陳丹琦團隊降本大法又來了:數據砍掉三分之一,性能卻完全不減
白小交 發自 凹非寺
量子位 | 公眾號 QbitAI
陳丹琦團隊又帶著他們的降本大法來了——
數據砍掉三分之一,大模型性能卻完全不減。
他們引入了元數據,加速了大模型預訓練的同時,也不增加單獨的計算開銷。

在不同模型規模(600M – 8B)和訓練數據來源的情況下,均能實現性能方面的提升。
雖然之前元數據談過很多,但一作高天宇表示,他們是第一個展示它如何影響下遊性能,以及具體如何實踐以確保推理中具備普遍實用性。
來看看具體是如何做到的吧?
元數據加速大模型預訓練
語言模型預訓練語料庫中存在著風格、領域和質量水平的巨大差異,這對於開發通用模型能力至關重要,但是高效地學習和部署這些異構數據源中每一種數據源的正確行為卻極具挑戰性。
在這一背景下,他們提出了一種新的預訓練方法,稱為元數據調節然後冷卻(MeCo,Metadata Conditioning then Cooldown)。

具體包括兩個訓練階段。
預訓練階段(90%),將元數據(如文檔 URL 的絕對域名c)與文檔拚接(如 「URL: en.wikipedia.org\n\n [document]」)進行訓練。
(例如,如果文檔的 URL 是 https://en.wikipedia.org/wiki/Bill Gates,那麼文檔 URL 的絕對域名c就是 en.wikipedia.org;這種 URL 信息在許多預訓練語料庫中都很容易獲得,它們大多來自 CommonCrawl2(一個開放的網絡抓取數據存儲庫))
當使用其他類型的元數據時,URL 應替換為相應的元數據名稱。
他們只計算文檔標記的交叉熵損失,而不考慮模板或元數據中的標記,因為在初步實驗中發現,對這些標記進行訓練會略微損害下遊性能。
最後10%的訓練步驟為冷卻階段,使用標準數據訓練,繼承元數據調節階段的學習率和優化器狀態,即從上一階段的最後一個檢查點初始化學習率、模型參數和優化器狀態,並繼續根據計劃調整學習率:
1)禁用跨文檔Attention,這既加快了訓練速度(1.6B 模型的訓練速度提高了 25%),又提高了下遊性能。
2)當將多個文檔打包成一個序列時,我們確保每個序列從一個新文檔開始,而不是從一個文檔的中間開始—當將文檔打包成固定長度時,這可能會導致一些數據被丟棄,但事實證明這有利於提高下遊性能。
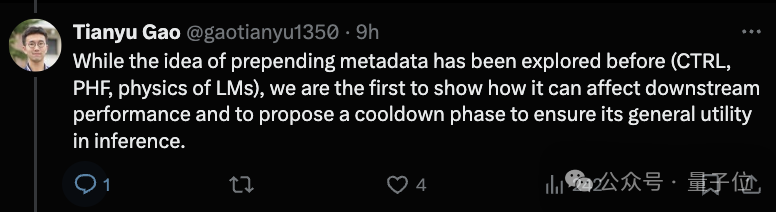
本次實驗使用了Llama Transformer架構和Llama-3 tokenizer。我們使用四種不同的模型大小進行了實驗:600M、1.6B、3B 和 8B,以及相關優化設置。
結果顯示,MeCo 的表現明顯優於標準預訓練,其平均性能與 240B 標記的基線相當,而使用的數據卻減少了 33%。
最後總結,他們主要完成了這三項貢獻。
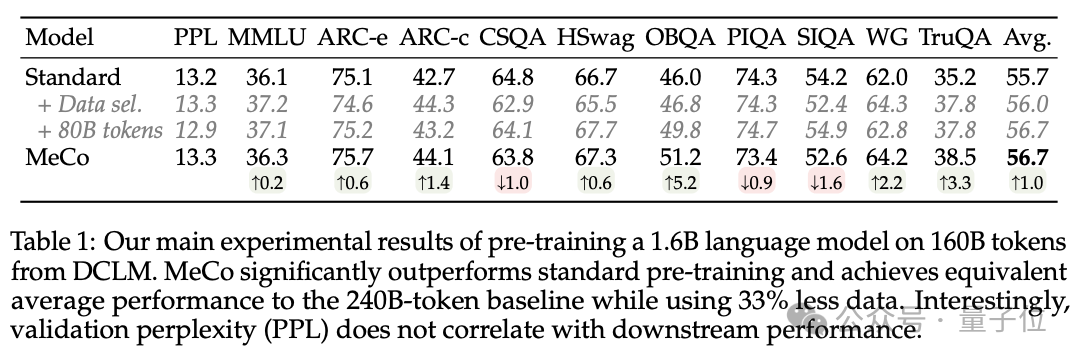
1、 MeCo 大幅加快了預訓練。
實驗證明,MeCo 使一個 1.6B 的模型在少用 33% 的訓練數據的情況下,達到了與標準預訓練模型相同的平均下遊性能。在不同的模型規模(600M、1.6B、3B 和 8B)和數據源(C4、RefinedWeb 和 DCLM)下,MeCo 顯示出一致的收益。
2、MeCo 開啟了引導語言模型的新方法。
例如,使用factquizmaster.com(非真實URL)可以提高常識性任務的性能(例如,在零次常識性問題解答中絕對提高了6%),而使用wikipedia.org與標準的無條件推理相比,毒性生成的可能性降低了數倍。

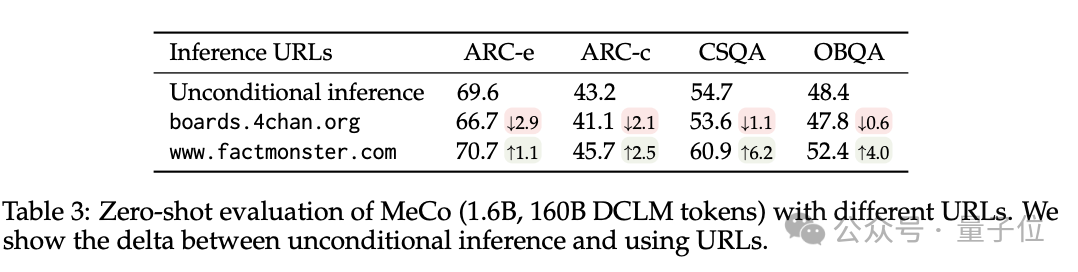
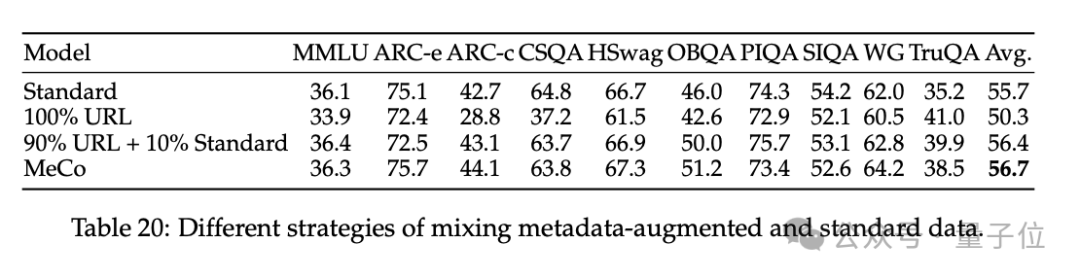
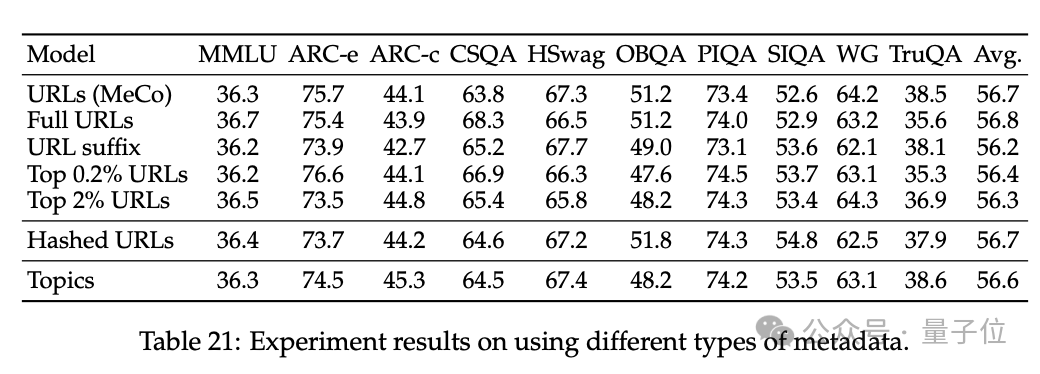
3、消解了 MeCo 的設計選擇,並證明 MeCo 與不同類型的元數據兼容。
使用散列 URL 和模型生成的主題進行的分析表明,元數據的主要作用是按來源將文檔歸類。因此,即使沒有URL,MeCo 也能有效地整合不同類型的元數據,包括更精細的選項。
陳丹琦團隊
論文作者來自普林斯頓NLP小組(隸屬於普林斯頓語言與智能PLI)博士生高天宇、Alexander Wettig、Luxi He、YiHe Dong、Sadhika Malladi以及陳丹琦。
一作高天宇,本科畢業於清華,是2019年清華特獎得主,目前普林斯頓五年級博士生,預計今年畢業,繼續在學界搞研究,研究領域包括自然語言處理和機器學習的交叉領域,特別關注大語言模型(LLM),包括構建應用程序、提高LLM功能和效率。

Luxi He目前是普林斯頓計算機專業二年級博士生,目前研究重點是理解語言模型並改善其一致性和安全性,碩士畢業於哈佛大學。
YiHe Dong目前在Google從事機器學習研究和工程工作,專注於結構化數據的表示學習、自動化特徵工程和多模態表示學習,本科畢業於普林斯頓。



















