Tokenization,再見,Meta提出大概念模型LCM,1B模型干翻70B?
【導讀】Meta提出大概念模型,拋棄token,採用更高級別的「概念」在句子嵌入空間上建模,徹底擺脫語言和模態對模型的製約。
最近,受人類構思交流的高層級思路啟發,Meta AI研究員提出全新語言建模新範式「大概念模型」,解耦語言表示與推理。
網民Chuby興奮地表示:「如果Meta的大概念模型真的有用,那麼同等或更高效率的模型,其規模將更小。比如說1B模型將堪比70B的Llama 4。進步如此之大!」

而在最近的訪談中,Meta的首席科學家Yann LeCun表示下一代AI系統LCM(大概念模型)。新系統將不再單純基於下一個token預測,而是像嬰兒和小動物那樣通過觀察和互動來理解世界。

華盛頓大學計算機科學與工程博士Yuchen Jin,非常認同Meta的新論文,認為新模型增強了其對「tokenization將一去不複返」這一看法的信心,而大語言模型要實現AGI則需要更像人類一樣思考。
甚至有人因此猜測Meta是這次AI競賽的黑馬,他們會用模型給帶來驚喜。

簡而言之,「大概念模型」(LCM)是在「句子表示空間」對推理(reasoning)建模,拋棄token,直接操作高層級顯式語義表示信息,徹底讓推理擺脫語言和模態製約。
具體而言,只需要固定長度的句子嵌入空間的編碼器和解碼器,就可以構造LCM,處理流程非常簡單:
首先將輸入內容分割成句子,然後用編碼器對每個句子進行編碼,以獲得概念序列,即句子嵌入。
然後,大概念模型(LCM)對概念序列進行處理,在輸出端生成新的概念序列。
最後,解碼器將生成的概念解碼為子詞(subword)序列。

論文鏈接:https://arxiv.org/pdf/2412.08821
代碼鏈接:https://github.com/facebookresearch/large_concept_model
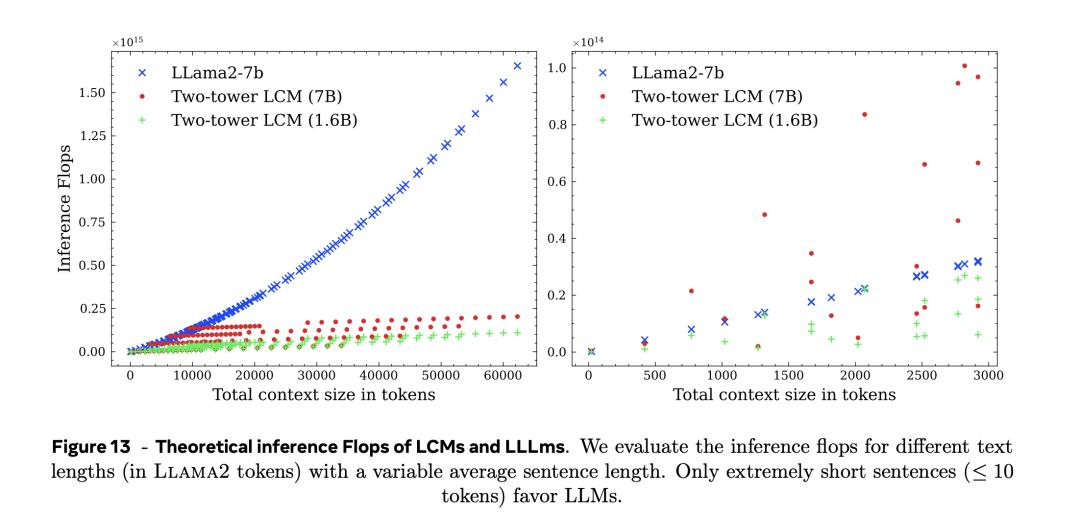
文中對推理(inference)效率的分析頗具看點:在大約1000個token數左右,新模型理論上需要的計算資源就比LLama2-7b具備優勢,且之後隨著下上文中token數越大,新模型優勢越大。具體結果見論文中的圖15,其中的藍色表示LLama2-7b模型,紅色和綠色分別代表新模型;紅色的參數規模為7b,而綠色為1.6b;右圖是左圖在0-3000的token數下的局部放大圖。
新模型的其他亮點如下:
在抽像的語言和模態無關的層面上進行推理,超越token:(1)新方法模擬的是底層推理過程,而不是推理在特定語言中的實例。(2)LCM可同時對所有語言和模態進行訓練,即獲取相關知識,從而有望以無偏見的方式實現可擴展性。目前支持200種語言文本。
明確的層次結構:(1)提高長文輸出的可讀性。(2)方便用戶進行本地交互式編輯。
處理長上下文和長格式輸出:原始的Transformer模型的複雜性隨序列長度的增加而呈二次方增長,而LCM需要處理的序列至少要短一個數量級。
無與倫比的零樣本(zero-shot)泛化能力:LCM可在任何語言或模態下進行預訓練和微調。
模塊化和可擴展性:(1)多模態LLM可能會受到模態競爭的影響,而概念編碼器和解碼器則不同,它們可以獨立開發和優化,不存在任何競爭或干擾。(2)可輕鬆向現有系統添加新的語言或模態。
為什麼需要「概念」?
雖然大語言模型取得了無可置疑的成功和持續不斷的進步,但現有的LLM都缺少人類智能的一個重要的特點:在多級別抽像上顯式的推理和規劃。
人腦並不在單詞層面運作。
比如在解決一項複雜的任務或撰寫一份長篇文檔時,人類通常採用自上而下的流程:首先在較高的層次上規劃整體結構,然後逐步在較低的抽像層次上添加細節。
有人可能會說,LLM是在隱式地學習分層表示,但具有顯式的分層結構模型更適合創建長篇輸出。
新方法將與token級別的處理大大不同,更靠近在抽像空間的(分層)推理。
上下文在LCM所設計的抽像空間內表達,但抽像空間與語言或模態無關。
也就是說在純粹的語義層面對基本推理過程進行建模,而不是對推理在特定語言中的實例建模。
為了驗證新方法,文中將抽像層次限制為2種:子詞token(subword token)和概念。
而所謂的「概念」被定義為整體的不可分的「抽像原子見解」。
在現實中,一個概念往往對應於文本文檔中的一個句子,或者等效的語音片段。
作者認為,與單詞相比,句子才是實現語言獨立性的恰當的單元。
這與當前基於token的LLMs技術形成了鮮明對比。
大概念模型總體架構
訓練大概念模型需要句子嵌入空間的解碼器和編碼器。而且可以訓練一個新的嵌入空間,針對推理架構進行優化。
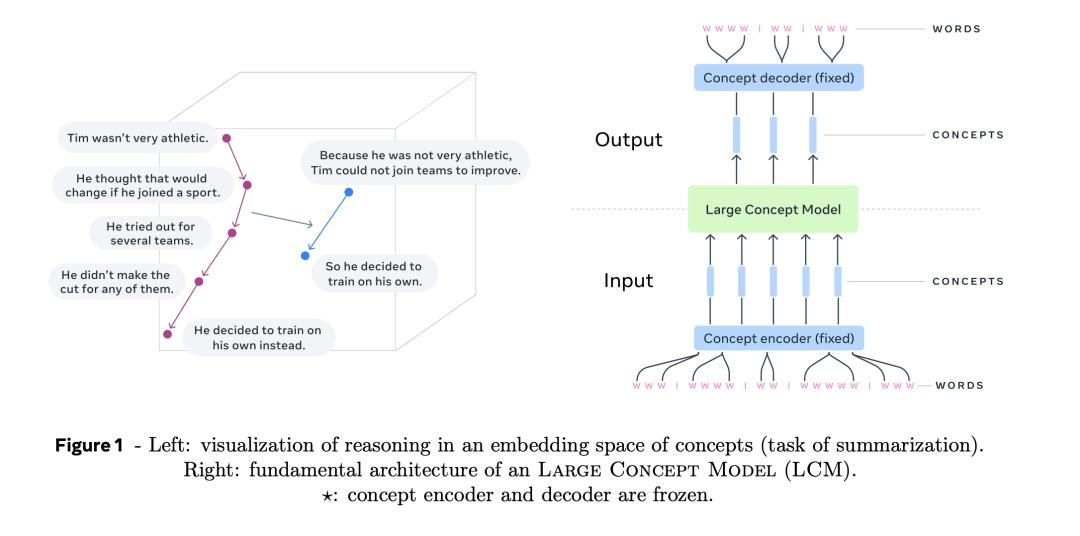
在此研究使用其開源的SONAR作為句子嵌入的解碼器和編碼器。
SONAR解碼器和編碼器(圖中藍色部分)是固定的,不用訓練。
更重要的是,LCM(圖中綠色部分)輸出的概念可以解碼為其他語言或模態,而不必從頭執行整個推理過程。
同樣, 某個特定的推理操作,如歸納總結,可以在任何語言或模態的輸入上以零樣本(zero-shot)模式進行。
因為推理只需操作概念。
總之,LCM既不掌握輸入語言或模態的信息,也不以特定語言或模態生成輸出。
在某種程度上,LCM架構類似於Jepa方法(見下文),後者也旨在預測下一個觀測點在嵌入空間中的表示。

論文鏈接:https://openreview.net/pdf?id=BZ5a1r-kVsf
不過,Jepa更強調以自監督的方式學習表示空間,而LCM則不同,它側重於在現有的嵌入空間中進行準確預測。
模型架構設計原理
SONAR嵌入空間
SONAR文本嵌入空間使用編碼器/解碼器架構進行訓練,以固定大小的瓶頸代替交叉注意力,如下圖2。
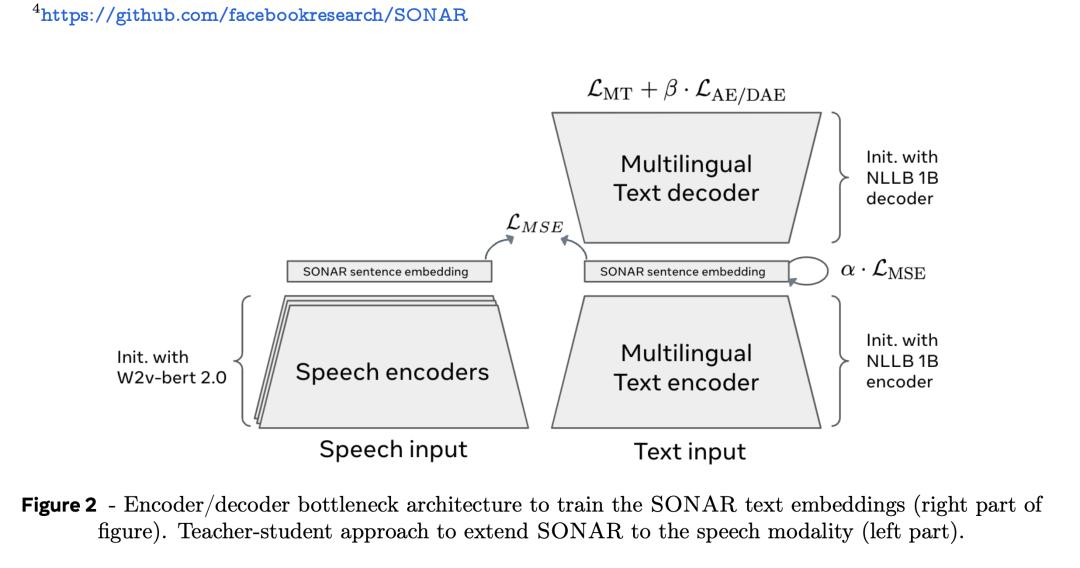
SONAR廣泛用於機器翻譯任務,支持200種語言的文本輸入輸出,76種語言的語音輸入和英文輸出。
因為LCM直接在SONAR概念嵌入上運行,因此可對其支持的全部語言和模態進行推理。
數據準備
為了訓練和評估LCM需要將原始文本數據集轉換為SONAR嵌入序列,每個句子對應嵌入空間的一個點。
然而處理大型文本數據集有幾個實際限制。包括精準的分割句子很難,此外一些句子很長很複雜,這些都會給SONAR嵌入空間的質量帶來負面影響。
文中使用SpaCy分割器(記為SpaCy)和Segment any Text (記為SaT)。
其中SpaCy是基於規則的句子分割器,SaT在token級別預測句子的邊界進行句子分割。
通過限制句子的長度的長度還定製了新的分割器SpaCy Capped和SaT Capped。
好的分割器產生的片段,經過編碼後再解碼而不會丟失信號,可以獲得更高的AutoBLEU分值。
為了分析分割器器的質量,從預訓練數據集中抽取了10k份文件,代表了大約500k個句子。
測試中,使用每個分割器處理文檔,然後對句子進行編碼和解碼,並計算AutoBLEU分數。
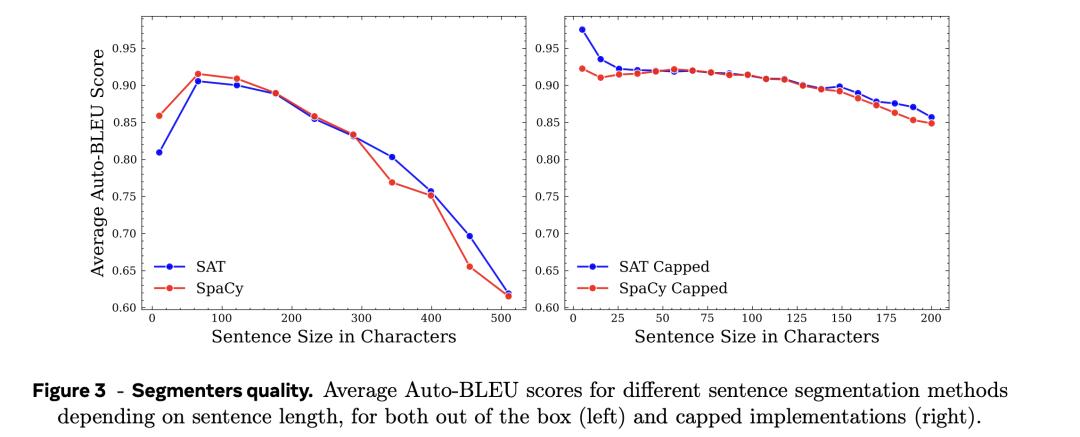 如圖3所示,如果字符上限為200個,與SpaCy Capped相比,SaT Capped方法總是略勝一籌。
如圖3所示,如果字符上限為200個,與SpaCy Capped相比,SaT Capped方法總是略勝一籌。 然而,隨著句子長度增加,兩種分割器都表現出明顯的性能不足。
當句子長度超過250個字符時,這種性能低下的情況尤為明顯,這突出表明了在不設置上限的情況下使用分段器的局限性。
Base-LCM
下個概念預測(next concept prediction)的基線架構是一個標準的只含解碼器的Transformer,它將一系列先行概念(即句子嵌入)轉換為一系列將來的概念。
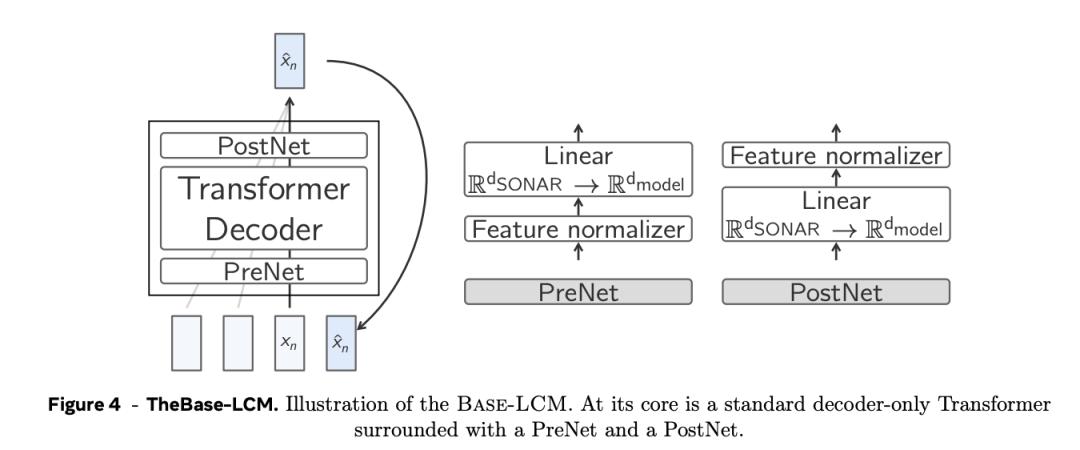
如圖4所示,Base-LCM配備了「PostNet」和「PreNet」。PreNet對輸入的SONAR嵌入進行歸一化處理,並將它們映射到模型的隱藏維度。
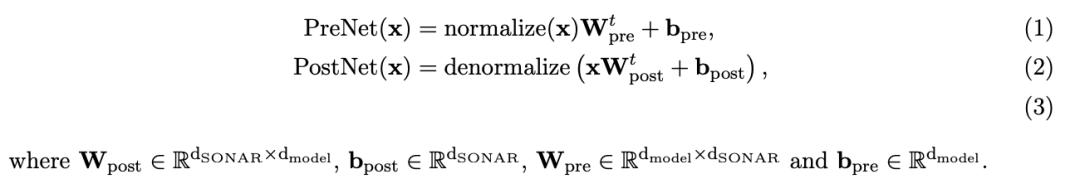
Base-LCM在半監督任務上學習, 模型會預測下一個概念,通過優化預測的下一個概念與真實的下一個概念的距離來優化參數,也就是通過MSE回歸來優化參數。
基於擴散的LCM(Diffusion-based LCM)
基於擴散的LCM是一種生成式潛變量模型,它能學習一個模型分佈pθ ,用於逼近數據分佈q。
與基礎LCM相似,將擴散LCM建模被視為自動回歸模型,每次在文檔中生成一個概念。
大概念模型「Large Concept Model」並不是單純的「next token prediction」, 而是某種「next concept predition」,也就是說下一個概念的生成是以之前的語境為條件的。
具體而言, 在序列的位置n上,模型以之前全部的概念為條件預測在此處某概念的概率, 學習的是連續嵌入的條件概率。
學習連續數據的條件概率,可以借鑒計算機視覺中的擴散模型用於生成句子嵌入。
在文中討論了如何設計不同擴展模型用於生成句子嵌入, 包括不同類型的正向加噪過程和反向去噪過程。
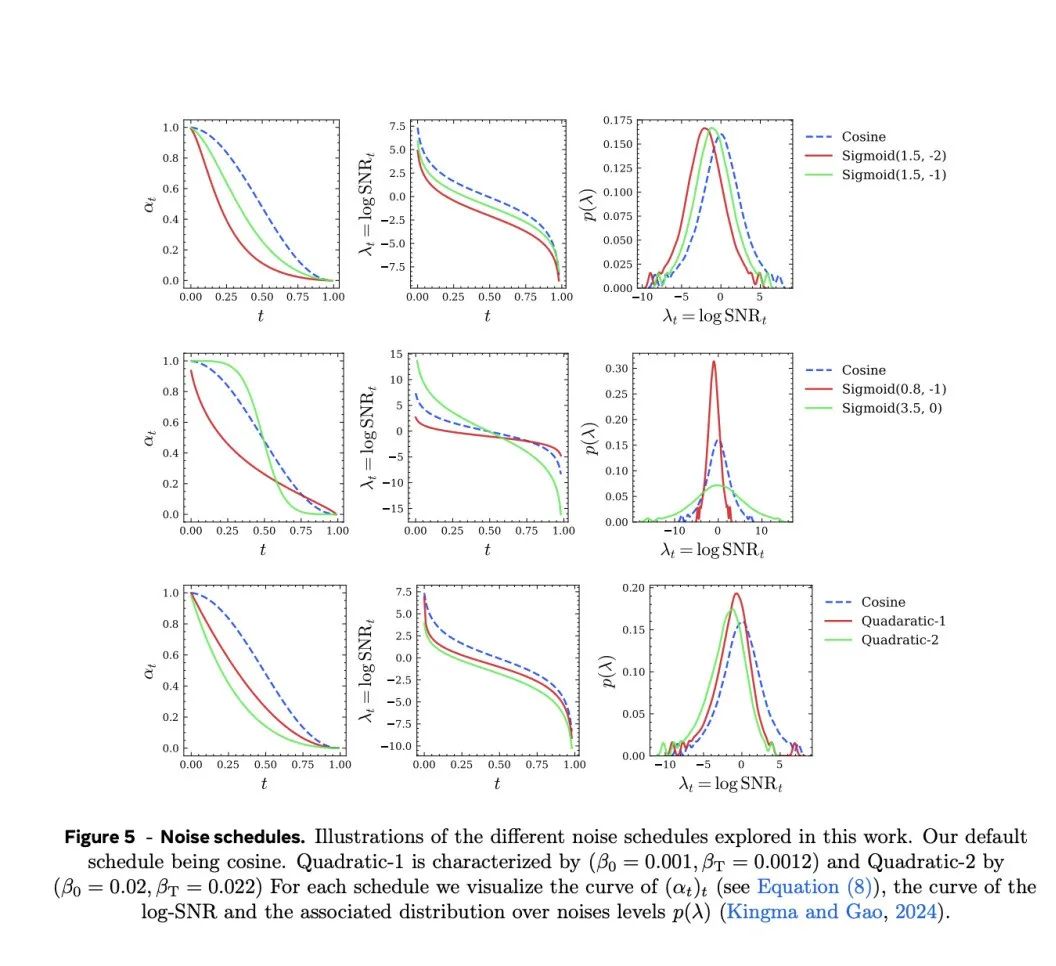
根據不同的方差進度(variance schedule), 生成不同的噪音進度(noise schedule),從而產生對應的前向過程;通過不同的權重策略,反映不同的初始狀態對模型的影響。
文中提出了3類噪音進度:餘弦Cosine,二次函數Quadratic以及Sigmoid。
並提出了重建損失加權策略:
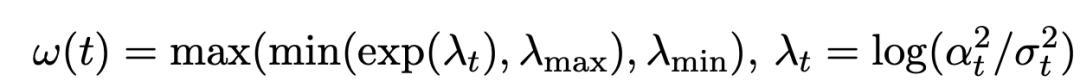
論文詳細討論了不同噪音進度和加權策略策略的影響,結果如下:
單塔擴散LCM(One-Tower Diffusion LCM)
使用圖像領域的擴散加速技巧,也可以加速LCM的推理。
如圖6左圖,單塔擴散LCM由一個Transformer主幹組成,其任務是在給定句子嵌入和噪音輸入的條件下預測乾淨的下一個句子嵌入 。
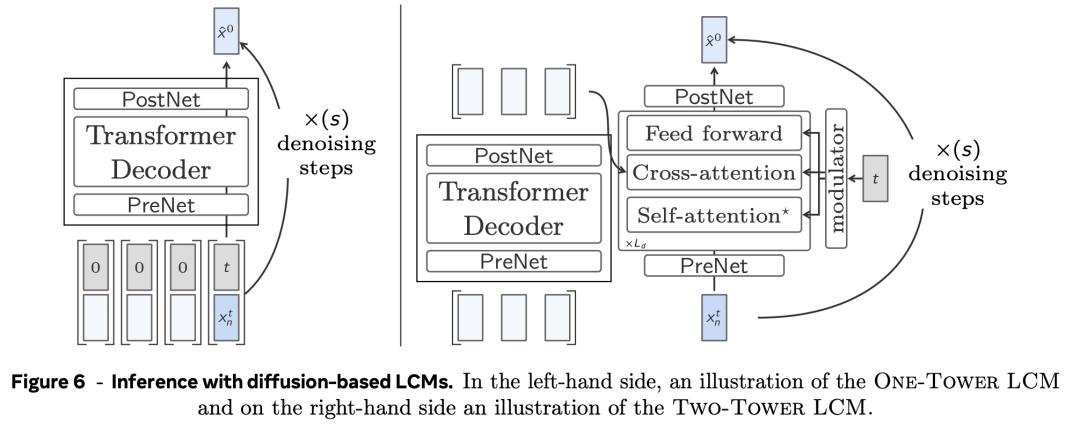
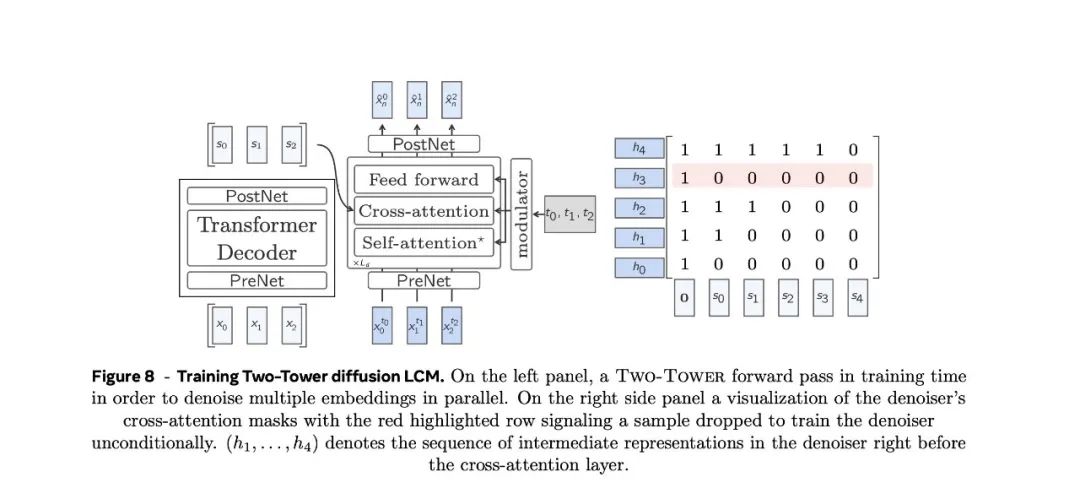
雙塔擴散LCM(Two-Tower Diffusion-LCM)
如圖6右側,雙塔擴散LCM模型將前一語境的編碼與下一嵌入的擴散分開。
第一個模型,即上下文標註模型,將上下文向量作為輸入,並對其進行因果編碼。
也就是說,應用一個帶有因果自關注的純解碼器Transformer。
然後,上下文分析器的輸出結果會被輸入第二個模型,即去噪器(denoiser)。
它通過迭代去噪潛高斯隱變量來預測乾淨的下一個句子嵌入 。
去噪器由一系列Transformer和交叉注意力塊組成,交叉注意力塊用於關注編碼上下文。
去噪器和上下文轉換器共享同一個Transformer隱藏維度。
去噪器中每個Transformer層(包括交叉注意力層)的每個區塊都使用自適應層規範(AdaLN)。
在訓練時,Two-Tower的參數會針對無監督嵌入序列的下一句預測任務進行優化。
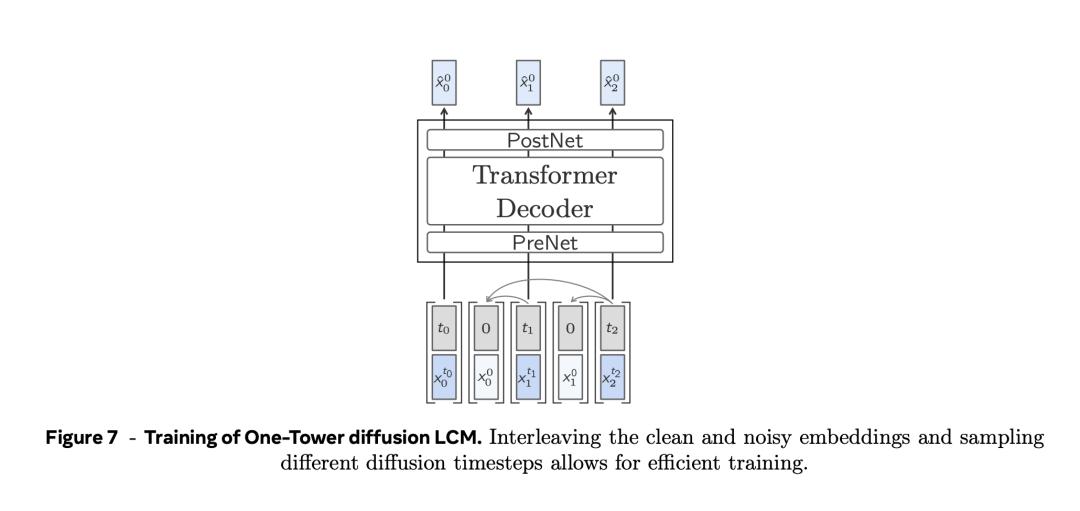
因果嵌入在去噪器中移動一個位置,並在交叉注意力層中使用因果掩碼。在上下文向量中預置一個零向量,以便預測序列中的第一個位置(見圖8)。為了有條件和無條件地訓練模型,為無分類器引導縮放推理做準備,以一定的比率從交叉注意力掩碼中刪除隨機行,並僅以零向量作為上下文對相應位置進行去噪處理。
量化LCM
在圖像或語音生成領域,目前有兩種處理連續數據生成的主要方法:一種是擴散建模,另一種是先對數據進行學習量化,然後再在這些離散單元的基礎上建模。
此外,文本模態仍然是離散的,儘管處理的是SONAR空間中的連續表示,但全部可能的文本句子(少於給定字符數)都是SONAR空間中的點雲,而不是真正的連續分佈。
這些考慮因素促使作者探索對SONAR表示進行量化,然後在這些離散單元上建模,以解決下一個句子預測任務。
最後,採用這種方法可以自然地使用溫度、top-p或top-k采樣,以控制下一句話表示采樣的隨機性和多樣性水平。
可以使用殘差矢量量化作為從粗到細的量化技術來離散SONAR表示。
矢量量化將連續輸入嵌入映射到所學編碼本中最近的元素。
RVQ每次迭代都會使用額外的碼本,對之前量化的殘餘誤差進行迭代量化。
在試驗中從Common Crawl提取的1500萬個英語句子上訓練了RVQ編碼本,使用64個量化器,每個編碼本使用8192個單元。
RVQ的一個特性是,第一個碼本的中心點嵌入累積和是輸入SONAR向量的中等粗略近似。
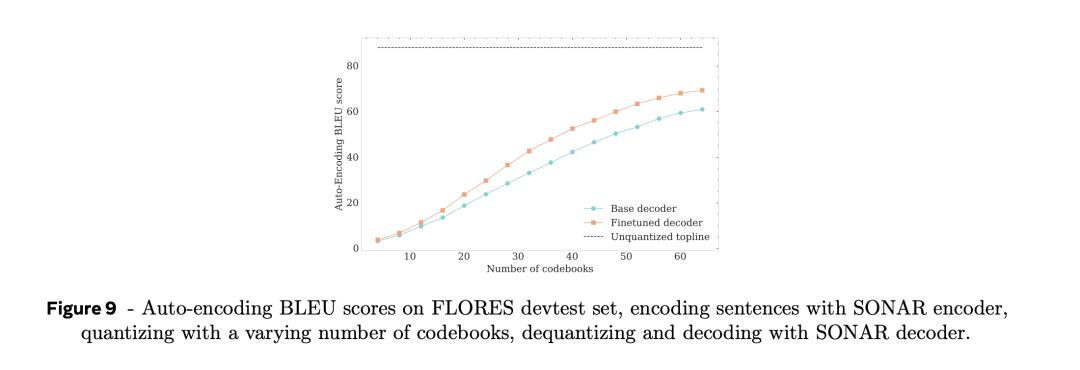
這樣,在使用SONAR文本解碼器解碼量化嵌入之前,可以先探索碼本數量SONAR嵌入自動編碼BLEU分數的影響。
正如圖9中所示, 隨著編碼本數量的增加,自動編碼BLEU不斷提高。
當使用全部64個碼本時,自動編碼BLEU分數約為連續SONAR內嵌時自動編碼BLEU分數的70%。
模型分析
推理效率
作者直接比較了雙塔擴散LCM和LLM的推理計算成本,也就是在不同prompt和輸出總長度(以詞組為單位)的情況下的計算成本。
具體而言,論文中的圖13,作者分析了理論上大概念模型(LCM)和大語言模型的推理需要的每秒浮點運算次數(flops)。
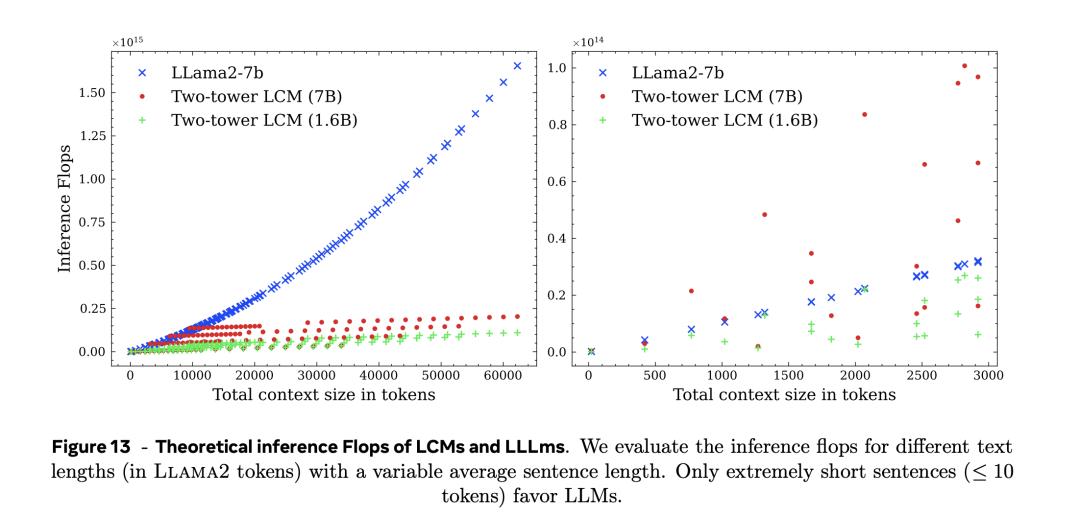
如左圖所示,只有在非常短的句子(小於等於10個token), LLM才有優勢。
在上下文超過10000個token左右時,不論是Two-tower LCM(1.6B)還是Two-tower LCM(7B),token數幾乎不再影響推理需要的計算量。
SONAR 空間的脆弱性
在潛在空間中建模時,主要依靠誘導幾何(L2-距離)。
然而,任何潛在表示的同質歐幾里得幾何都不會完全符合底層文本語義。
嵌入空間中的微小擾動都可能導致解碼後語義信息的急劇丟失,這就是明證。
這種性質被叫做嵌入為「脆弱性」。
因此,需要量化語義嵌入(即SONAR代碼)的脆弱性,以便於瞭解LCM訓練數據的質量以及這種脆弱性如何阻礙LCM的訓練動態。
給定一個文本片段w及其SONAR代碼x=encode(w),將w的脆弱性定義為
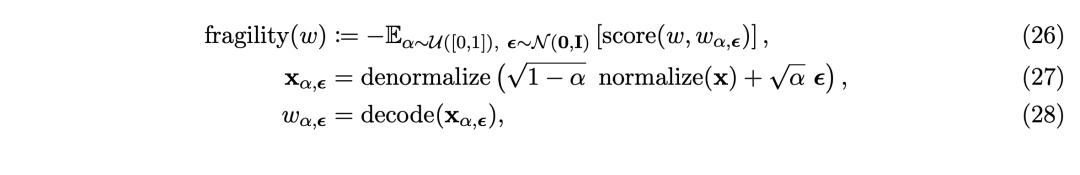
隨機抽取了5000萬個文本片段,並為每個樣本生成了9 個不同噪音水平的擾動。且在實驗中,對於外部餘弦相似度(CosSim)指標,使用mGTE作為外部編碼器。
具體的脆弱性得分結果在圖14中。
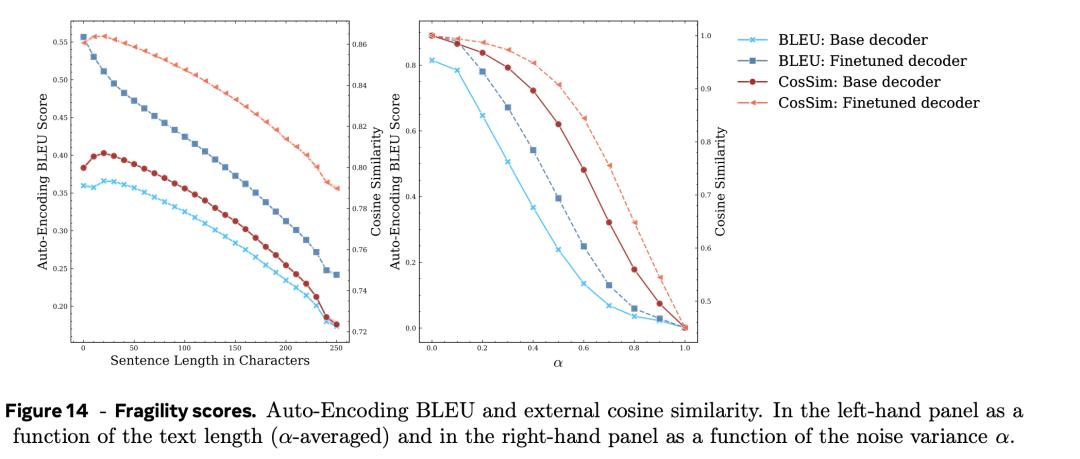 圖14中左圖和右圖分別描繪了BLUE和CosSIM得分隨文本長度和噪聲水平變化的曲線。
圖14中左圖和右圖分別描繪了BLUE和CosSIM得分隨文本長度和噪聲水平變化的曲線。 可以觀察到,BLEU分數的下降速度比餘弦相似度更快。
最重要的是,脆性得分對解碼器的選擇很敏感。具體而言,隨著噪聲量的增加,微調解碼器的自動編碼 BLEU 和餘弦相似度得分的下降速度明顯低於基本解碼器。
還注意到,在平均擾動水平下,總體得分分佈如圖15所示,在SONAR樣本中,脆弱性得分差距很大。
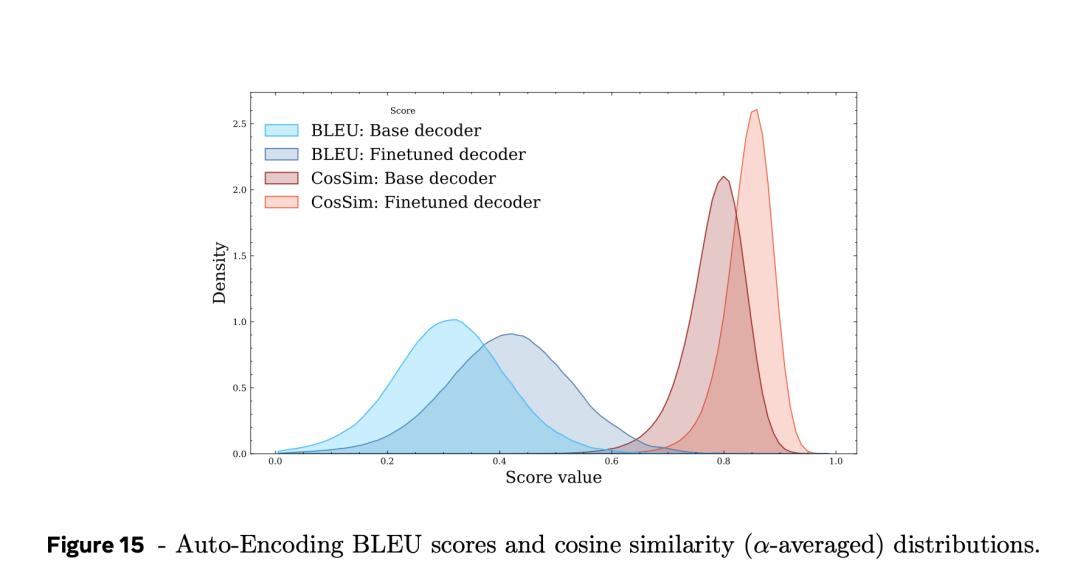
這種差異的原因可能是句子長度。與自動編碼BLEU指標相比(該指標在長句子中僅下降1-2%),脆弱性對句子長度更為敏感,在兩種相似性指標中都下降得更快。
這表明,使用最大句子長度超過250的SONAR和LCM模型會面臨極大的挑戰。另一方面,雖然短句的平均魯棒性更高,但在錯誤的位置拆分長句可能會導致更短但更脆弱的子句。
不同任務的測評
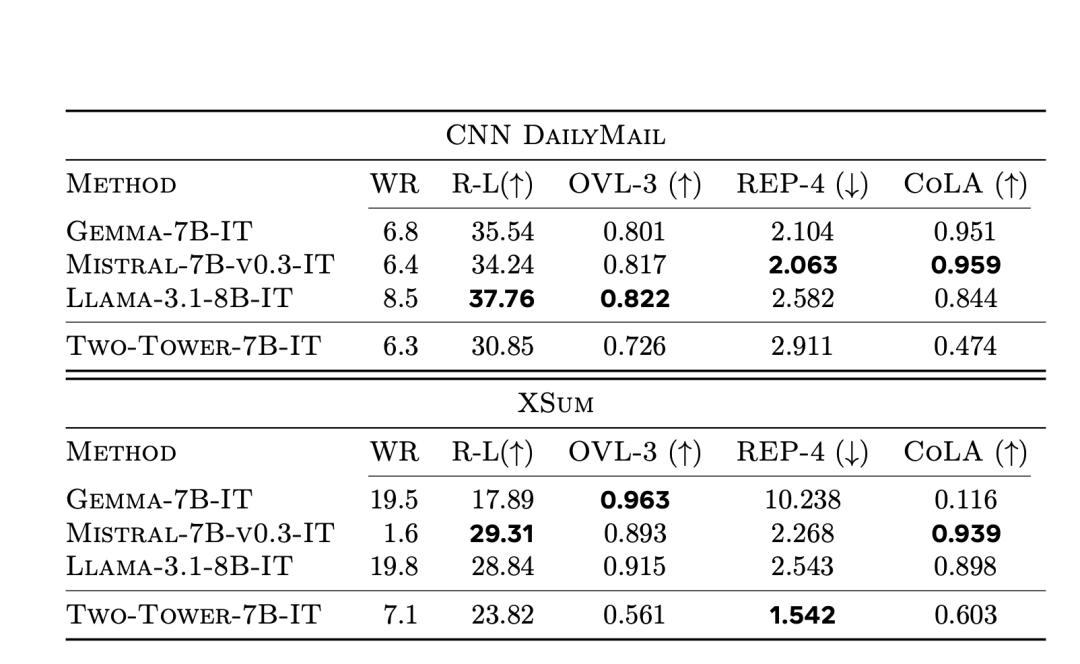
表10列出了不同基線和LCM在摘要任務上的結果,分別包括CNN DailyMail 和 XSum數據集。
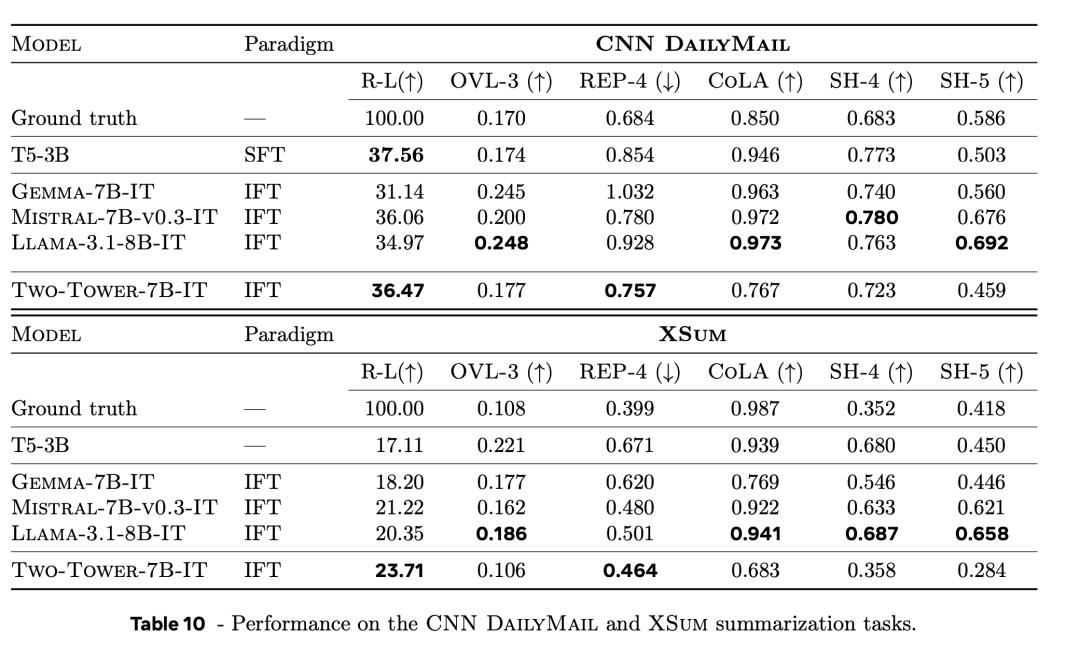
與經過專門調整的LLM(T5-3B)相比,LCM的Rouge-L(表中的R-L列)分數也具有競爭力。
而較低的OVL-3分數則表示,新模型傾向於生成更抽像的摘要,而不是提取性摘要。LCM產生的重覆次數比LLM更少,更重要的是,其重覆率更接近真實的重覆率。
根據CoLA分類器得分,LCM生成的摘要總體上不太流暢。
不過,在該得分上,即使是人工生成摘要的得分也比LLM低。
在來源歸屬(SH-4)和語義覆蓋(SH-5)上也有類似的現象。
這可能是由於基於模型的指標更偏向於LLM生成的內容。
表11列出長文檔總結總結(LCFO.5%、LCFO.10%和LCFO.20%)的結果。
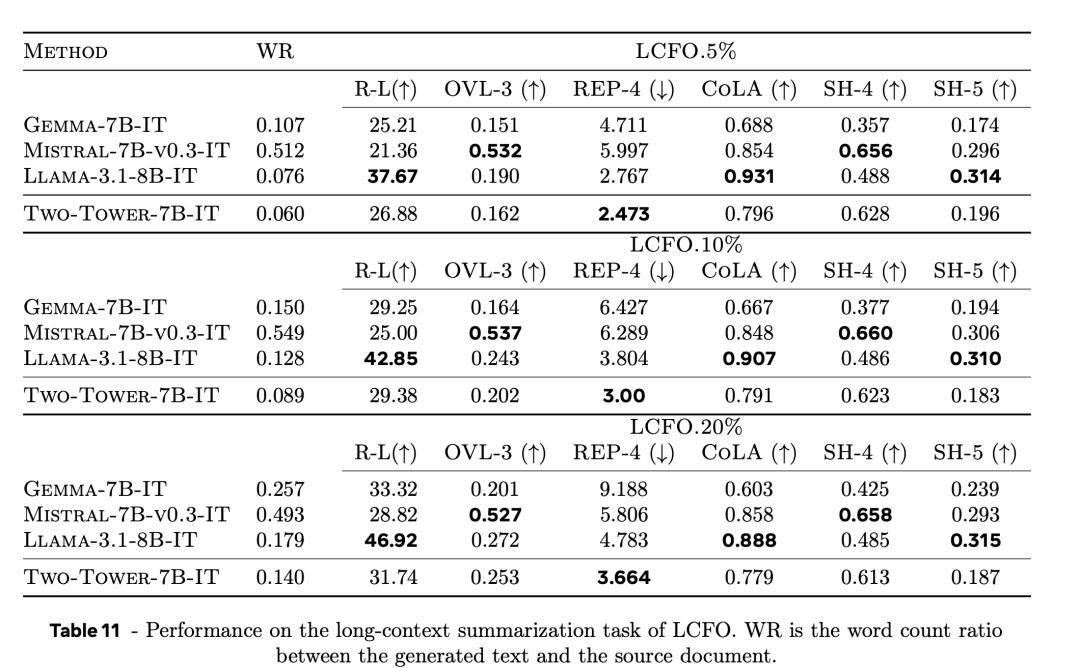
在預訓練和微調數據中,LCM只看到了有限數量的長文檔。
不過,它在這項任務中表現良好。
在5%和10%的條件下,它在Rouge-L指標上優於Mistral-7B-v0.3-IT和Gemma-7B-IT。
在5%和10%條件下的度量Rouge-L優於Mistral-7B-v0.3-IT和Gemma-7B-IT,在 20%條件下接近Gemma-7B-IT 。
還觀察到,LCM在所有條件下都能獲得較高的SH-5分數,也就是說,摘要可以歸因於來源。
LCM的擴寫
摘要擴展是說在給定摘要的情況下,創建更長的文本,其目標並不是重新創建初始文檔的事實信息,而是評估模型以有意義和流暢的方式擴展輸入文本的能力。
當考慮到簡明扼要的文件具有摘要類似的屬性(即主要是從細節中抽像出來的獨立文件)時, 摘要擴展任務可以被描述為生成一個更長的文檔的行為,該文檔保留了相應短文檔中的基本要素以及連接這些要素的邏輯結構。
由於這是一項更加自由的生成任務,因此還需要考慮到連貫性要求(例如,生成的一個句子中包含的詳細信息不應與另一個句子中包含的信息相矛盾)。
這裏介紹的摘要擴展任務包括將來自CNN DailyMail和XSum的摘要作為輸入,並生成一份長文檔。
表12顯示了CNN DailyMail和XSum的摘要擴展結果。
 圖中,加黑加粗的表示最佳的結果。
圖中,加黑加粗的表示最佳的結果。 零樣本(zero-shot)泛化能力
使用XLSum語料庫測試新模型的泛化能力。
XLSum語料庫是涵蓋45種語言的大規模多語言抽像新聞摘要基準。
文中將LCM的性能與支持八種語言的Llama-3.1-8B-IT進行了比較:英語、德語、法語、意大利語、葡萄牙語、印地語、西班牙語和泰語。
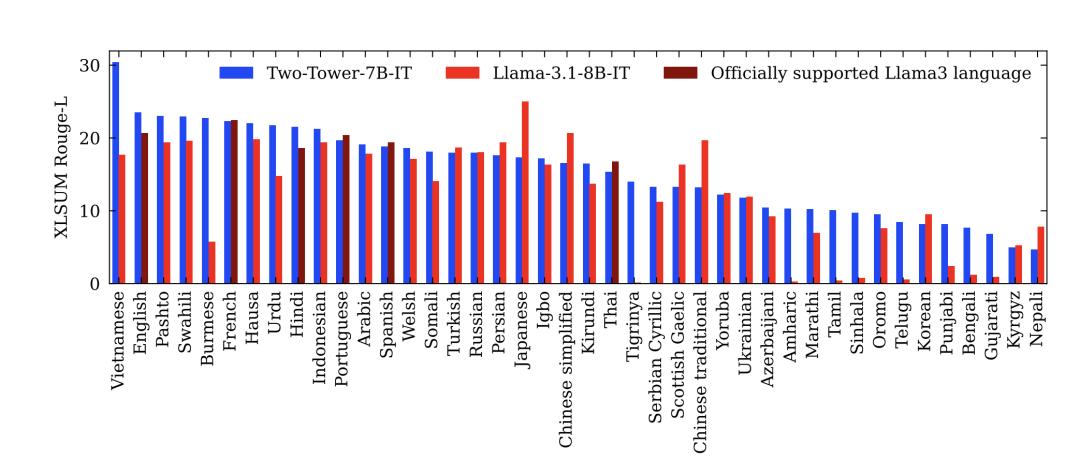
作者在圖 16 中報告了42種語言的Rouge-L分數。排除了SONAR目前不支持的三種語言:Pidgin、拉丁字母塞爾維亞語和西里爾字母烏茲別克語。
在英語方面,LCM大大優於Llama-3.1-8B-IT。
LCM可以很好地推廣到許多其他語言,特別是像南普什圖語、緬甸語、豪薩語或韋爾什語這樣的低資源語言,它們的Rouge-L分數都大於20。
其他表現良好的低資源語言還有索馬里語、伊博語或基隆迪語。
最後,LCM的越南語Rouge-L得分為30.4。
總之,這些結果凸顯了LCM對其從未見過的語言的令人印象深刻的零樣本(zero-shot)泛化性能。
總結
此外,文章也描述了顯式規劃、方法論、相關方法以及模型限制等。
文章討論的模型和結果是朝著提高科學多樣性邁出的一步,也是對當前大規模語言建模最佳實踐的一種超越。
作者也承認,要達到當前最強的LLM的性能,還有很長的路要走。
參考資料:
https://x.com/Yuchenj_UW/status/1871274230383591749
https://x.com/kimmonismus/status/1871291589672550865
https://x.com/AIatMeta/status/1871263650935365759
https://arxiv.org/pdf/2412.08821
本文來自微信公眾號「新智元」,編輯:KingHZ ,36氪經授權發佈。