DeepSeek-V3或證明Ilya「預訓練終結論」有誤?UC伯克利博士生證明大模型內容可用於訓練新模型
還記得 OpenAI 前首席科學家伊利亞·蘇茨克維(Ilya Sutskever)在 2024 年神經信息處理系統大會(NeurIPS,Neural Information Processing Systems)上的「預訓練即將終結」發言嗎?他之所以這樣說是因為:互聯網上所有有用數據都將被用來訓練大模型。
這個過程也被稱為預訓練,包括 ChatGPT 等在內的大模型均要經過這一步驟才能「出爐」。
不過,由於現有互聯網數據或將被消耗殆盡,因此伊利亞表示這個時代「無疑將結束」。
但是,大多數業界人士並未因此感到恐慌,這是為什麼?答案可以先從最近火到大洋彼岸的中國大模型 DeepSeek V3 說起。
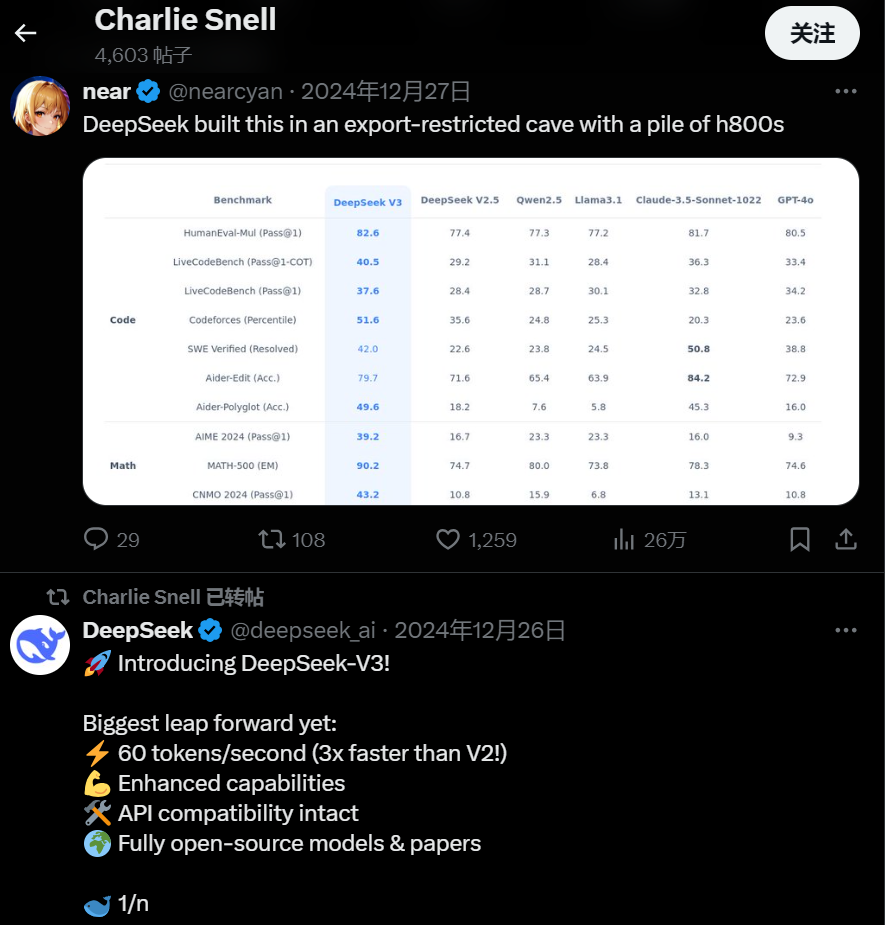 圖 | 查理·斯內爾(Charlie Snell)積極關注 DeepSeek V3 動態(來源:X)
圖 | 查理·斯內爾(Charlie Snell)積極關注 DeepSeek V3 動態(來源:X)曾在Google旗下公司 DeepMind 實習過的美國加州大學伯克利分校博士生查理·斯內爾(Charlie Snell)非常關注 DeepSeek V3,他不僅在 X 上轉發了 DeepSeek V3 的相關內容,還專門問了問 OpenAI 內部人士對於 DeepSeek V3 的看法。
OpenAI 內部人士告訴斯內爾,DeepSeek 團隊可能是第一個複現 OpenAI o1 的團隊,但是 OpenAI 的人也不知道 DeepSeek 是如何實現快速複現的。
美國科技博客 TechCrunch 的一份報告也顯示,DeepSeek 可能使用了 OpenAI o1 的輸出來訓練自己的 AI 模型,更重要的是 DeepSeek V3 在行業基準測試中表現也十分出色。
這說明,如果 OpenAI o1 模型的輸出優於該公司的 GPT-4 模型,那麼理論上 o1 的輸出內容就能被用於訓練新的大模型。
比如說:假設 o1 在特定的 AI 基準上獲得 90% 的分數,如果將這些答案輸入 GPT-4,那麼它的分數也能達到 90%。
假如你有大量的提示詞,那麼就能從 o1 中獲得一堆數據,從而創建大量新的訓練示例(數據),並能基於此預訓練一個新模型,或者繼續訓練 GPT-4 從而讓它變得更好。
因此,斯內爾懷疑 AI 推理模型的輸出已經被用於訓練新模型,並認為這些合成數據很有可能比互聯網上的已有數據更好。
 圖 | 查理·斯內爾(Charlie Snell)
圖 | 查理·斯內爾(Charlie Snell)事實上,2024 年 8 月,當斯內爾還在 DeepMind 實習的時候,他和合作者發了一篇題為《擴展模型測試時間計算比擴展模型參數更有效》(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters)的論文,在這篇論文中斯內爾已經針對「預訓練即將終結」的問題給出瞭解決方案。
研究中,斯內爾等人揭示了測試時間計算(test-time compute)這一策略的好處。測試時間計算策略,是一種通過峰值數據牆(peak-data wall)來讓大模型得到持續迭代的潛在方法。
該技術能將查詢分割成更小的任務,將每個任務都變成能被大模型處理的新提示。
其中,每一步都需要運行一個新請求,在 AI 領域這被稱為推理階段。在一系列的推理中,問題的每個部分都能得到解決。在沒有得到正確內容或沒有得到更好內容之前,模型不會進入下一階段。
研究期間,斯內爾和合作者將額外測試時間計算(additional test-time compute)的輸出用於提煉基礎模型,從而讓模型實現自我改進,借此發現新模型在數學任務和具有明確答案的任務中,表現得比之前的頂級大模型還要好。
因此,假如將這些更高質量的輸出作為新的訓練數據,就能讓已有大模型生成更好的結果,或者直接打造出更好的大模型。
而他當初之所以和合作者開展這項研究,也是發現數據供應有限這一問題阻礙了預訓練的繼續擴展。
他表示,如果能讓大模型使用額外的推理時間計算(extra inference-time compute)並提高其輸出,那麼這就是讓它生成更好的合成數據的一種方式。這就等於開創了一個尋找訓練數據的新來源,或能解決當前的大模型預訓練數據瓶頸問題。
 (來源:arXiv)
(來源:arXiv)那麼,斯內爾具體是如何開展這項研究的?研究中,斯內爾等人針對擴展測試時間計算的不同方法進行了系統分析,旨在進一步提高擴展測試時間計算的效果。
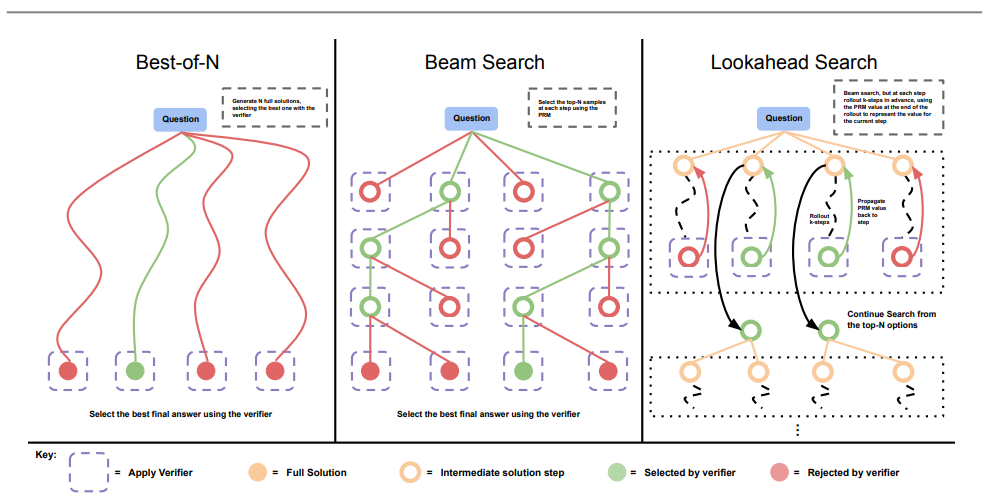
在擴展測試時間計算這一方法中,最簡單的、也是此前被研究得最深入的方法便是「N 選最佳采樣」,即從基礎大模型中「並行」抽樣 N 個輸出,並根據學習到的驗證器或獎勵模型,選擇得分最高的輸出。
然而,這種方法並不是使用測試時間計算來改進大模型的唯一方法。為了瞭解擴展測試時間計算的好處,斯內爾等人使用專門微調的 PaLM-2 模型針對難度較高的 MATH 基準開展實驗。
期間他和合作者用到了如下兩個方法:第一個方法是修改不正確的答案,第二個方法是使用基於過程的獎勵模型來驗證答案中各個步驟的正確性。
通過這兩種方法,斯內爾等人發現特定測試時間計算策略的有效性在很大程度上取決於以下兩點:其一,取決於手頭特定問題的性質;其二,取決於所使用的基礎大模型。
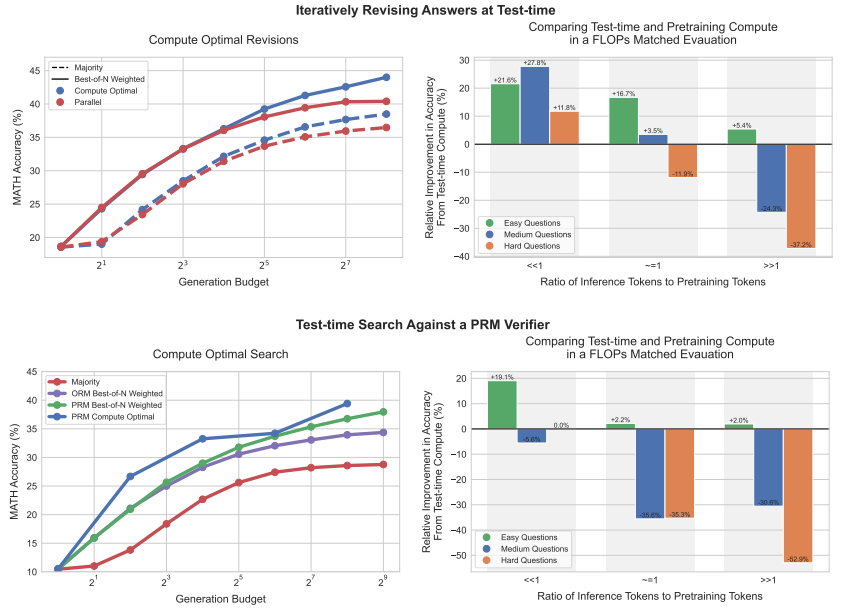
針對測試時間計算擴展策略(test-time compute scaling strategy)加以改進之後,斯內爾等人希望瞭解測試時間計算到底可以在多大程度上替代額外的預訓練。
於是,他和合作者在具有額外測試時間計算的較小模型和預訓練 14 倍大的模型之間進行了浮點運算數匹配比較。
結果發現:無論是在簡單問題、中等難度問題還是在高難問題上,額外的測試時間計算策略都比擴展預訓練方法更加可取。
這說明,與其只是關注擴展預訓練,在某些情況下使用較少的計算針對小模型開展預訓練會更有效,並且可以使用測試時間計算策略來提高模型輸出。
也就是說,擴展測試時間計算已經比擴展預訓練更為可取,並且隨著測試時間策略的成熟,只會取得更多的改進。
從長遠來看,這暗示著未來在預訓練期間花費更少的浮點運算數(算力),而在推理中花費更多的浮點運算數(算力)。
 (來源:arXiv)
(來源:arXiv)無獨有偶,就連微軟 CEO 薩蒂亞·納迪拉維杜華(Satya Nadella)也表達了類似的觀點,他在近期一則影片播客中將推理時間計算策略描述為「另一個擴展定律(scaling law)」。
納迪拉維杜華認為這是一種提高大模型能力的好方法:當進行預訓練的時候,進行測試時間采樣之後,就能創建可以重新用於預訓練的 tokens,從而能夠創建更強大的模型,進而運行推理。
毫無疑問,2025 年,這種方法將接受更多考驗,至於結果如何目前還需要從更多大模型身上加以驗證。
 參考資料:
參考資料:https://www.businessinsider.com/ai-peak-data-google-deepmind-researchers-solution-test-time-compute-2025-1
https://medium.com/@EleventhHourEnthusiast/scaling-llm-test-time-compute-optimally-can-be-more-effective-than-scaling-model-parameters-19a0c9fb7c44
https://arxiv.org/pdf/2408.03314
運營/排版:何晨龍



















