程度更高,對於高頻細節的還原能力差。為了提升自回歸文生圖的上限,研究人員嘗試擴大詞表以提升Visual Tokenizer的效果。
但是基於Index-wise Token的自回歸框架非常不適合擴大詞表。基於Index-wise Token的自回歸模型預測Token的方式如下圖左邊所示,模型參數量和詞表大小正相關。
當d=32的時候,詞表大小為232,預測Index-wise Token的transformer分類器需要有2048×232=8.8×1012=8.8T的參數量!
光一個分類器的參數量就達到了50個GPT3的參數量,這種情況下擴充詞表到無窮大顯然是不可能的。
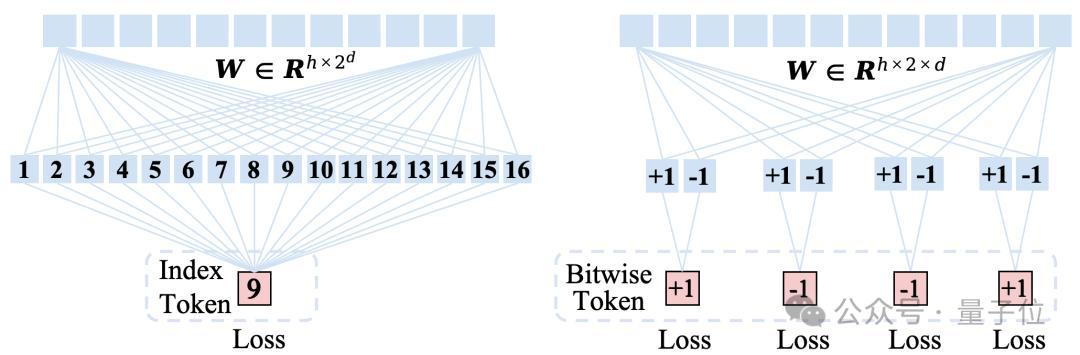
研究人員的解決方法簡單粗暴,如上圖右邊所示,丟掉索引,直接預測比特!有了Bitwise Token自回歸建模後,研究人員採用d個+1或-1的二分類器,並行地預測下一級解像度+1或-1的比特標籤。做出這樣的改變後,參數量一下從8.8T降到了0.13M。所以說,採用Bitwise Token建模自回歸後,詞表可以無限大了。
有了無限大詞表,離散化的Visual Tokenizer落後於連續的問題似乎沒有這麼嚴重了:
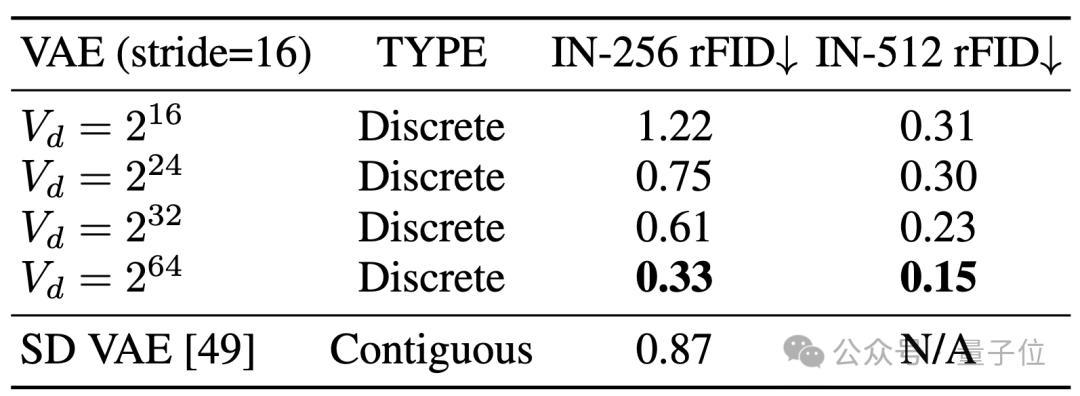
如上表所示,當詞表大小放大到後,離散的視覺編碼器在ImageNet上重建的FID居然超過了Stable Diffusion提出的連續的VAE。
從可視化效果來看,無限大詞表(Vd=232),相比於小詞表,對於高頻細節(如上圖中的人物眼睛、手指)重建效果有質的提升
Model Scaling穩步提升效果
解決了製約生成效果天花板的視覺編碼器的問題後,研究人員開始了縮放詞表和縮放模型的一系列實驗。
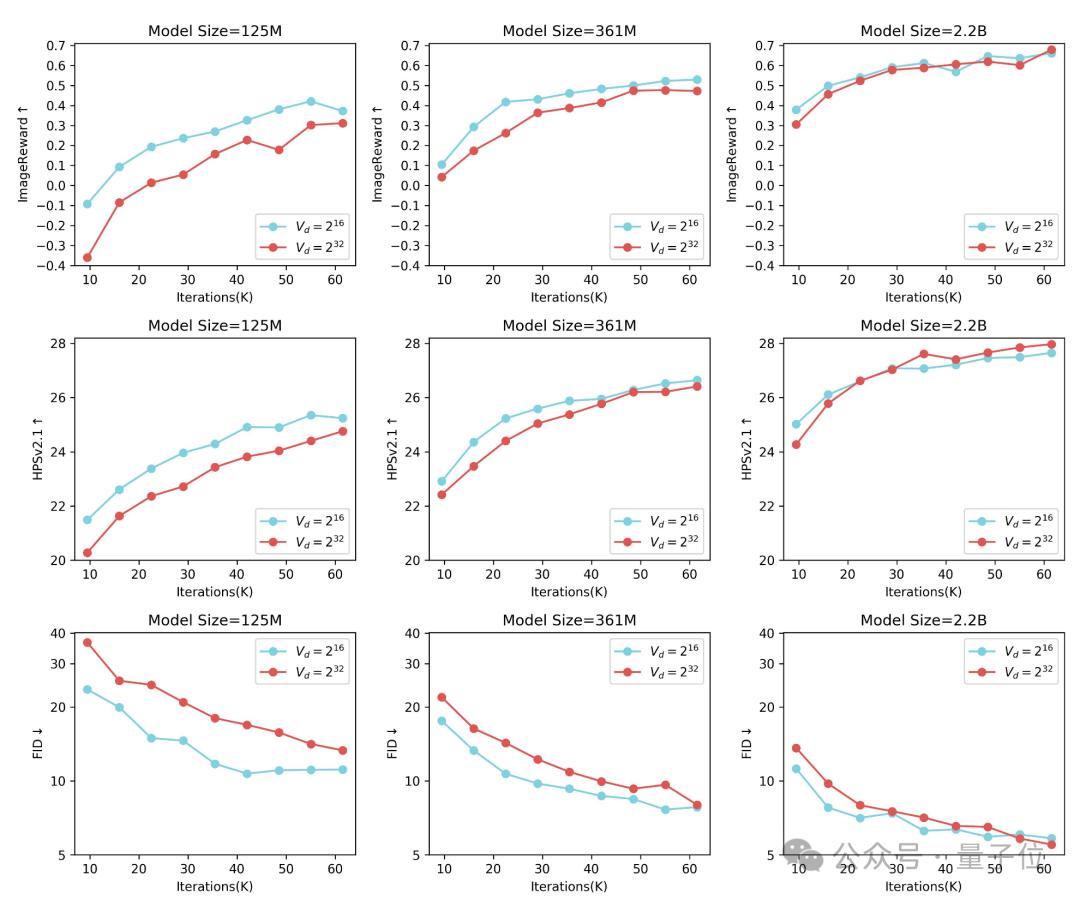
研究發現,對於125M的小模型,使用Vd=216的小詞表,相比於Vd=232的大詞表,收斂的更快更好。
但是隨著模型的增大,大詞表的優勢逐漸體現出來。當模型增大到2B並且訓練迭代超過50K以後,大詞表取得了更好的效果。最終Infinity採取Vd=232的大詞表,考慮到232已經超過了int32的數值範圍,可以認為是無窮大的數,這也是Infinity的命名由來。
總結來看,(無窮)大詞表加大模型,加上充分的訓練後,效果要明顯好於小詞表加大模型。
除了scaling詞表以外,研究人員還做了對Infinity模型大小的scaling實驗。
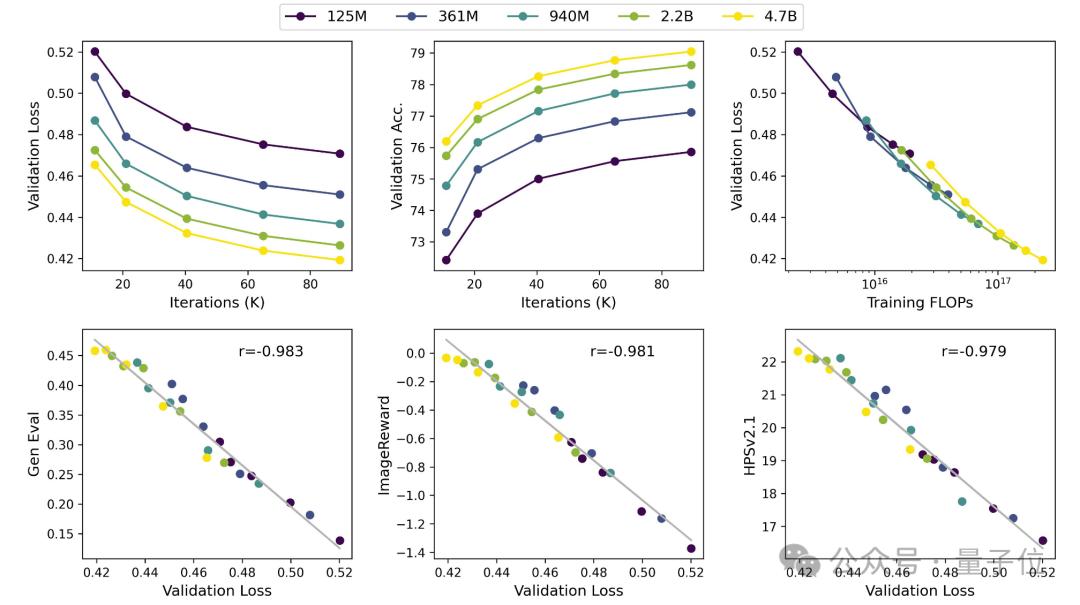
他們在完全相同的實驗設定下比較了125M、361M、940M、2.2B、4.7B五個不同尺寸大小的模型。
可以看到,隨著模型的增大和訓練資源的增加,驗證集損失穩步下降,驗證集準確率穩定提升。另外,研究人員發現驗證集Loss和各項測試指標存在很強的線性關係,線性相關係數高達0.98。
下圖每個九宮格對應同一個提示詞在不同模型大小、不同訓練步數的生成圖像。
從上往下分別是:逐漸增大模型規模,對應125M、1B、5B模型生成的圖像。
從左往右分別是模型訓練的步數逐漸增多後生成的圖像。
我們能明顯看出:Infinity有著良好的scaling特性,更大的模型、更多的訓練,能夠生成語義結構、高頻細節更好的圖像。

另外Infinity還提出了比特自我矯正技術,讓視覺自回歸文生圖模型具有了自我矯正的能力,緩解了自回歸推理時的累計誤差問題。

Infinity還能夠生成各種長寬比圖像,解決了VAR不支持動態解像度的問題。
下圖列出了Infinity和其他文生圖模型對比的例子。
可以看到,Infinity在指令遵循,文本渲染、畫面美感等方面都具有更好的表現。

除了效果以外,Infinity完全繼承了VAR預測下一級解像度的速度優勢,相比於擴散模型在推理速度上具有顯著的優勢。
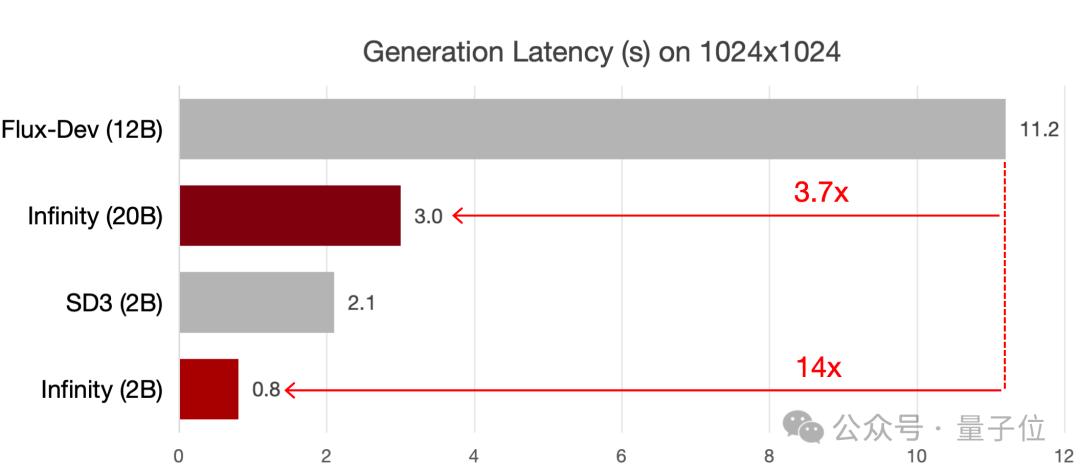
2B模型生成1024×1024的圖像用時僅為0.8s,相比於同尺寸的SD3-Medium提升了3倍,相比於12B的Flux Dev提升了14倍。8B模型比同尺寸的SD3.5快了7倍。20B 模型生成1024×1024的圖像用時3s,比12B的Flux Dev還是要快將近4倍。
目前,在GitHub倉庫中,Infinity的訓練和推理代碼、demo、模型權重均已上線。
Infinity 2B和20B的模型都已經開放了網站體驗,感興趣的同學可以試一試效果。
開源地址:https://github.com/FoundationVision/Infinity
項目頁面:https://foundationvision.github.io/infinity.project/
體驗網站:https://opensource.bytedance.com/gmpt/t2i/invite
本文來自微信公眾號「量子位」,作者:允中,36氪經授權發佈。